
Używanie WhisperX w Python do transkrypcji
Python ugruntował swoją pozycję jako jeden z najbardziej wszechstronnych i potężnych języków programowania na świecie, głównie dzięki rozbudowanemu ekosystemowi bibliotek i frameworków. Jedną z takich bibliotek, która robi furorę w dziedzinie uczenia maszynowego i przetwarzania języka naturalnego (NLP), jest WhisperX. W tym artykule omówimy, czym jest WhisperX, jakie są jego kluczowe funkcje i jak można go wykorzystać w różnych zastosowaniach. Dodatkowo przedstawimy IronPDF, kolejną potężną bibliotekę Pythona, i pokażemy, jak używać jej razem z WhisperX, podając praktyczny przykład kodu.
Czym jest WhisperX?
WhisperX to zaawansowana biblioteka języka Python przeznaczona do rozpoznawania mowy i zadań z zakresu przetwarzania języka naturalnego (NLP). Wykorzystuje najnowocześniejsze modele uczenia maszynowego do konwersji języka mówionego na tekst pisany z wysoką dokładnością wykrywania języka i precyzyjną transkrypcją mowy. WhisperX jest szczególnie przydatny w aplikacjach, w których tłumaczenie w czasie rzeczywistym ma kluczowe znaczenie, takich jak wirtualni asystenci, zautomatyzowane systemy obsługi klienta i usługi transkrypcji.
Kluczowe cechy WhisperX
- Wysoka dokładność: WhisperX wykorzystuje najnowocześniejsze algorytmy i duże zbiory danych do szkolenia swoich modeli, zapewniając wysoką dokładność rozpoznawania mowy.
- Przetwarzanie w czasie rzeczywistym: Biblioteka jest zoptymalizowana pod kątem przetwarzania w czasie rzeczywistym, co czyni ją idealną dla aplikacji wymagających natychmiastowej transkrypcji i odpowiedzi.
- Obsługa języków: WhisperX obsługuje wiele języków, zaspokajając potrzeby globalnych odbiorców i różnorodnych zastosowań.
- Łatwa integracja: Dzięki dobrze udokumentowanemu API WhisperX można łatwo zintegrować z istniejącymi aplikacjami w języku Python.
- Dostosowanie: Użytkownicy mogą precyzyjnie dostosowywać modele, aby lepiej odpowiadały konkretnym akcentom, dialektom i terminologii.
Pierwsze kroki z WhisperX
Aby rozpocząć korzystanie z WhisperX, należy zainstalować bibliotekę. Można to zrobić za pomocą pip, instalatora pakietów w języku Python. Zakładając, że masz zainstalowany Python i pip, możesz zainstalować WhisperX za pomocą następującego polecenia:
pip install whisperxpip install whisperxPodstawowe zastosowanie WhisperX – szybkie automatyczne rozpoznawanie mowy
Oto podstawowy przykład pokazujący, jak używać WhisperX do transkrypcji plików audio:
import whisperx
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Print the transcription
print("Transcription:", transcription)import whisperx
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Print the transcription
print("Transcription:", transcription)Ten prosty przykład pokazuje, jak zainicjować moduł rozpoznawania WhisperX, załadować plik audio i przeprowadzić transkrypcję w celu przekształcenia wypowiedzianych słów na tekst z wysoką dokładnością.

Zaawansowane funkcje WhisperX
WhisperX oferuje również zaawansowane funkcje, takie jak identyfikacja mówcy, która może mieć kluczowe znaczenie w środowiskach z wieloma mówcami. Oto przykład wykorzystania tej funkcji:
import whisperx
# Initialize the WhisperX recognizer with speaker identification enabled
recognizer = whisperx.Recognizer(speaker_identification=True)
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription with speaker identification
transcription, speakers = recognizer.transcribe(audio_file)
# Print the transcription with speaker labels
for i, segment in enumerate(transcription):
print(f"Speaker {speakers[i]}: {segment}")import whisperx
# Initialize the WhisperX recognizer with speaker identification enabled
recognizer = whisperx.Recognizer(speaker_identification=True)
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription with speaker identification
transcription, speakers = recognizer.transcribe(audio_file)
# Print the transcription with speaker labels
for i, segment in enumerate(transcription):
print(f"Speaker {speakers[i]}: {segment}")W tym przykładzie WhisperX nie tylko transkrybuje audio, ale także identyfikuje różnych mówców, odpowiednio oznaczając każdy segment.
IronPDF for Python
Chociaż WhisperX zajmuje się transkrypcją audio na tekst, często istnieje potrzeba przedstawienia tych danych w uporządkowanym i profesjonalnym formacie. W tym miejscu do gry wkracza IronPDF for Python. IronPDF to solidna biblioteka służąca do programowego generowania, edycji i manipulowania dokumentami PDF. Umożliwia programistom tworzenie plików PDF od podstaw, konwersję HTML do PDF i nie tylko.
Instalacja IronPDF
IronPDF można zainstalować za pomocą pip:
pip install ironpdfpip install ironpdf
Połączenie WhisperX i IronPDF
Stwórzmy teraz praktyczny przykład pokazujący, jak użyć WhisperX do transkrypcji pliku audio, a następnie wykorzystać IronPDF do wygenerowania dokumentu PDF z transkrypcją.
import whisperx
from ironpdf import IronPdf
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Create a PDF document using IronPDF
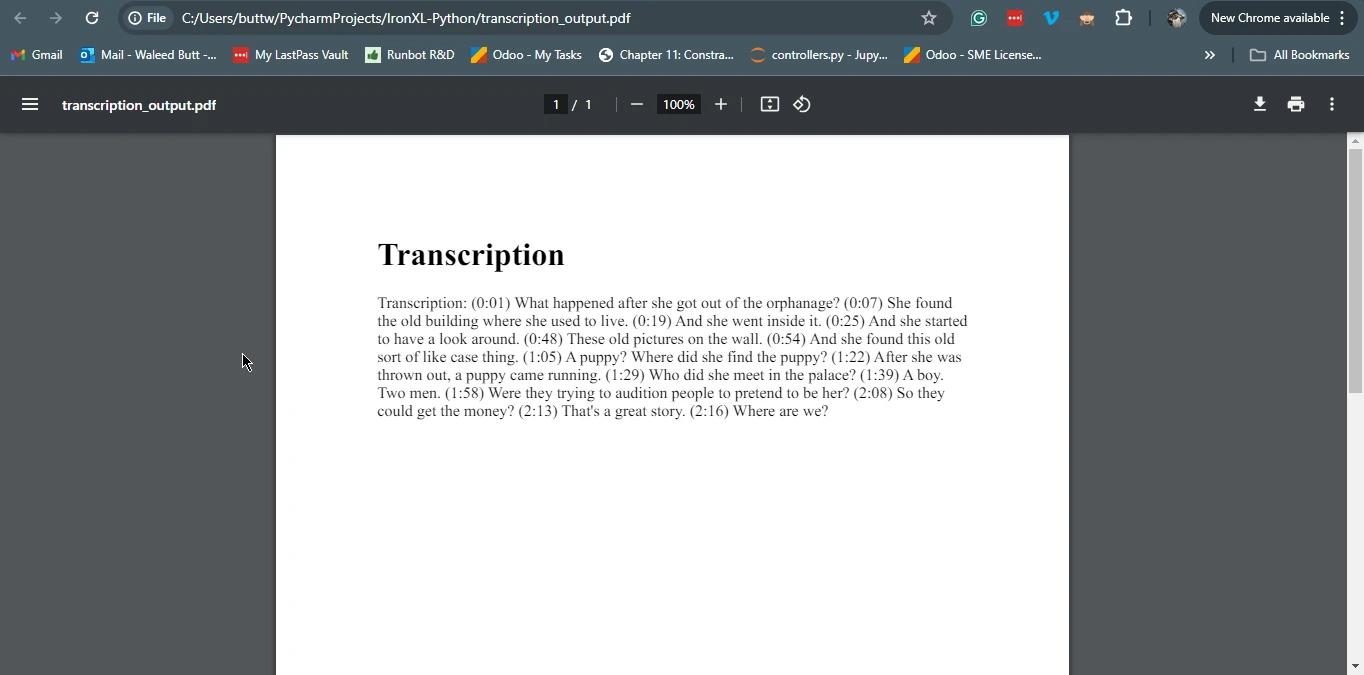
renderer = IronPdf.ChromePdfRenderer()
pdf_from_html = renderer.RenderHtmlAsPdf(f"<h1>Transcription</h1><p>{transcription}</p>")
# Save the PDF to a file
output_file = "transcription_output.pdf"
pdf_from_html.save(output_file)
print(f"Transcription saved to {output_file}")import whisperx
from ironpdf import IronPdf
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Create a PDF document using IronPDF
renderer = IronPdf.ChromePdfRenderer()
pdf_from_html = renderer.RenderHtmlAsPdf(f"<h1>Transcription</h1><p>{transcription}</p>")
# Save the PDF to a file
output_file = "transcription_output.pdf"
pdf_from_html.save(output_file)
print(f"Transcription saved to {output_file}")Objaśnienie połączonego przykładu kodu
Transkrypcja za pomocą WhisperX:
- Zainicjuj moduł rozpoznawania WhisperX i załaduj plik audio.
- Metoda
transcribeprzetwarza plik audio i zwraca transkrypcję.
Tworzenie plików PDF za pomocą IronPDF:
- Utwórz instancję
IronPdf.ChromePdfRenderer. - Korzystając z metody
RenderHtmlAsPdf, dodaj do pliku PDF ciąg znaków w formacie HTML zawierający tekst transkrypcji. - Metoda
savezapisuje plik PDF do pliku.
- Utwórz instancję
Ten połączony przykład pokazuje, jak wykorzystać mocne strony zarówno WhisperX, jak i IronPDF, aby stworzyć kompletne rozwiązanie, które transkrybuje audio i generuje dokument PDF zawierający transkrypcję.
Wnioski
WhisperX to potężne narzędzie dla każdego, kto chce wdrożyć rozpoznawanie mowy, identyfikację mówców i transkrypcję w swoich aplikacjach. Jego wysoka dokładność, możliwości przetwarzania w czasie rzeczywistym oraz obsługa wielu języków sprawiają, że jest to cenny atut w dziedzinie NLP. Z drugiej strony IronPDF oferuje płynny sposób tworzenia i manipulowania dokumentami PDF programowo. Łącząc WhisperX i IronPDF, programiści mogą tworzyć kompleksowe rozwiązania, które nie tylko transkrybują audio, ale także prezentują transkrypcje w dopracowanym, profesjonalnym formacie.
Niezależnie od tego, czy tworzysz wirtualnego asystenta, chatbota do obsługi klienta, czy serwis transkrypcyjny, WhisperX i IronPDF zapewniają narzędzia niezbędne do rozszerzenia możliwości Twojej aplikacji i dostarczenia użytkownikom wysokiej jakości wyników.
Aby uzyskać więcej informacji na temat licencji IronPDF, odwiedź stronę licencji IronPDF. Ponadto dostępny jest nasz szczegółowy samouczek dotyczący konwersji HTML do PDF, który pozwala zgłębić tę tematykę.
















