
Analizowanie XML w Python z ElementTree
XML (eXtensible Markup Language) to popularny i elastyczny format służący do przedstawiania danych strukturalnych w przetwarzaniu danych i generowaniu dokumentów. Standardowa biblioteka języka Python zawiera xml.etree, bibliotekę, która zapewnia programistom potężny zestaw narzędzi do analizowania lub tworzenia danych XML, manipulowania elementami podrzędnymi oraz generowania dokumentów XML programowo.
W połączeniu z IronPDF, biblioteką .NET do tworzenia i edycji dokumentów PDF, programiści mogą przyspieszyć przetwarzanie danych obiektów elementów XML oraz dynamiczne generowanie dokumentów PDF. W tym szczegółowym przewodniku zagłębimy się w xml.etree języka Python, omówimy jego główne cechy i funkcje oraz pokażemy, jak zintegrować go z IronPDF, aby odkryć nowe możliwości przetwarzania danych.
Czym jest xml.etree?
xml.etree jest częścią standardowej biblioteki języka Python. Posiada rozszerzenie .etree, znane również jako ElementTree, które oferuje proste i skuteczne API XML do przetwarzania i modyfikowania dokumentów XML. Umożliwia programistom interakcję z danymi XML w hierarchicznej strukturze drzewa, upraszczając nawigację, modyfikację i programowe generowanie plików XML.
Mimo że jest lekki i prosty w użyciu, xml.etree oferuje rozbudowaną funkcjonalność do obsługi danych elementu głównego XML. Umożliwia analizowanie dokumentów danych XML z plików, ciągów znaków lub obiektów podobnych do plików. Wynikowy, przeanalizowany plik XML jest wyświetlany jako drzewo obiektów Element. Programiści mogą poruszać się po tym drzewie, uzyskiwać dostęp do elementów i atrybutów oraz wykonywać różne czynności, takie jak edycja, usuwanie lub dodawanie elementów.

Funkcje xml.etree
Analiza dokumentów XML
Metody analizowania dokumentów XML z ciągów znaków, plików lub obiektów podobnych do plików są dostępne w xml.etree. Materiały XML można przetwarzać za pomocą funkcji parse(), która generuje również obiekt ElementTree reprezentujący przeanalizowany dokument XML z prawidłowym obiektem elementu.
Poruszanie się po drzewach XML
Programiści mogą używać xml.etree do przeglądania elementów drzewa deklaracji XML za pomocą funkcji takich jak find(), findall() i iter() po przetworzeniu dokumentu. Dzięki tym podejściom uzyskanie dostępu do określonych elementów na podstawie tagów, atrybutów lub wyrażeń XPath jest proste.
Modyfikowanie dokumentów XML
W dokumencie XML istnieją sposoby dodawania, edytowania i usuwania komponentów oraz atrybutów przy użyciu xml.etree. Programowa zmiana struktury i zawartości drzewa XML, które z natury ma hierarchiczny format danych, umożliwia modyfikację, aktualizację i przekształcanie danych.
Serializacja dokumentów XML
xml.etree umożliwia serializację drzew XML do ciągów znaków lub obiektów typu plik przy użyciu funkcji takich jak ElementTree.write() po zmodyfikowaniu dokumentu XML. Umożliwia to programistom tworzenie lub modyfikowanie drzew XML oraz generowanie na ich podstawie danych wyjściowych w formacie XML.
Obsługa XPath
Obsługa XPath, języka zapytań służącego do wybierania węzłów z dokumentu XML, jest zapewniona przez xml.etree. Programiści mogą wykonywać zaawansowane operacje pobierania i manipulacji danymi, używając wyrażeń XPath do wyszukiwania i filtrowania elementów w drzewie XML.
Parsowanie iteracyjne
Zamiast ładować cały dokument do pamięci naraz, programiści mogą obsługiwać dokumenty XML sekwencyjnie dzięki obsłudze iteracyjnego parsowania przez xml.etree. Jest to bardzo pomocne w efektywnym zarządzaniu dużymi plikami XML.
Obsługa przestrzeni nazw
Programiści mogą pracować z dokumentami XML, które wykorzystują przestrzenie nazw do identyfikacji elementów i atrybutów, korzystając z obsługi przestrzeni nazw XML w xml.etree. Zapewnia sposoby rozwiązywania domyślnych prefiksów przestrzeni nazw XML oraz określania przestrzeni nazw wewnątrz dokumentu XML.
Obsługa błędów
Funkcje obsługi błędów dla nieprawidłowych dokumentów XML i błędów parsowania są zawarte w xml.etree. Oferuje techniki zarządzania błędami i ich przechwytywania, gwarantując niezawodność i solidność podczas pracy z danymi XML.
Kompatybilność i przenośność
Ponieważ xml.etree jest składnikiem standardowej biblioteki języka Python, można go używać od razu w programach napisanych w tym języku bez konieczności dodatkowej instalacji. Jest przenośny i kompatybilny z wieloma środowiskami Pythona, ponieważ działa zarówno z Pythonem 2, jak i Pythonem 3.
Utwórz i skonfiguruj plik xml.etree
Utwórz dokument XML
Tworząc obiekty reprezentujące elementy drzewa XML i dołączając je do elementu głównego, można wygenerować dokument XML. Oto przykład tworzenia danych XML:
import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Create a book element as a child of the root
book1 = ET.SubElement(root, "book")
book1.set("id", "1")
# Add child elements to the book
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Create another book element
book2 = ET.SubElement(root, "book")
book2.set("id", "2")
# Add child elements to the second book
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create an ElementTree object from the root element
tree = ET.ElementTree(root)import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Create a book element as a child of the root
book1 = ET.SubElement(root, "book")
book1.set("id", "1")
# Add child elements to the book
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Create another book element
book2 = ET.SubElement(root, "book")
book2.set("id", "2")
# Add child elements to the second book
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create an ElementTree object from the root element
tree = ET.ElementTree(root)Zapisanie dokumentu XML do pliku
Do napisania pliku XML można użyć funkcji write() obiektu ElementTree:
# Write XML document to file
tree.write("catalog.xml")# Write XML document to file
tree.write("catalog.xml")Spowoduje to utworzenie dokumentu XML w pliku o nazwie "catalog.xml".
Analiza dokumentu XML
ElementTree analizuje dane XML za pomocą funkcji parse():
# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()Spowoduje to przeanalizowanie dokumentu XML "catalog.xml", zwracając element główny drzewa XML.
Elementy i atrybuty dostępu
Korzystając z różnych metod i właściwości oferowanych przez obiekty Element, można uzyskać dostęp do elementów i atrybutów dokumentu XML. Na przykład, aby wyświetlić tytuł pierwszej książki:
# Access the title of the first book
first_book_title = root[0].find("title").text
print("Title of the first book:", first_book_title)# Access the title of the first book
first_book_title = root[0].find("title").text
print("Title of the first book:", first_book_title)Modyfikacja dokumentu XML
Dokument XML można modyfikować poprzez dodawanie, zmianę lub usuwanie komponentów i atrybutów. Aby na przykład zmienić autora drugiej książki:
# Modify the author of the second book
root[1].find("author").text = "Alice Smith"# Modify the author of the second book
root[1].find("author").text = "Alice Smith"Serializacja dokumentu XML
Funkcja tostring() z modułu ElementTree może służyć do serializacji dokumentu XML do postaci ciągu znaków:
# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)Pierwsze kroki z IronPDF
Czym jest IronPDF?
IronPDF to potężna biblioteka .NET do programowego tworzenia, edytowania i modyfikowania dokumentów PDF w językach C#, VB.NET i innych językach .NET. Zapewnia programistom kompleksowy zestaw funkcji do dynamicznego tworzenia wysokiej jakości plików PDF, co sprawia, że jest popularnym wyborem dla wielu aplikacji.
Najważniejsze funkcje IronPDF
Generowanie plików PDF: Korzystając z IronPDF, programiści mogą tworzyć nowe dokumenty PDF lub konwertować istniejące tagi HTML, tekst, obrazy i inne formaty plików do formatu PDF. Ta funkcja jest bardzo przydatna do dynamicznego tworzenia raportów, faktur, paragonów i innych dokumentów.
Konwersja HTML do PDF: IronPDF ułatwia programistom przekształcanie dokumentów HTML, w tym stylów z JavaScript i CSS, w pliki PDF. Umożliwia to tworzenie plików PDF ze stron internetowych, treści generowanych dynamicznie oraz szablonów HTML.
Modyfikacja i edycja dokumentów PDF: IronPDF zapewnia kompleksowy zestaw funkcji do modyfikowania i zmieniania istniejących dokumentów PDF. Programiści mogą łączyć kilka plików PDF, dzielić je na inne dokumenty, usuwać strony oraz dodawać zakładki, adnotacje i znaki wodne, a także korzystać z innych funkcji, aby dostosować pliki PDF do swoich potrzeb.
IronPDF i xml.etree połączone
W tej sekcji zostanie pokazane, jak generować dokumenty PDF za pomocą IronPDF na podstawie przeanalizowanych danych XML. Wykorzystując zalety zarówno XML, jak i IronPDF, można efektywnie przekształcać dane strukturalne w profesjonalne dokumenty PDF. Oto szczegółowy przewodnik:
Instalacja
Przed rozpoczęciem upewnij się, że masz zainstalowany IronPDF. Można ją zainstalować za pomocą pip:
pip install ironpdf
Generowanie dokumentu PDF za pomocą IronPDF przy użyciu przeanalizowanego XML
IronPDF może służyć do tworzenia dokumentów PDF na podstawie danych wyodrębnionych z XML po ich przetworzeniu. Stwórzmy dokument PDF z tabelą zawierającą tytuły książek i nazwiska autorów:
from ironpdf import *
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Loop through books to add each to the table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
html_content += """
</table>
</body>
</html>
"""
# Generate PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
pdf.SaveAs("books.pdf")from ironpdf import *
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Loop through books to add each to the table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
html_content += """
</table>
</body>
</html>
"""
# Generate PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
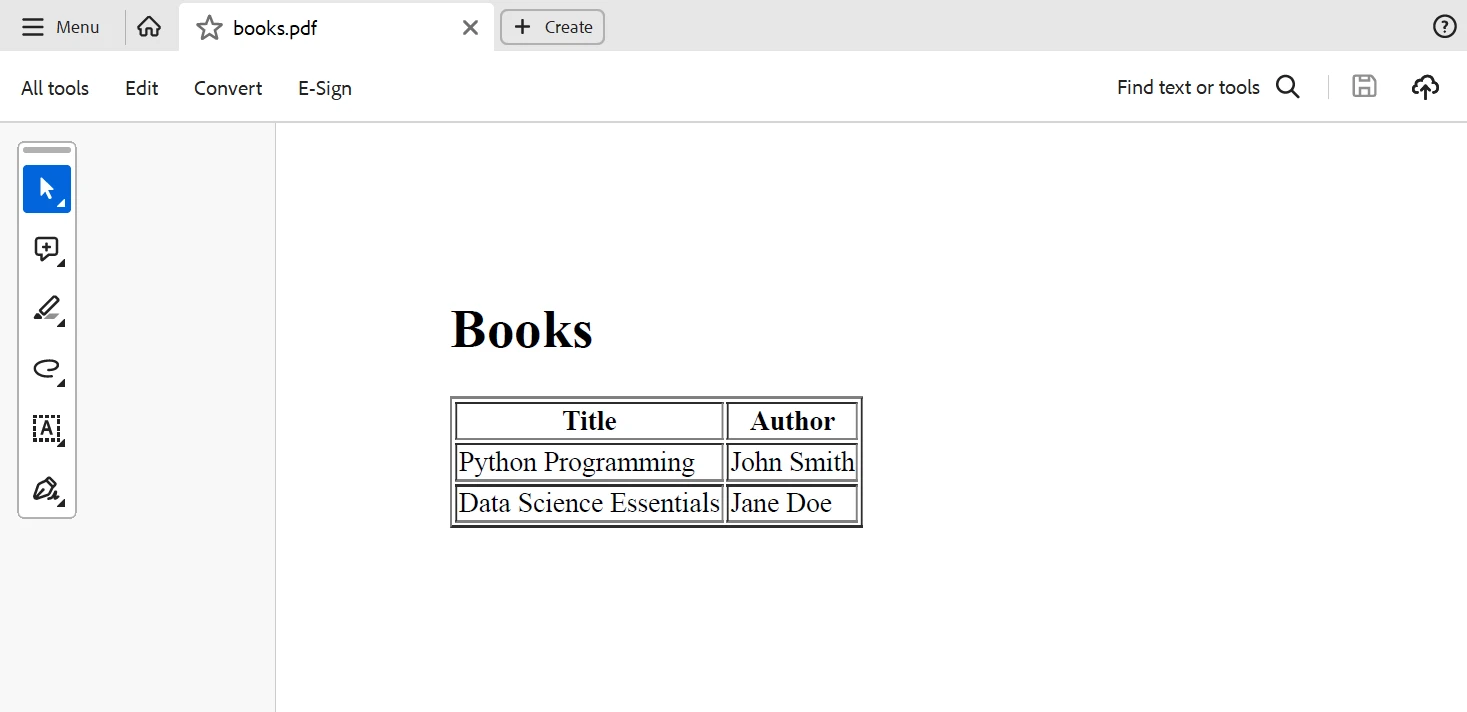
pdf.SaveAs("books.pdf")Ten kod w języku Python generuje tabelę HTML zawierającą tytuły książek i nazwiska autorów, którą IronPDF następnie przekształca w dokument PDF. Poniżej znajduje się wynik wygenerowany na podstawie powyższego kodu.
Wynik
Wnioski
Podsumowując, połączenie IronPDF i xml.etree Python oferuje solidne rozwiązanie dla programistów, którzy chcą analizować dane XML i tworzyć dynamiczne dokumenty PDF na podstawie przeanalizowanych danych. Dzięki niezawodnemu i wydajnemu interfejsowi API Python xml.etree programiści mogą z łatwością wyodrębniać dane strukturalne z dokumentów XML. IronPDF wzbogaca to o możliwość tworzenia estetycznych i edytowalnych dokumentów PDF na podstawie przetworzonych danych XML.
Python i IronPDF umożliwiają programistom automatyzację zadań związanych z przetwarzaniem danych, pozyskiwanie cennych informacji ze źródeł danych XML oraz prezentowanie ich w profesjonalny i atrakcyjny wizualnie sposób za pomocą dokumentów PDF. Niezależnie od tego, czy chodzi o generowanie raportów, tworzenie faktur czy dokumentacji, synergia między xml.etree Pythonem a IronPDF otwiera nowe możliwości w zakresie przetwarzania danych i generowania dokumentów.
IronPDF jest dostępny w przystępnej cenie w pakiecie, zapewniając doskonałą wartość dzięki dożywotniej licencji (np. $799 w przypadku jednorazowego zakupu dla kilku systemów). Licencjonowani użytkownicy mają całodobowy dostęp do pomocy technicznej online. Więcej informacji na temat opłat można znaleźć na tej stronie internetowej. Odwiedź tę stronę, aby dowiedzieć się więcej o produktach Iron Software.
















