
Biblioteka Requests w Python: Samouczek
W zróżnicowanym środowisku tworzenia stron internetowych i pobierania danych Python jest wyjątkowym językiem. Jego prostota w połączeniu z potężnymi bibliotekami sprawia, że jest to idealny wybór do obsługi żądań HTTP. Spośród tych bibliotek moduł Python Requests wyróżnia się jako wszechstronne i przyjazne dla użytkownika narzędzie do interakcji z usługami internetowymi.
W tym artykule przyjrzymy się podstawom żądań HTTP i zbadamy, w jaki sposób biblioteka Requests umożliwia programistom Pythona efektywne radzenie sobie z nimi. Przyjrzymy się również, w jaki sposób żądania HTTP mogą być wykorzystywane w połączeniu z biblioteką taką jak IronPDF for Python, co ułatwia tworzenie i edycję plików PDF.
Zrozumienie żądań HTTP
HTTP (Hypertext Transfer Protocol) stanowi podstawę komunikacji danych w sieci WWW. Jest to protokół regulujący transfer hipertekstu, takiego jak HTML, między klientami (przeglądarkami internetowymi) a serwerami. HTTP działa jako protokół żądanie-odpowiedź, w którym klient wysyła żądanie do serwera, a serwer odpowiada, dostarczając żądany zasób.
Żądanie HTTP zazwyczaj składa się z kilku elementów:
- Metoda HTTP: Określa działanie, które klient chce wykonać, aby wysłać żądanie HTTP. Typowe metody to GET, POST, PUT, DELETE itp.
- URL: Uniform Resource Locator, czyli jednolity lokalizator zasobów, który identyfikuje żądany zasób.
- Nagłówki żądania: Dodatkowe informacje wysyłane wraz z żądaniem, takie jak dane uwierzytelniające, typ zawartości itp.
- Treść: Dane wysyłane w żądaniu POST lub PUT.
Przedstawiamy bibliotekę Requests
Biblioteka Requests w języku Python upraszcza proces wysyłania żądań HTTP. Zapewnia elegancki i intuicyjny interfejs API do wysyłania różnego rodzaju żądań i płynnego przetwarzania odpowiedzi.
Przejrzyjmy kilka podstawowych przykładów użycia, ale najpierw przyjrzyjmy się procesowi instalacji modułu Requests.
Instalacja
Przed użyciem biblioteki Requests upewnij się, że jest ona zainstalowana. Można ją zainstalować za pomocą pip:
pip install requestspip install requestsWysyłanie żądania GET
Użyj metody requests.get(), aby wysłać żądanie GET do określonego adresu URL tutaj:
import requests
# Make a GET request to the URL
response = requests.get('https://api.example.com/data')
# Print the response text (content of the response)
print(response.text)import requests
# Make a GET request to the URL
response = requests.get('https://api.example.com/data')
# Print the response text (content of the response)
print(response.text)Ten kod wysyła żądanie GET do podanego adresu URL https://api.example.com/data i PRINTuje treść odpowiedzi.
Wysyłanie żądania POST
Aby wysłać żądania POST z danymi, użyj metody requests.post():
import requests
# Data to send in the POST request
data = {'key': 'value'}
# Make a POST request with data
response = requests.post('https://api.example.com/post', data=data)
# Print the response in JSON format
print(response.json())import requests
# Data to send in the POST request
data = {'key': 'value'}
# Make a POST request with data
response = requests.post('https://api.example.com/post', data=data)
# Print the response in JSON format
print(response.json())W tym przypadku wysyłamy żądanie POST z danymi JSON do https://api.example.com/post i PRINTujemy dane odpowiedzi JSON.
Obsługa obiektu Response
Obiekt odpowiedzi zwracany przez żądanie HTTP udostępnia różne atrybuty i metody umożliwiające dostęp do różnych aspektów odpowiedzi, takich jak nagłówki HTTP, kod statusu, treść itp. Na przykład:
import requests
# Make a GET request
response = requests.get('https://api.example.com/data')
# Print the status code of the response
print(response.status_code)
# Print the response headers
print(response.headers)import requests
# Make a GET request
response = requests.get('https://api.example.com/data')
# Print the status code of the response
print(response.status_code)
# Print the response headers
print(response.headers)Obsługa błędów
Podczas wysyłania żądań HTTP kluczowe znaczenie ma poprawne obsługiwanie błędów. Biblioteka Requests upraszcza obsługę błędów poprzez generowanie wyjątków dla typowych błędów, takich jak błędy połączenia i przekroczenia limitów czasu. Na przykład:
import requests
try:
# Make a GET request
response = requests.get('https://api.example.com/data')
# Raise an exception for HTTP errors
response.raise_for_status()
except requests.exceptions.HTTPError as err:
# Print the error message
print(err)import requests
try:
# Make a GET request
response = requests.get('https://api.example.com/data')
# Raise an exception for HTTP errors
response.raise_for_status()
except requests.exceptions.HTTPError as err:
# Print the error message
print(err)Wyłączanie weryfikacji certyfikatu SSL
W bibliotece requests można wyłączyć weryfikację certyfikatu SSL, ustawiając parametr verify na False w żądaniu:
import requests
# Make a GET request with SSL verification disabled
response = requests.get('https://api.example.com/data', verify=False)
# Process the response
print(response.text)import requests
# Make a GET request with SSL verification disabled
response = requests.get('https://api.example.com/data', verify=False)
# Process the response
print(response.text)Uwzględnienie ciągów zapytania
Możesz również dołączyć parametry zapytania do adresu URL, dodając je za pomocą parametru params:
import requests
# Define query parameters
params = {'key': 'value', 'param2': 'value2'}
# Make a GET request with query parameters
response = requests.get('https://api.example.com/data', params=params)
# Process the response
print(response.text)import requests
# Define query parameters
params = {'key': 'value', 'param2': 'value2'}
# Make a GET request with query parameters
response = requests.get('https://api.example.com/data', params=params)
# Process the response
print(response.text)W tym przykładzie słownik params zawiera parametry zapytania. Podczas wysyłania żądania GET parametry te są automatycznie dołączane do adresu URL, co skutkuje adresem żądania w postaci https://api.example.com/data?key=value¶m2=value2.
Integracja Requests z IronPDF w celu generowania plików PDF
Zanim przejdziemy do realizacji, przyjrzyjmy się pokrótce IronPDF.
IronPDF – biblioteka PDF dla języka Python
IronPDF for Python to popularna biblioteka Pythona służąca do generowania, odczytu, edycji i manipulacji dokumentami PDF. Zapewnia bogaty zestaw funkcji do programowego tworzenia profesjonalnie wyglądających plików PDF.
Aby wygenerować pliki PDF za pomocą IronPDF przy użyciu treści pobranych za pośrednictwem Requests, wykonaj następujące czynności:
Krok 1: Zainstaluj IronPDF
Najpierw upewnij się, że masz zainstalowany IronPDF w swoim środowisku Python. Można ją zainstalować za pomocą pip:
pip install ironpdfpip install ironpdfKrok 2: Pobieranie treści za pomocą żądań
Użyj biblioteki Requests, aby pobrać treść, którą chcesz umieścić w pliku PDF. Na przykład:
import requests
# Make a GET request to fetch data
response = requests.get('https://api.example.com/data')
data = response.textimport requests
# Make a GET request to fetch data
response = requests.get('https://api.example.com/data')
data = response.textKrok 3: Wygeneruj plik PDF za pomocą IronPDF
Po przygotowaniu treści użyj IronPDF do wygenerowania pliku PDF. Oto podstawowy przykład:
from ironpdf import ChromePdfRenderer
# Instantiate Renderer
renderer = ChromePdfRenderer()
# Create a PDF from the data received from requests
pdf = renderer.RenderHtmlAsPdf(data)
# Export to a file
pdf.SaveAs("output.pdf")from ironpdf import ChromePdfRenderer
# Instantiate Renderer
renderer = ChromePdfRenderer()
# Create a PDF from the data received from requests
pdf = renderer.RenderHtmlAsPdf(data)
# Export to a file
pdf.SaveAs("output.pdf")W tym przykładzie data zawiera treść HTML pobraną za pomocą Requests. Metoda RenderHtmlAsPdf() firmy IronPDF konwertuje tę zawartość HTML na dokument PDF. Na koniec plik PDF jest zapisywany przy użyciu metody SaveAs().
Dzięki bibliotece Requests Python sprawia, że interakcja z siecią jest dziecinnie prosta, umożliwiając programistom skupienie się bardziej na tworzeniu świetnych aplikacji niż na radzeniu sobie ze złożonością komunikacji HTTP.
Zaawansowane zastosowania
Możesz jeszcze bardziej usprawnić proces generowania plików PDF, dostosowując ustawienia PDF, marginesy, orientację, obrazy, CSS, JavaScript i inne elementy, korzystając z rozbudowanych możliwości IronPDF. Na przykład:
# Set page margins
renderer.RenderingOptions.MarginTop = 40 # millimeters
renderer.RenderingOptions.MarginLeft = 20 # millimeters
renderer.RenderingOptions.MarginRight = 20 # millimeters
renderer.RenderingOptions.MarginBottom = 40 # millimeters
# Example with HTML Assets
# Load external HTML assets: Images, CSS, and JavaScript.
# An optional BasePath 'C:\\site\\assets\\' is set as the file location to load assets from
my_advanced_pdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
my_advanced_pdf.SaveAs("html-with-assets.pdf")# Set page margins
renderer.RenderingOptions.MarginTop = 40 # millimeters
renderer.RenderingOptions.MarginLeft = 20 # millimeters
renderer.RenderingOptions.MarginRight = 20 # millimeters
renderer.RenderingOptions.MarginBottom = 40 # millimeters
# Example with HTML Assets
# Load external HTML assets: Images, CSS, and JavaScript.
# An optional BasePath 'C:\\site\\assets\\' is set as the file location to load assets from
my_advanced_pdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
my_advanced_pdf.SaveAs("html-with-assets.pdf")W tym miejscu ustawiamy marginesy strony i dodajemy obrazy z katalogu głównego przed zapisaniem jej do pliku.
Aby uzyskać więcej informacji na temat funkcji i możliwości IronPDF, odwiedź stronę dokumentacji i zapoznaj się z gotowymi przykładami kodu do integracji z Pythonem.
Wnioski
Biblioteka Requests w języku Python zapewnia potężny, a jednocześnie prosty interfejs do wysyłania żądań HTTP. Niezależnie od tego, czy pobierasz dane z interfejsów API, korzystasz z usług internetowych, czy też zbierasz dane ze stron internetowych, Requests usprawnia proces wysyłania żądań HTTP dzięki intuicyjnemu interfejsowi API i solidnym funkcjom.
Połączenie IronPDF for Python z biblioteką Requests w Pythonie otwiera szerokie możliwości dynamicznego generowania dokumentów PDF na podstawie pobranych treści. Postępując zgodnie z instrukcjami zawartymi w tym artykule i korzystając z zaawansowanych funkcji zarówno IronPDF, jak i Requests, programiści Pythona mogą usprawnić proces tworzenia plików PDF i generować wysokiej jakości dokumenty dostosowane do ich konkretnych wymagań.
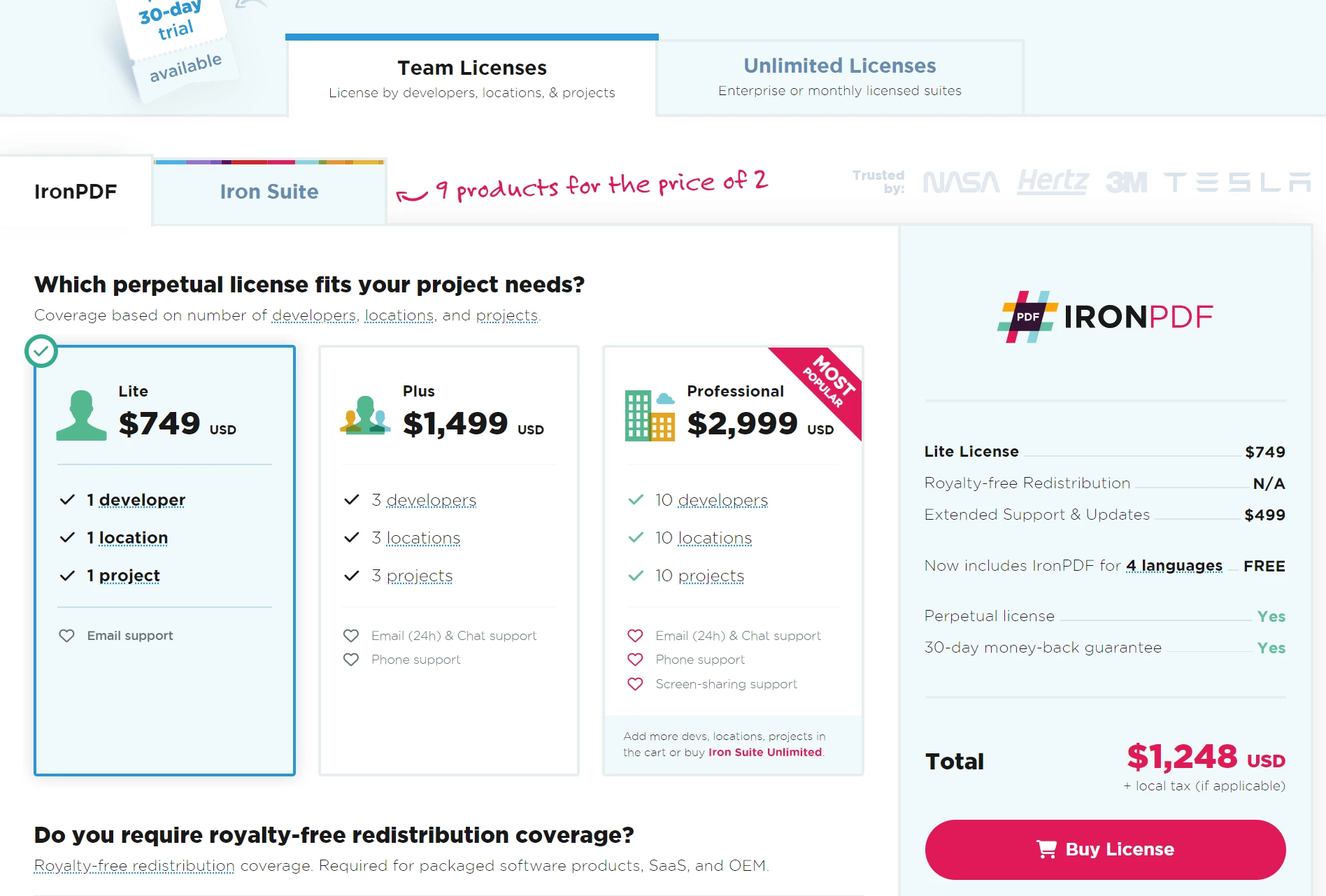
IronPDF jest idealnym rozwiązaniem dla firm. Wypróbuj bezpłatną wersję próbną IronPDF, dostępną od $799. Dzięki gwarancji zwrotu pieniędzy jest to bezpieczny wybór do zarządzania dokumentami. Pobierz IronPDF już teraz i ciesz się płynną integracją z plikami PDF!
















