
fastparquet Python (jak to działa dla programistów)
fastparquet to biblioteka w języku Python przeznaczona do obsługi formatu plików Parquet, który jest powszechnie stosowany w procesach przetwarzania dużych zbiorów danych. Dobrze integruje się z innymi narzędziami do przetwarzania danych opartymi na Pythonie, takimi jak Dask i Pandas. Przyjrzyjmy się jego funkcjom i zobaczmy kilka przykładów kodu. W dalszej części tego artykułu dowiemy się również o IronPDF, bibliotece do generowania plików PDF firmy Iron Software.
Przegląd fastparquet
fastparquet jest wydajny i obsługuje szeroki zakres funkcji Parquet. Niektóre z jego kluczowych funkcji to:
Odczytywanie i zapisywanie plików Parquet
Łatwe odczytywanie i zapisywanie plików Parquet oraz innych plików danych.
Integracja z Pandas i Dask
Płynna współpraca z Pandas DataFrames i Dask w celu przetwarzania równoległego.
Obsługa kompresji
Obsługuje różne algorytmy kompresji, takie jak gzip, snappy, brotli, lz4 i zstandard w plikach danych.
Wydajne przechowywanie danych
Zoptymalizowany zarówno do przechowywania, jak i pobierania dużych zbiorów danych lub plików danych przy użyciu kolumnowego formatu plików Parquet oraz plików metadanych wskazujących na pliki.
Instalacja
Możesz zainstalować fastparquet za pomocą pip:
pip install fastparquetpip install fastparquetLub przy użyciu conda:
conda install -c conda-forge fastparquetconda install -c conda-forge fastparquetPodstawowe zastosowanie
Oto prosty przykład, który pomoże Ci rozpocząć pracę z fastparquet.
Tworzenie pliku Parquet
Można zapisać ramkę danych Pandas do pliku Parquet:
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")Wynik
![]()
Odczytywanie pliku Parquet
Plik Parquet można wczytać do ramki danych Pandas:
import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())Wynik

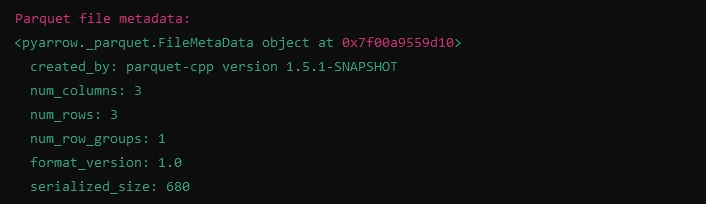
Wyświetlanie metadanych plików Parquet
import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)Wynik
Zaawansowane funkcje
Wykorzystanie Dask do przetwarzania równoległego
fastparquet dobrze integruje się z Dask w celu równoległej obsługi dużych zbiorów danych:
import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)Dostosowywanie kompresji
Podczas zapisywania plików Parquet można określić różne algorytmy kompresji:
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')Przedstawiamy IronPDF
IronPDF to solidna biblioteka w języku Python stworzona do generowania, modyfikowania i cyfrowego podpisywania dokumentów PDF pochodzących z HTML, CSS, obrazów i JavaScript. Wyróżnia się wysoką wydajnością przy minimalnym zużyciu pamięci. Oto jego kluczowe cechy:
1. Konwersja HTML do PDF
Konwertuj pliki HTML, ciągi znaków HTML i adresy URL na dokumenty PDF za pomocą IronPDF. Na przykład, bez wysiłku renderuj strony internetowe do plików PDF za pomocą renderera PDF w przeglądarce Chrome.
2. Obsługa wielu platform
Kompatybilny z Python 3+ na systemach Windows, Mac, Linux oraz różnych platformach chmurowych. IronPDF jest również dostępny dla środowisk .NET, Java, Python i Node.js.
3. Redakcja i podpisanie
Modyfikuj właściwości dokumentów, zwiększaj bezpieczeństwo dzięki ochronie hasłem i uprawnieniom oraz integruj podpisy cyfrowe z plikami PDF za pomocą IronPDF.
4. Szablony stron i ustawienia
Dostosuj pliki PDF za pomocą spersonalizowanych nagłówków, stopek, numerów stron i regulowanych marginesów. Obsługuje responsywne układy i dostosowuje się do niestandardowych rozmiarów papieru.
5. Zgodność z normami
Zgodność ze standardami PDF, takimi jak PDF/A i PDF/UA. Obsługuje kodowanie znaków UTF-8 i efektywnie zarządza zasobami, takimi jak obrazy, arkusze stylów CSS i czcionki.
Generowanie dokumentów PDF przy użyciu IronPDF i fastparquet
Wymagania wstępne dla IronPDF for Python
- IronPDF opiera się na technologii .NET 6.0. Dlatego upewnij się, że w Twoim systemie zainstalowane jest środowisko uruchomieniowe .NET 6.0.
- Python 3.0+: Upewnij się, że masz zainstalowaną wersję Pythona 3 lub nowszą.
- pip: Zainstaluj instalator pakietów Python pip, aby zainstalować pakiet IronPDF.
Instalacja
# Install latest version of the libraries
pip install fastparquet
pip install pandas
pip install ironpdf# Install latest version of the libraries
pip install fastparquet
pip install pandas
pip install ironpdfPrzykład kodu
Poniższy przykład kodu ilustruje wspólne użycie fastparquet i IronPDF w języku Python:
import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
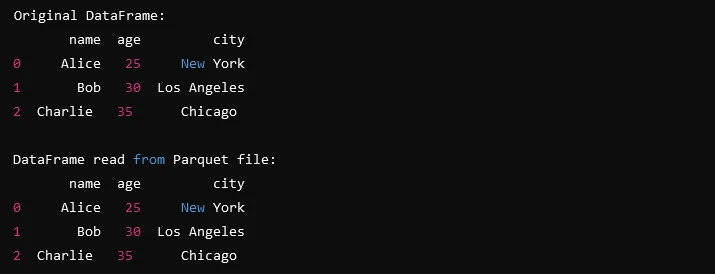
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
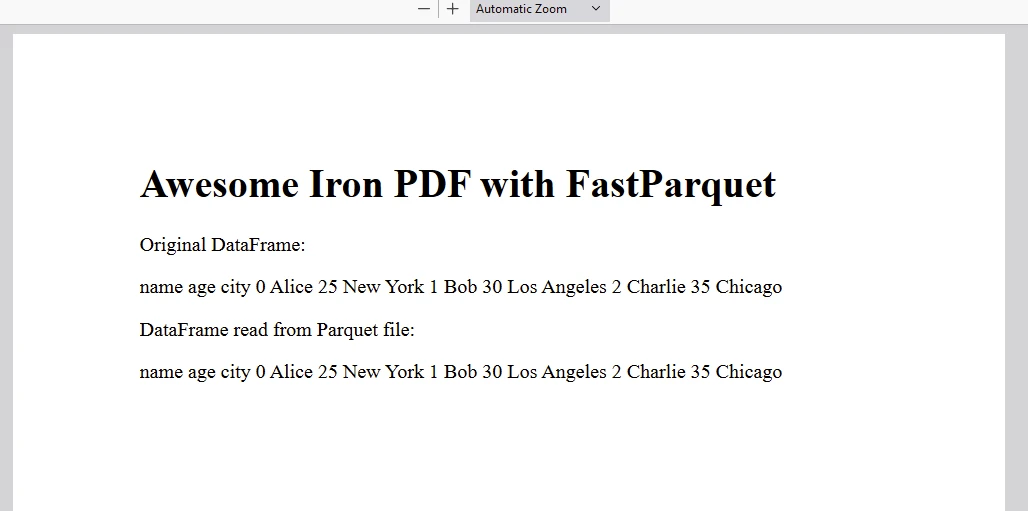
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")Wyjaśnienie kodu
Ten fragment kodu pokazuje, jak wykorzystać kilka bibliotek Pythona do manipulowania danymi i generowania dokumentu PDF na podstawie treści HTML.
Importy i konfiguracja: Zaimportuj niezbędne biblioteki do manipulacji danymi, odczytu i zapisu plików Parquet oraz generowania plików PDF.
Ustawianie klucza licencyjnego: Ustaw klucz licencyjny dla IronPDF, aby odblokować wszystkie jego funkcje.
Tworzenie przykładowej ramki danych: Zdefiniuj przykładową ramkę danych (
df) zawierającą informacje o osobach (imię i nazwisko, wiek, miasto).Zapisywanie DataFrame do pliku Parquet: Zapisz DataFrame
dfdo pliku Parquet o nazwieexample.parquet.Odczyt z pliku Parquet: Odczyt danych z pliku Parquet (
example.parquet) z powrotem do DataFrame (df_read).- Generowanie plików PDF z HTML:
- Zainicjuj instancję ChromePdfRenderer przy użyciu IronPDF.
- Utwórz ciąg znaków HTML (
content), który zawiera nagłówek (<h1>) oraz akapity (<p>) wyświetlające oryginalną ramkę danych (df) oraz ramkę danych odczytaną z pliku Parquet (df_read). - Przekształć zawartość HTML w dokument PDF przy użyciu IronPDF.
- Zapisz wygenerowany dokument PDF jako
Demo-FastParquet.pdf.
Kod przedstawia przykładowy kod dla FastParquet, integrujący możliwości przetwarzania danych z generowaniem plików PDF, co sprawia, że jest on przydatny do tworzenia raportów lub dokumentów na podstawie danych przechowywanych w plikach parquet.
WYNIK
WYJŚCIE PDF
Licencja IronPDF
Informacje na temat licencji można znaleźć na stronie licencyjnej IronPDF.
Umieść klucz licencyjny na początku skryptu przed użyciem pakietu IronPDF:
from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"Wnioski
fastparquet to potężna i wydajna biblioteka do pracy z plikami parquet w języku Python. Dzięki integracji z Pandas i Dask jest to doskonały wybór do obsługi dużych zbiorów danych w opartym na Pythonie przepływie pracy z dużymi zbiorami danych. IronPDF to solidna biblioteka języka Python, która ułatwia tworzenie, edycję i renderowanie dokumentów PDF bezpośrednio z poziomu aplikacji napisanych w języku Python. Ułatwia to takie zadania, jak konwersja treści HTML do dokumentów PDF, tworzenie interaktywnych formularzy oraz wykonywanie różnych operacji na plikach PDF, takich jak scalanie plików lub dodawanie znaków wodnych. IronPDF płynnie integruje się z istniejącymi frameworkami i środowiskami Python, zapewniając programistom wszechstronne rozwiązanie do dynamicznego generowania i dostosowywania dokumentów PDF. W połączeniu z fastparquet, IronPDF umożliwia płynną manipulację danymi w formatach plików parquet oraz generowanie plików PDF.
IronPDF oferuje obszerną dokumentację i przykłady kodu, aby pomóc programistom w jak najlepszym wykorzystaniu jego funkcji. Więcej informacji można znaleźć w dokumentacji i na stronach z przykładami kodu.
















