
Biblioteca Requests em Python: Um Tutorial
No ambiente diversificado de desenvolvimento web e coleta de dados, Python é uma linguagem excepcional. Sua simplicidade, aliada a bibliotecas poderosas, faz dela a escolha ideal para lidar com requisições HTTP. Entre essas bibliotecas, o módulo Python Requests destaca-se como uma ferramenta versátil e fácil de usar para interagir com serviços web.
Neste artigo, veremos os conceitos básicos de solicitações HTTP e exploraremos como a biblioteca Requests capacita desenvolvedores Python a lidar com elas eficientemente. Também vamos analisar como as requisições HTTP podem ser usadas com uma biblioteca como o IronPDF for Python, facilitando a criação e edição de PDFs.
Entendendo as requisições HTTP
O HTTP (Hypertext Transfer Protocol) é a base da comunicação de dados na World Wide Web. É um protocolo que rege a transferência de hipertexto, como HTML, entre clientes (navegadores web) e servidores. O HTTP funciona como um protocolo de solicitação-resposta, onde um cliente envia uma solicitação a um servidor e o servidor responde com o recurso solicitado.
Uma requisição HTTP normalmente consiste em vários componentes:
- Método HTTP: Especifica a ação que o cliente deseja executar ao fazer uma requisição HTTP. Os métodos comuns incluem GET, POST, PUT, DELETE, etc.
- URL: Localizador Uniforme de Recursos, que identifica o recurso que está sendo solicitado.
- Cabeçalhos da solicitação: Informações adicionais enviadas com a solicitação, como credenciais de autenticação, tipo de conteúdo, etc.
- Corpo: Dados enviados com uma solicitação POST ou PUT.
Apresentando a Biblioteca de Pedidos
A biblioteca Requests no Python simplifica o processo de fazer solicitações HTTP. Ela oferece uma API elegante e intuitiva para o envio de diversos tipos de solicitações e o processamento de respostas de forma integrada.
Vamos passar por alguns exemplos básicos de uso, mas primeiro, vamos ver o processo de instalação do módulo Requests.
Instalação
Antes de usar a biblioteca Requests, certifique-se de que ela está instalada. Você pode instalá-lo via pip:
pip install requestspip install requestsFazendo uma solicitação GET
Use o método requests.get() para fazer uma solicitação GET para um URL especificado aqui:
import requests
# Make a GET request to the URL
response = requests.get('https://api.example.com/data')
# Print the response text (content of the response)
print(response.text)import requests
# Make a GET request to the URL
response = requests.get('https://api.example.com/data')
# Print the response text (content of the response)
print(response.text)Este código envia uma solicitação GET para o URL especificado https://api.example.com/data e imprime o corpo da resposta.
Como fazer uma solicitação POST
Para fazer solicitações POST com dados, use o método requests.post():
import requests
# Data to send in the POST request
data = {'key': 'value'}
# Make a POST request with data
response = requests.post('https://api.example.com/post', data=data)
# Print the response in JSON format
print(response.json())import requests
# Data to send in the POST request
data = {'key': 'value'}
# Make a POST request with data
response = requests.post('https://api.example.com/post', data=data)
# Print the response in JSON format
print(response.json())Aqui, estamos enviando uma solicitação POST com dados JSON para https://api.example.com/post e imprimindo os dados da resposta JSON.
Lidando com um objeto de resposta
O objeto de resposta retornado por uma requisição HTTP fornece vários atributos e métodos para acessar diferentes aspectos da resposta, como cabeçalhos HTTP, código de status, conteúdo, etc. Por exemplo:
import requests
# Make a GET request
response = requests.get('https://api.example.com/data')
# Print the status code of the response
print(response.status_code)
# Print the response headers
print(response.headers)import requests
# Make a GET request
response = requests.get('https://api.example.com/data')
# Print the status code of the response
print(response.status_code)
# Print the response headers
print(response.headers)Tratamento de erros
Ao fazer requisições HTTP, é crucial lidar com os erros de forma adequada. A biblioteca Requests simplifica o tratamento de erros, levantando exceções para erros comuns, como erros de conexão e timeouts. Por exemplo:
import requests
try:
# Make a GET request
response = requests.get('https://api.example.com/data')
# Raise an exception for HTTP errors
response.raise_for_status()
except requests.exceptions.HTTPError as err:
# Print the error message
print(err)import requests
try:
# Make a GET request
response = requests.get('https://api.example.com/data')
# Raise an exception for HTTP errors
response.raise_for_status()
except requests.exceptions.HTTPError as err:
# Print the error message
print(err)Desativar a verificação do certificado SSL
Na biblioteca requests, você pode desativar a verificação do certificado SSL configurando o parâmetro verify para False em sua solicitação:
import requests
# Make a GET request with SSL verification disabled
response = requests.get('https://api.example.com/data', verify=False)
# Process the response
print(response.text)import requests
# Make a GET request with SSL verification disabled
response = requests.get('https://api.example.com/data', verify=False)
# Process the response
print(response.text)Incluindo strings de consulta
Você também pode incluir parâmetros de consulta no seu URL anexando-os usando o parâmetro params:
import requests
# Define query parameters
params = {'key': 'value', 'param2': 'value2'}
# Make a GET request with query parameters
response = requests.get('https://api.example.com/data', params=params)
# Process the response
print(response.text)import requests
# Define query parameters
params = {'key': 'value', 'param2': 'value2'}
# Make a GET request with query parameters
response = requests.get('https://api.example.com/data', params=params)
# Process the response
print(response.text)Neste exemplo, o dicionário params contém parâmetros de consulta. Ao fazer a solicitação GET, esses parâmetros são automaticamente anexados ao URL, resultando em um URL de solicitação como https://api.example.com/data?key=value¶m2=value2.
Integrando solicitações com o IronPDF para gerar PDFs
Antes de mergulharmos na implementação, vamos entender brevemente o IronPDF.
IronPDF - A biblioteca PDF em Python
IronPDF for Python é uma biblioteca Python popular para gerar, ler, editar e manipular documentos PDF. Oferece um conjunto abrangente de recursos para a criação programática de PDFs com aparência profissional.
Para gerar PDFs com o IronPDF usando conteúdo obtido via Requests, siga estes passos:
Passo 1: Instale o IronPDF
Primeiro, certifique-se de ter o IronPDF instalado em seu ambiente Python. Você pode instalá-lo via pip:
pip install ironpdf
Etapa 2: Obter conteúdo com solicitações
Utilize a biblioteca Requests para buscar o conteúdo que deseja incluir no PDF. Por exemplo:
import requests
# Make a GET request to fetch data
response = requests.get('https://api.example.com/data')
data = response.textimport requests
# Make a GET request to fetch data
response = requests.get('https://api.example.com/data')
data = response.textPasso 3: Gere o PDF com o IronPDF
Depois de obter o conteúdo, use o IronPDF para gerar o PDF. Eis um exemplo básico:
from ironpdf import ChromePdfRenderer
# Instantiate Renderer
renderer = ChromePdfRenderer()
# Create a PDF from the data received from requests
pdf = renderer.RenderHtmlAsPdf(data)
# Export to a file
pdf.SaveAs("output.pdf")from ironpdf import ChromePdfRenderer
# Instantiate Renderer
renderer = ChromePdfRenderer()
# Create a PDF from the data received from requests
pdf = renderer.RenderHtmlAsPdf(data)
# Export to a file
pdf.SaveAs("output.pdf")Neste exemplo, data contém o conteúdo HTML obtido via Requests. O método RenderHtmlAsPdf() do IronPDF converte este conteúdo HTML em um documento PDF. Finalmente, o PDF é salvo em um arquivo usando o método SaveAs().
Com a biblioteca Requests, o Python torna a interação com a web fácil, permitindo que os desenvolvedores se concentrem mais na criação de excelentes aplicativos ao invés de lidar com as complexidades da comunicação HTTP.
Uso avançado
Você pode aprimorar ainda mais o processo de geração de PDFs personalizando as configurações do PDF, margens, orientação, imagens, CSS, JavaScript e muito mais, utilizando os amplos recursos do IronPDF. Por exemplo:
# Set page margins
renderer.RenderingOptions.MarginTop = 40 # millimeters
renderer.RenderingOptions.MarginLeft = 20 # millimeters
renderer.RenderingOptions.MarginRight = 20 # millimeters
renderer.RenderingOptions.MarginBottom = 40 # millimeters
# Example with HTML Assets
# Load external HTML assets: Images, CSS, and JavaScript.
# An optional BasePath 'C:\\site\\assets\\' is set as the file location to load assets from
my_advanced_pdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
my_advanced_pdf.SaveAs("html-with-assets.pdf")# Set page margins
renderer.RenderingOptions.MarginTop = 40 # millimeters
renderer.RenderingOptions.MarginLeft = 20 # millimeters
renderer.RenderingOptions.MarginRight = 20 # millimeters
renderer.RenderingOptions.MarginBottom = 40 # millimeters
# Example with HTML Assets
# Load external HTML assets: Images, CSS, and JavaScript.
# An optional BasePath 'C:\\site\\assets\\' is set as the file location to load assets from
my_advanced_pdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
my_advanced_pdf.SaveAs("html-with-assets.pdf")Aqui, estamos definindo as margens da página e adicionando imagens do diretório base antes de salvar o arquivo.
Para obter mais informações sobre as funcionalidades e capacidades do IronPDF , visite a página de documentação e consulte estes exemplos de código prontos para uso para integração com Python.
Conclusão
A biblioteca Requests no Python fornece uma interface poderosa, mas simples, para fazer solicitações HTTP. Seja para obter dados de APIs, interagir com serviços web ou extrair informações de páginas da web, o Requests simplifica o processo de requisição HTTP com sua API intuitiva e recursos robustos.
A combinação do IronPDF for Python com o Requests em Python abre um mundo de possibilidades para gerar documentos PDF dinamicamente a partir de conteúdo obtido. Seguindo os passos descritos neste artigo e explorando os recursos avançados do IronPDF e do Requests, os desenvolvedores Python podem otimizar seu fluxo de trabalho de geração de PDFs e produzir documentos de alta qualidade, personalizados para suas necessidades específicas.
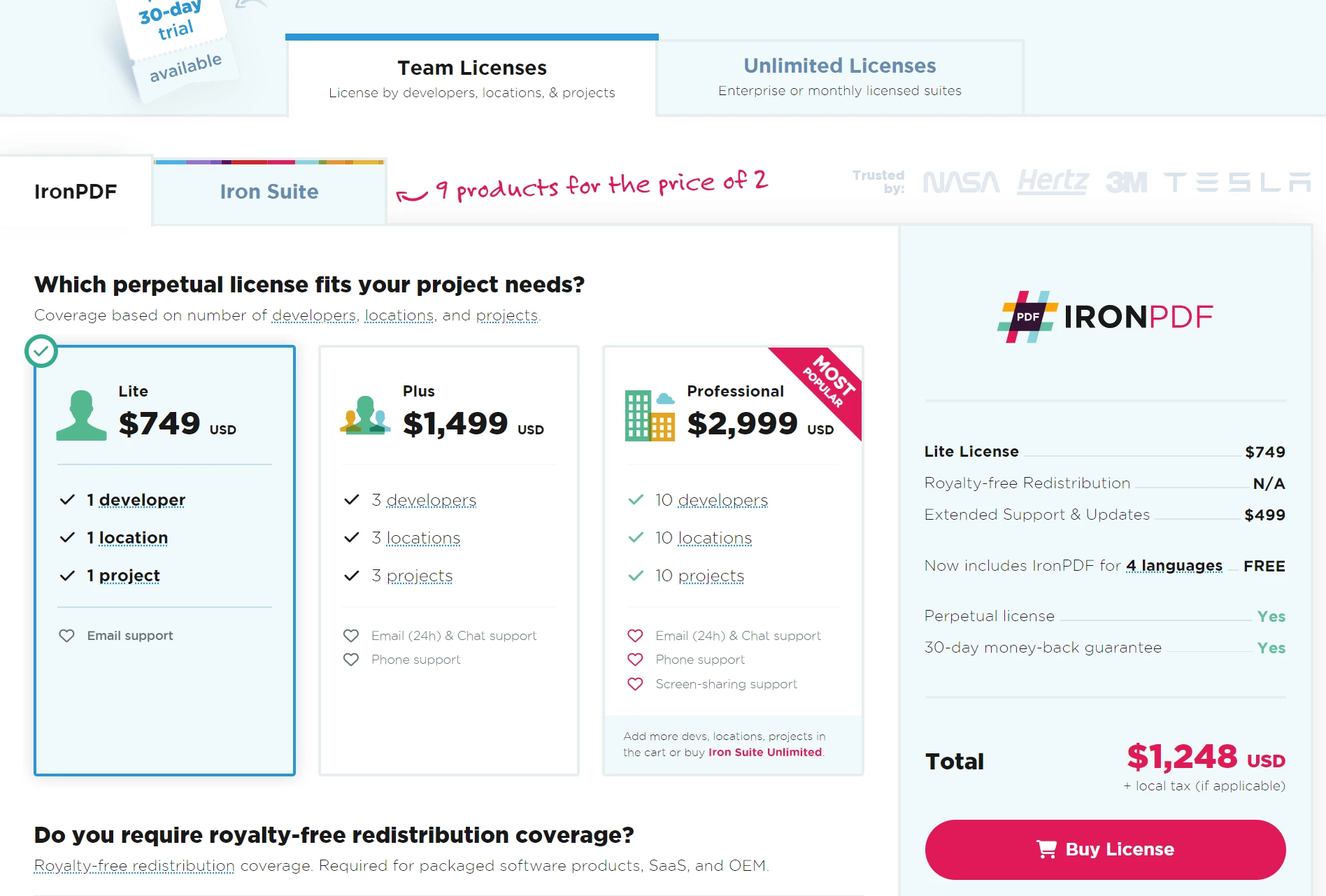
O IronPDF é perfeito para empresas. Experimente o teste gratuito do IronPDF começando em $999 e com garantia de devolução do dinheiro, é uma escolha segura para gerenciar seus documentos. Baixe o IronPDF agora e experimente uma integração perfeita com PDFs!
















