
ElementTree를 사용하여 Python에서 XML 파싱하기
XML(확장 가능한 마크업 언어)은 데이터 처리 및 문서 생성에서 구조화된 데이터를 표현하는 데 널리 사용되고 유연한 형식입니다. Python의 표준 라이브러리에는 XML 데이터를 구문 분석하거나 생성하고, 자식 요소를 조작하며, XML 문서를 프로그래밍 방식으로 생성하는 강력한 도구 세트를 제공하는 xml.etree가 포함되어 있습니다.
PDF 문서를 생성하고 편집하는 .NET 라이브러리인 IronPDF 와 함께 사용하면 개발자는 XML 요소 객체 데이터 처리 및 동적 PDF 문서 생성을 가속화할 수 있습니다. 이 심층 가이드에서는 Python의 xml.etree를 파헤치고 주요 기능과 기능을 탐색하며 IronPDF와 통합하여 데이터 처리의 새로운 가능성을 열어주는 방법을 보여드립니다.
xml.etree란 무엇인가요?
xml.etree 는 Python 표준 라이브러리의 일부입니다. 접미사 .etree 가 붙는 ElementTree는 XML 문서를 처리하고 수정하기 위한 간편하고 효율적인 XML API를 제공합니다. 이를 통해 프로그래머는 계층적 트리 구조로 XML 데이터와 상호 작용할 수 있으므로 XML 파일의 탐색, 수정 및 프로그래밍 방식 생성이 간소화됩니다.
비록 가볍고 사용하기 간단하지만 xml.etree는 XML 루트 요소 데이터를 처리하는 강력한 기능을 제공합니다. 이 도구는 파일, 문자열 또는 파일과 유사한 객체에서 XML 데이터 문서를 구문 분석하는 방법을 제공합니다. 파싱된 XML 파일은 Element 객체의 트리 구조로 표시됩니다. 개발자는 이 트리 구조를 탐색하고, 요소와 속성에 접근하며, 요소를 편집, 제거 또는 추가하는 등의 다양한 작업을 수행할 수 있습니다.

xml.etree의 특징
XML 문서 파싱
문자열, 파일 또는 파일과 유사한 객체에서 XML 문서를 구문 분석하는 방법은 xml.etree에 있습니다. XML 자료는 parse() 함수를 사용하여 처리할 수 있으며, 이는 유효한 요소 객체로 구문 분석된 XML 문서를 나타내는 ElementTree 객체도 생성합니다.
XML 트리 탐색
개발자는 문서가 처리된 후 xml.etree을 사용하여 XML 선언 트리의 요소를 find(), findall() 및 iter()와 같은 함수를 사용하여 탐색할 수 있습니다. 이러한 접근 방식을 통해 태그, 속성 또는 XPath 표현식을 기반으로 특정 요소에 접근하는 것이 간단해집니다.
XML 문서 수정
XML 문서 내에서 xml.etree을 사용하여 구성 요소와 속성을 추가, 편집 및 제거하는 방법이 있습니다. XML 트리의 본질적으로 계층적인 데이터 형식 구조와 내용을 프로그래밍 방식으로 변경하면 데이터 수정, 업데이트 및 변환이 가능해집니다.
XML 문서 직렬화
XML 문서를 수정한 후 ElementTree.write()와 같은 함수를 사용하여 문자열 또는 파일과 유사한 객체로 XML 트리를 직렬화할 수 있는 기능을 xml.etree에서 제공합니다. 이를 통해 개발자는 XML 트리를 생성하거나 수정하고, 그로부터 XML 출력을 생성할 수 있습니다.
XPath 지원
XML 문서에서 노드를 선택하기 위한 쿼리 언어인 XPath에 대한 지원은 xml.etree에 의해 제공됩니다. 개발자는 XPath 표현식을 사용하여 XML 트리 내의 항목을 쿼리하고 필터링함으로써 정교한 데이터 검색 및 조작 작업을 수행할 수 있습니다.
반복 구문 분석
전체 문서를 한 번에 메모리에 로드하는 대신 xml.etree의 반복 구문 분석 지원 덕분에 개발자는 XML 문서를 순차적으로 처리할 수 있습니다. 이는 대용량 XML 파일을 효율적으로 관리하는 데 매우 유용합니다.
네임스페이스 지원
개발자는 요소 및 속성 식별을 위한 네임스페이스를 사용하는 XML 문서와 xml.etree의 XML 네임스페이스 지원을 사용하여 작업할 수 있습니다. 이 기능은 기본 XML 네임스페이스 접두사를 해결하고 XML 문서 내에서 네임스페이스를 지정하는 방법을 제공합니다.
오류 처리
잘못된 XML 문서와 구문 분석 오류에 대한 오류 처리 기능은 xml.etree에 포함되어 있습니다. 이 기술은 오류 관리 및 포착 기능을 제공하여 XML 데이터 작업 시 신뢰성과 견고성을 보장합니다.
호환성 및 휴대성
Python 표준 라이브러리의 구성 요소이므로 xml.etree는 추가 설치 없이 Python 프로그램에서 즉시 사용할 수 있습니다. 이 라이브러리는 Python 2와 Python 3 모두에서 작동하기 때문에 휴대성이 뛰어나고 다양한 Python 환경과 호환됩니다.
xml.etree를 생성하고 구성합니다.
XML 문서를 생성하세요
XML 트리의 요소를 나타내는 객체를 만들고 이를 루트 요소에 연결함으로써 XML 문서를 생성할 수 있습니다. 다음은 XML 데이터를 생성하는 방법을 보여주는 예시입니다.
import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Create a book element as a child of the root
book1 = ET.SubElement(root, "book")
book1.set("id", "1")
# Add child elements to the book
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Create another book element
book2 = ET.SubElement(root, "book")
book2.set("id", "2")
# Add child elements to the second book
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create an ElementTree object from the root element
tree = ET.ElementTree(root)import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Create a book element as a child of the root
book1 = ET.SubElement(root, "book")
book1.set("id", "1")
# Add child elements to the book
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Create another book element
book2 = ET.SubElement(root, "book")
book2.set("id", "2")
# Add child elements to the second book
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create an ElementTree object from the root element
tree = ET.ElementTree(root)XML 문서를 파일에 저장
ElementTree 객체의 write() 기능을 사용하여 XML 파일을 작성할 수 있습니다:
# Write XML document to file
tree.write("catalog.xml")# Write XML document to file
tree.write("catalog.xml")이렇게 하면 "catalog.xml"이라는 파일에 XML 문서가 생성됩니다.
XML 문서를 파싱합니다
ElementTree는 parse() 함수를 사용하여 XML 데이터를 구문 분석합니다:
# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()이 코드는 XML 문서 "catalog.xml"을 구문 분석하여 XML 트리의 루트 요소를 반환합니다.
접근 요소 및 속성
Element 객체가 제공하는 다양한 메서드와 속성을 사용하여 XML 문서의 요소와 속성에 접근할 수 있습니다. 예를 들어, 첫 번째 책의 제목을 보려면 다음과 같이 하세요.
# Access the title of the first book
first_book_title = root[0].find("title").text
print("Title of the first book:", first_book_title)# Access the title of the first book
first_book_title = root[0].find("title").text
print("Title of the first book:", first_book_title)XML 문서 수정
XML 문서는 구성 요소와 속성을 추가, 변경 또는 삭제하여 수정할 수 있습니다. 예를 들어 두 번째 책의 저자를 바꾸려면 다음과 같이 하면 됩니다.
# Modify the author of the second book
root[1].find("author").text = "Alice Smith"# Modify the author of the second book
root[1].find("author").text = "Alice Smith"XML 문서 직렬화
ElementTree 모듈의 tostring() 기능을 사용하여 XML 문서를 문자열로 직렬화할 수 있습니다:
# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)IronPDF 시작하기
IronPDF 란 무엇인가요?
IronPDF 는 C#, VB .NET 및 기타 .NET 언어로 PDF 문서를 프로그래밍 방식으로 생성, 편집 및 변경할 수 있는 강력한 .NET 라이브러리입니다. 이 도구는 개발자에게 고품질 PDF를 동적으로 생성할 수 있는 포괄적인 기능 세트를 제공하여 많은 응용 프로그램에서 널리 사용되고 있습니다.
IronPDF의 주요 기능
PDF 생성: IronPDF 사용하면 프로그래머는 새 PDF 문서를 생성하거나 기존 HTML 태그, 텍스트, 이미지 및 기타 파일 형식을 PDF로 변환할 수 있습니다. 이 기능은 보고서, 송장, 영수증 및 기타 문서를 동적으로 생성하는 데 매우 유용합니다.
HTML을 PDF로 변환: IronPDF 개발자가 JavaScript 및 CSS 스타일을 포함한 HTML 문서를 PDF 파일로 간편하게 변환할 수 있도록 지원합니다. 이를 통해 웹 페이지, 동적으로 생성된 콘텐츠 및 HTML 템플릿에서 PDF를 생성할 수 있습니다.
PDF 문서 수정 및 편집: IronPDF 기존 PDF 문서를 수정하고 변경하기 위한 포괄적인 기능 세트를 제공합니다. 개발자는 여러 PDF 파일을 병합하거나, 다른 문서로 분리하거나, 페이지를 제거하거나, 책갈피, 주석 및 워터마크를 추가하는 등 다양한 기능을 사용하여 요구 사항에 맞게 PDF를 사용자 지정할 수 있습니다.
IronPDF 와 xml.etree의 결합
이 섹션에서는 파싱된 XML 데이터를 기반으로 IronPDF 사용하여 PDF 문서를 생성하는 방법을 보여줍니다. XML과 IronPDF 의 장점을 모두 활용하면 구조화된 데이터를 전문적인 PDF 문서로 효율적으로 변환할 수 있습니다. 자세한 안내는 다음과 같습니다.
설치
시작하기 전에 IronPDF 설치되어 있는지 확인하십시오. pip를 사용하여 설치할 수 있습니다.
pip install ironpdf
파싱된 XML을 사용하여 IronPDF 로 PDF 문서를 생성합니다.
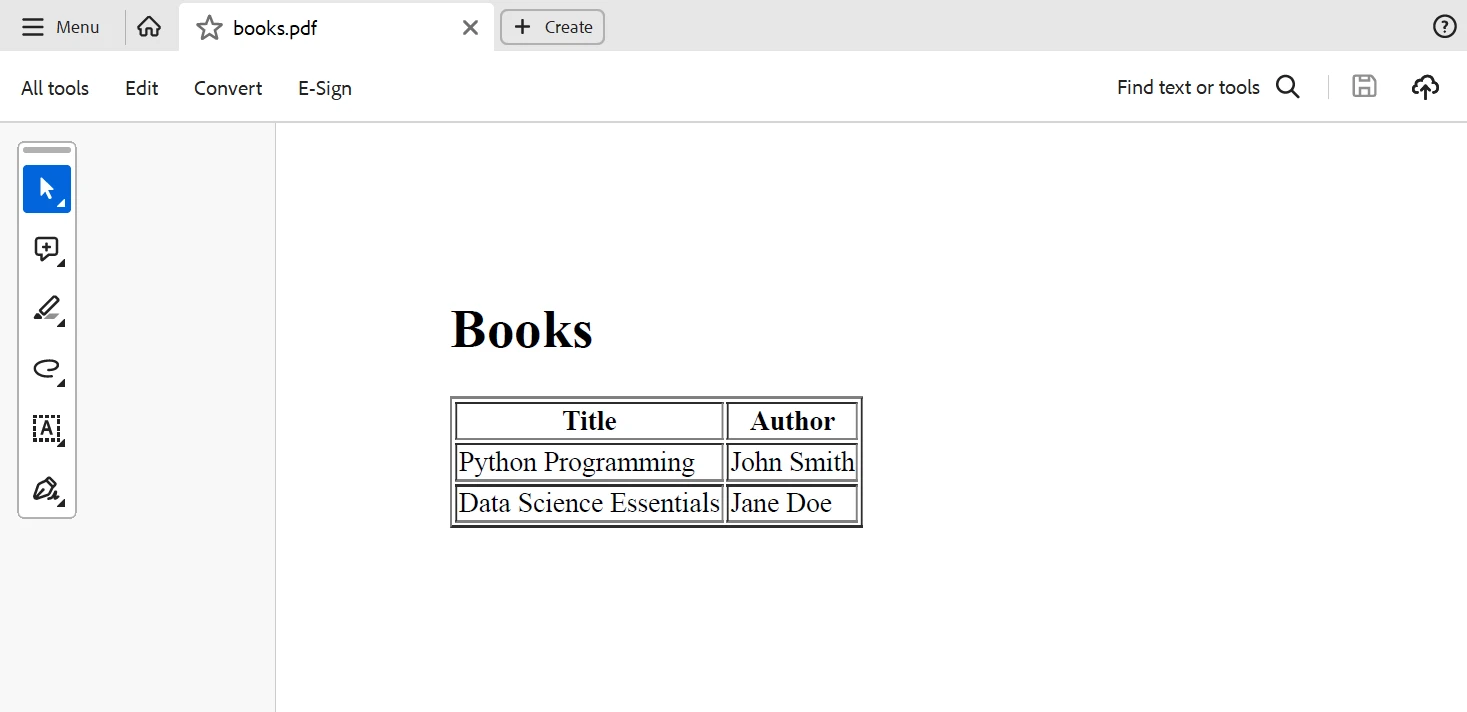
IronPDF XML을 처리한 후 추출한 데이터를 기반으로 PDF 문서를 생성하는 데 사용할 수 있습니다. 책 제목과 저자가 포함된 표가 있는 PDF 문서를 만들어 봅시다.
from ironpdf import *
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Loop through books to add each to the table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
html_content += """
</table>
</body>
</html>
"""
# Generate PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
pdf.SaveAs("books.pdf")from ironpdf import *
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Loop through books to add each to the table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
html_content += """
</table>
</body>
</html>
"""
# Generate PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
pdf.SaveAs("books.pdf")이 Python 코드는 책 제목과 저자가 포함된 HTML 테이블을 생성하고, IronPDF 이를 PDF 문서로 변환합니다. 다음은 위 코드의 실행 결과입니다.
산출
결론
결론적으로, IronPDF와 xml.etree Python의 조합은 XML 데이터를 파싱하고 파싱된 데이터를 기반으로 동적 PDF 문서를 생성하려는 개발자들에게 강력한 솔루션을 제공합니다. 신뢰할 수 있고 효과적인 Python xml.etree API를 사용하여 개발자는 XML 문서에서 구조화된 데이터를 쉽게 추출할 수 있습니다. IronPDF 처리된 XML 데이터로부터 미적으로 보기 좋고 편집 가능한 PDF 문서를 생성할 수 있는 기능을 제공함으로써 이러한 장점을 더욱 향상시킵니다.
함께, xml.etree Python과 IronPDF는 개발자가 데이터 처리 작업을 자동화하고, XML 데이터 소스에서 유용한 통찰력을 추출하고, 이를 PDF 문서를 통해 전문적이고 시각적으로 매력적인 방식으로 제시할 수 있도록 합니다. 보고서 생성, 청구서 작성 또는 문서 제작 여부에 관계없이 xml.etree Python과 IronPDF 간의 시너지는 데이터 처리 및 문서 생성에서 새로운 가능성을 열어줍니다.
IronPDF는 번들로 구매할 때 적당한 가격이 책정되며, 평생 라이선스와 함께 훌륭한 가치를 제공합니다(예: 여러 시스템에 한 번만 구매). 라이선스 사용자는 연중무휴 24시간 온라인 기술 지원을 이용할 수 있습니다. 수수료에 대한 자세한 내용은 이 웹사이트를 참조하십시오. Iron Software의 제품에 대해 자세히 알아보려면 이 페이지를 방문하세요.
















