
Utilizando WhisperX em Python para transcrição
Python consolidou sua posição como uma das linguagens de programação mais versáteis e poderosas do mundo, em grande parte devido ao seu extenso ecossistema de bibliotecas e frameworks. Uma dessas bibliotecas que está causando impacto na área de aprendizado de máquina e processamento de linguagem natural (PLN) é a WhisperX. Neste artigo, exploraremos o que é o WhisperX, suas principais características e como ele pode ser utilizado em diversas aplicações. Além disso, apresentaremos o IronPDF, outra poderosa biblioteca Python, e demonstraremos como usá-la em conjunto com o WhisperX por meio de um exemplo de código prático.
O que é WhisperX?
WhisperX é uma biblioteca Python avançada projetada para tarefas de reconhecimento de fala e PNL (Processamento de Linguagem Natural). Utiliza modelos de aprendizado de máquina de última geração para converter a linguagem falada em texto escrito com alta precisão na detecção do idioma e transcrição de fala com precisão temporal. O WhisperX é particularmente útil em aplicações onde a tradução em tempo real é essencial, como assistentes virtuais, sistemas automatizados de atendimento ao cliente e serviços de transcrição.
Principais características do WhisperX
- Alta precisão: O WhisperX utiliza algoritmos de ponta e grandes conjuntos de dados para treinar seus modelos, garantindo alta precisão no reconhecimento de fala.
- Processamento em Tempo Real: A biblioteca é otimizada para processamento em tempo real, tornando-a ideal para aplicações que exigem transcrição e resposta imediatas.
- Suporte a idiomas: O WhisperX oferece suporte a vários idiomas, atendendo a um público global e a diversos casos de uso.
- Fácil integração: Com sua API bem documentada, o WhisperX pode ser facilmente integrado a aplicativos Python existentes.
- Personalização: Os usuários podem ajustar os modelos para melhor se adequarem a sotaques, dialetos e terminologias específicos.
Primeiros passos com o WhisperX
Para começar a usar o WhisperX, você precisa instalar a biblioteca. Isso pode ser feito via pip, o instalador de pacotes Python. Assumindo que você tenha Python e pip instalado, você pode instalar o WhisperX usando o seguinte comando:
pip install whisperxpip install whisperxUso básico do WhisperX - Reconhecimento automático de fala rápido
Aqui está um exemplo básico demonstrando como usar o WhisperX para transcrever arquivos de áudio:
import whisperx
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Print the transcription
print("Transcription:", transcription)import whisperx
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Print the transcription
print("Transcription:", transcription)Este exemplo simples demonstra como inicializar o reconhecedor WhisperX, carregar áudio e realizar a transcrição para converter palavras faladas em texto com alta precisão.

Recursos avançados do WhisperX
O WhisperX também oferece recursos avançados, como a identificação do falante, que pode ser crucial em ambientes com vários falantes. Aqui está um exemplo de como usar esse recurso:
import whisperx
# Initialize the WhisperX recognizer with speaker identification enabled
recognizer = whisperx.Recognizer(speaker_identification=True)
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription with speaker identification
transcription, speakers = recognizer.transcribe(audio_file)
# Print the transcription with speaker labels
for i, segment in enumerate(transcription):
print(f"Speaker {speakers[i]}: {segment}")import whisperx
# Initialize the WhisperX recognizer with speaker identification enabled
recognizer = whisperx.Recognizer(speaker_identification=True)
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription with speaker identification
transcription, speakers = recognizer.transcribe(audio_file)
# Print the transcription with speaker labels
for i, segment in enumerate(transcription):
print(f"Speaker {speakers[i]}: {segment}")Neste exemplo, o WhisperX não apenas transcreve o áudio, mas também identifica os diferentes falantes, rotulando cada segmento de acordo.
IronPDF for Python
Embora o WhisperX realize a transcrição de áudio para texto, muitas vezes há a necessidade de apresentar esses dados em um formato estruturado e profissional. É aí que entra o IronPDF for Python. IronPDF é uma biblioteca robusta para gerar, editar e manipular documentos PDF programaticamente. Permite aos desenvolvedores gerar PDFs do zero, converter HTML em PDF e muito mais.
Instalando o IronPDF
IronPDF pode ser instalado usando pip:
pip install ironpdf
Combinando WhisperX e IronPDF
Vamos agora criar um exemplo prático que demonstra como usar o WhisperX para transcrever um arquivo de áudio e, em seguida, usar o IronPDF para gerar um documento PDF com a transcrição.
import whisperx
from ironpdf import IronPdf
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Create a PDF document using IronPDF
renderer = IronPdf.ChromePdfRenderer()
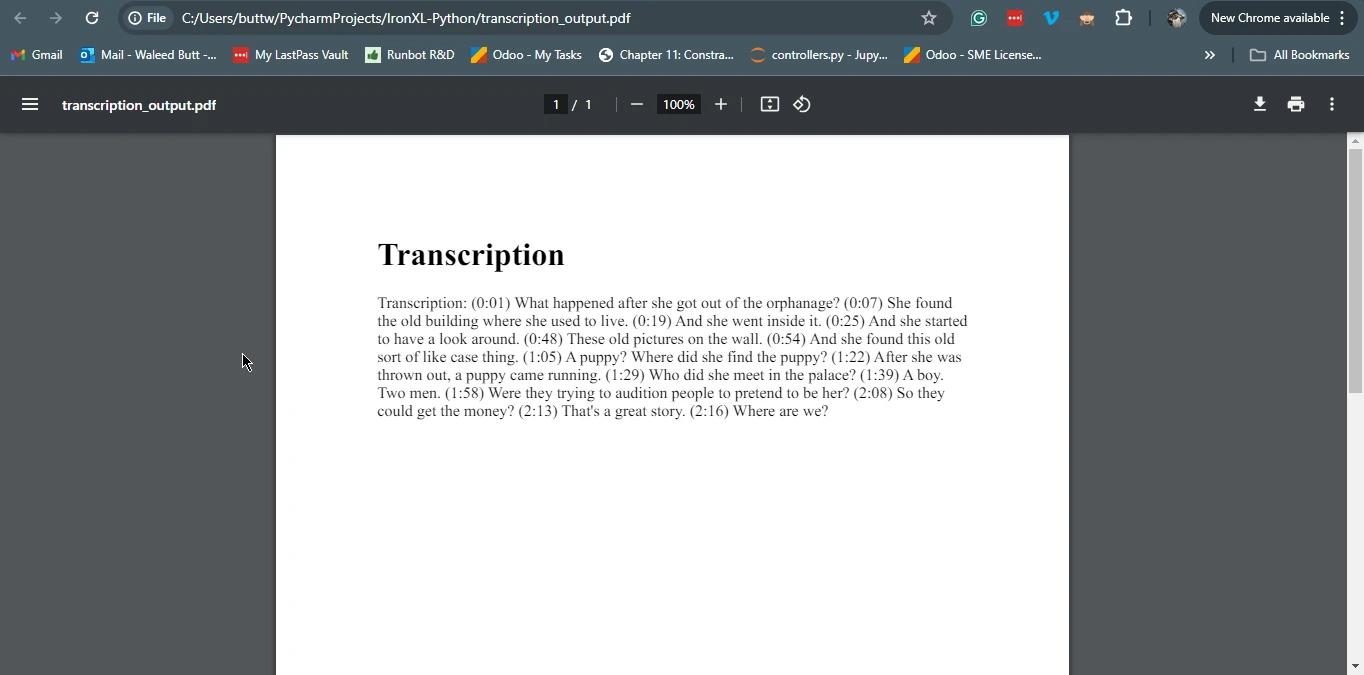
pdf_from_html = renderer.RenderHtmlAsPdf(f"<h1>Transcription</h1><p>{transcription}</p>")
# Save the PDF to a file
output_file = "transcription_output.pdf"
pdf_from_html.save(output_file)
print(f"Transcription saved to {output_file}")import whisperx
from ironpdf import IronPdf
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Create a PDF document using IronPDF
renderer = IronPdf.ChromePdfRenderer()
pdf_from_html = renderer.RenderHtmlAsPdf(f"<h1>Transcription</h1><p>{transcription}</p>")
# Save the PDF to a file
output_file = "transcription_output.pdf"
pdf_from_html.save(output_file)
print(f"Transcription saved to {output_file}")Explicação do exemplo de código combinado
-
Transcrição com WhisperX:
- Inicialize o reconhecedor WhisperX e carregue um arquivo de áudio.
- O método
transcribeprocessa o áudio e retorna a transcrição.
-
Criação de PDFs com o IronPDF:
- Crie uma instância de
IronPdf.ChromePdfRenderer. - Usando o método
RenderHtmlAsPdf, adicione uma string formatada em HTML contendo o texto transcrito ao PDF. - O método
saveescreve o PDF em um arquivo.
- Crie uma instância de
Este exemplo combinado demonstra como aproveitar os pontos fortes do WhisperX e do IronPDF para criar uma solução completa que transcreve áudio e gera um documento PDF contendo a transcrição.
Conclusão
WhisperX é uma ferramenta poderosa para quem busca implementar reconhecimento de fala, diarização de falantes e transcrição em seus aplicativos. Sua alta precisão, capacidade de processamento em tempo real e suporte a múltiplos idiomas fazem dele um recurso valioso na área de PNL (Processamento de Linguagem Natural). Por outro lado, o IronPDF oferece uma maneira simples de criar e manipular documentos PDF programaticamente. Ao combinar WhisperX e IronPDF, os desenvolvedores podem criar soluções abrangentes que não apenas transcrevem áudio, mas também apresentam as transcrições em um formato profissional e refinado.
Seja para criar um assistente virtual, um chatbot de atendimento ao cliente ou um serviço de transcrição, o WhisperX e o IronPDF oferecem as ferramentas necessárias para aprimorar os recursos do seu aplicativo e fornecer resultados de alta qualidade aos seus usuários.
Para obter mais detalhes sobre o licenciamento do IronPDF , visite a página de licenças do IronPDF . Além disso, nosso tutorial detalhado sobre conversão de HTML para PDF está disponível para consulta posterior.
















