
Utilisation de WhisperX en Python pour la transcription
Python a solidifié sa place comme l'un des langages de programmation les plus polyvalents et puissants au monde, en grande partie grâce à son vaste écosystème de bibliothèques et frameworks. Une telle bibliothèque qui fait sensation dans le domaine de l'apprentissage automatique et du traitement du langage naturel (NLP) est WhisperX. Dans cet article, nous allons explorer ce qu'est WhisperX, ses principales caractéristiques, et comment il peut être utilisé dans diverses applications. De plus, nous présenterons IronPDF, une autre bibliothèque Python puissante, et démontrerons comment l'utiliser avec WhisperX à travers un exemple de code pratique.
Qu'est-ce que WhisperX ?
WhisperX est une bibliothèque Python avancée conçue pour la reconnaissance vocale et les tâches NLP. Il exploite des modèles d'apprentissage automatique à la pointe de la technologie pour convertir le langage parlé en texte écrit avec une détection de langue et une transcription vocale précises. WhisperX est particulièrement utile dans les applications où la traduction en temps réel est cruciale, telles que les assistants virtuels, les systèmes de service client automatisés et les services de transcription.
Caractéristiques clés de WhisperX
- Haute précision : WhisperX utilise des algorithmes de pointe et de vastes ensembles de données pour entraîner ses modèles, garantissant une haute précision dans la reconnaissance vocale.
- Traitement en temps réel : La bibliothèque est optimisée pour le traitement en temps réel, ce qui la rend idéale pour les applications nécessitant une transcription et une réponse immédiates.
- Prise en charge des langues : WhisperX prend en charge plusieurs langues, répondant ainsi aux besoins d'un public mondial et de cas d'utilisation diversifiés.
- Intégration facile : grâce à son API bien documentée, WhisperX peut être facilement intégré aux applications Python existantes.
- Personnalisation : Les utilisateurs peuvent affiner les modèles pour mieux les adapter à des accents, des dialectes et des terminologies spécifiques.
Commencer avec WhisperX
Pour commencer à utiliser WhisperX, vous devez installer la bibliothèque. Cela peut être fait via pip, l'installateur de paquets Python. Si vous avez installé Python et pip, vous pouvez installer WhisperX à l'aide de la commande suivante :
pip install whisperxpip install whisperxUtilisation de base de WhisperX - Reconnaissance Vocale Automatique Rapide
Voici un exemple de base démontrant comment utiliser WhisperX pour transcrire des fichiers audio :
import whisperx
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Print the transcription
print("Transcription:", transcription)import whisperx
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Print the transcription
print("Transcription:", transcription)Cet exemple simple montre comment initialiser le reconnaisseur WhisperX, charger l'audio et effectuer la transcription pour convertir les mots parlés en texte avec une haute précision.

Fonctions Avancées de WhisperX
WhisperX offre également des fonctionnalités avancées telles que l'identification des locuteurs, ce qui peut être crucial dans les environnements à plusieurs locuteurs. Voici un exemple de comment utiliser cette fonctionnalité :
import whisperx
# Initialize the WhisperX recognizer with speaker identification enabled
recognizer = whisperx.Recognizer(speaker_identification=True)
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription with speaker identification
transcription, speakers = recognizer.transcribe(audio_file)
# Print the transcription with speaker labels
for i, segment in enumerate(transcription):
print(f"Speaker {speakers[i]}: {segment}")import whisperx
# Initialize the WhisperX recognizer with speaker identification enabled
recognizer = whisperx.Recognizer(speaker_identification=True)
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription with speaker identification
transcription, speakers = recognizer.transcribe(audio_file)
# Print the transcription with speaker labels
for i, segment in enumerate(transcription):
print(f"Speaker {speakers[i]}: {segment}")Dans cet exemple, WhisperX ne se contente pas de transcrire l'audio mais identifie également les différents locuteurs, étiquetant chaque segment en conséquence.
IronPDF for Python
Bien que WhisperX gère la transcription de l'audio en texte, il est souvent nécessaire de présenter ces données dans un format structuré et professionnel. C'est là qu'IronPDF for Python entre en jeu. IronPDF est une bibliothèque robuste pour générer, éditer et manipuler des documents PDF de manière programmatique. Elle permet aux développeurs de générer des PDFs à partir de zéro, de convertir du HTML en PDF, et plus encore.
Installer IronPDF
IronPDF peut être installé en utilisant pip :
pip install ironpdfpip install ironpdf
Combinaison de WhisperX et d'IronPDF
Créons maintenant un exemple pratique qui démontre comment utiliser WhisperX pour transcrire un fichier audio puis utiliser IronPDF pour générer un document PDF avec la transcription.
import whisperx
from ironpdf import IronPdf
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Create a PDF document using IronPDF
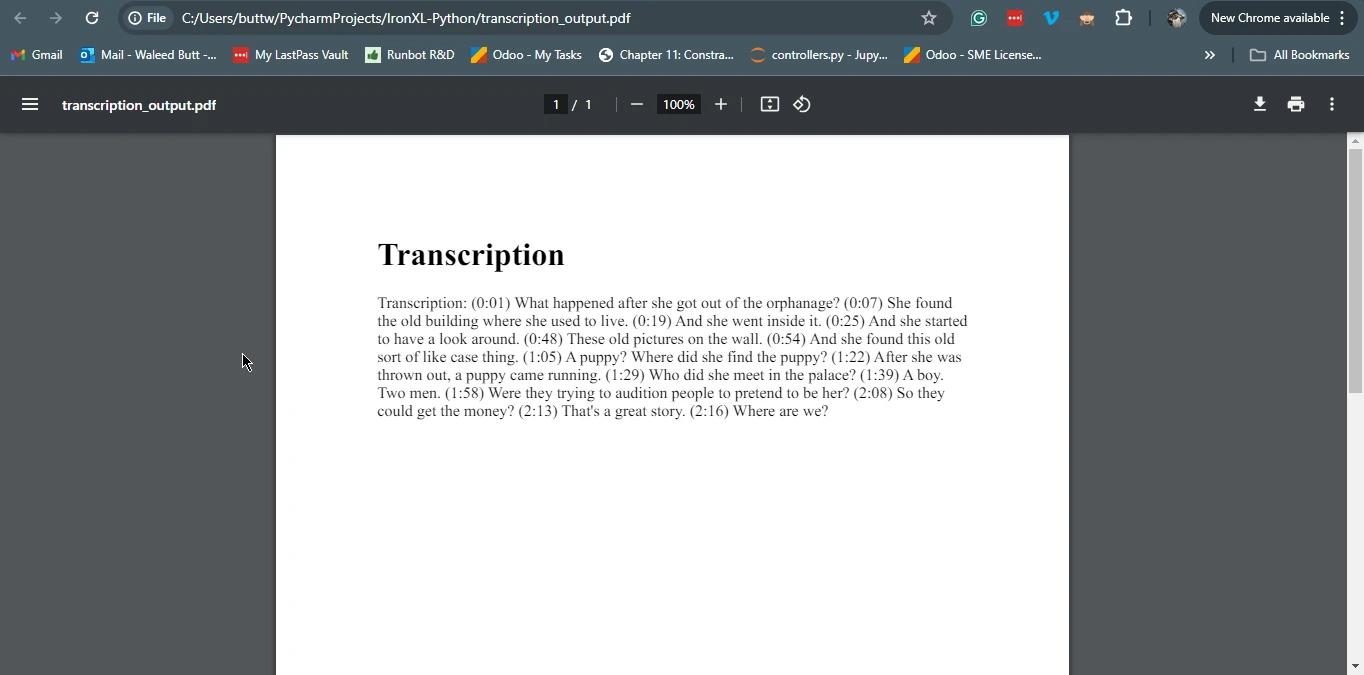
renderer = IronPdf.ChromePdfRenderer()
pdf_from_html = renderer.RenderHtmlAsPdf(f"<h1>Transcription</h1><p>{transcription}</p>")
# Save the PDF to a file
output_file = "transcription_output.pdf"
pdf_from_html.save(output_file)
print(f"Transcription saved to {output_file}")import whisperx
from ironpdf import IronPdf
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Create a PDF document using IronPDF
renderer = IronPdf.ChromePdfRenderer()
pdf_from_html = renderer.RenderHtmlAsPdf(f"<h1>Transcription</h1><p>{transcription}</p>")
# Save the PDF to a file
output_file = "transcription_output.pdf"
pdf_from_html.save(output_file)
print(f"Transcription saved to {output_file}")Explication de l'exemple de code combiné
-
Transcription avec WhisperX :
- Initialisez le reconnaisseur WhisperX et chargez un fichier audio.
- La méthode
transcribetraite l'audio et renvoie la transcription.
-
Création de PDF avec IronPDF:
- Créez une instance de
IronPdf.ChromePdfRenderer. - En utilisant la méthode
RenderHtmlAsPdf, ajoutez une chaîne au format HTML contenant le texte de la transcription au PDF. - La méthode
saveécrit le PDF dans un fichier.
- Créez une instance de
Cet exemple combiné montre comment tirer parti des forces de WhisperX et d'IronPDF pour créer une solution complète qui transcrit l'audio et génère un document PDF contenant la transcription.
Conclusion
WhisperX est un outil puissant pour quiconque cherche à implémenter la reconnaissance de parole, la diarisation des locuteurs et la transcription dans leurs applications. Sa haute précision, ses capacités de traitement en temps réel et sa prise en charge de plusieurs langues en font un atout précieux dans le domaine du NLP. D'autre part, IronPDF offre un moyen sans faille de créer et manipuler des documents PDF de façon programmatique. En combinant WhisperX et IronPDF, les développeurs peuvent créer des solutions complètes qui non seulement transcrivent l'audio mais présentent également les transcriptions dans un format poli et professionnel.
Que vous construisiez un assistant virtuel, un chatbot de service client ou un service de transcription, WhisperX et IronPDF fournissent les outils nécessaires pour améliorer les capacités de votre application et offrir des résultats de haute qualité à vos utilisateurs.
Pour obtenir plus de détails sur la licence d'IronPDF, visitez la page de licence d'IronPDF. En outre, notre tutoriel détaillé sur la conversion HTML en PDF est disponible pour une exploration plus approfondie.
















