
使用 ElementTree 在 Python 中解析 XML
XML(可扩展标记语言)是表示数据处理中和文档生成中结构化数据的一种流行且灵活的格式。 Python 的标准库包括 xml.etree,该库为开发人员提供了一套强大的工具,用于解析或创建 XML 数据、操作子元素以及以编程方式生成 XML 文档。
与IronPDF结合使用时,.NET库用于创建和编辑PDF文档,开发人员可以加快XML元素对象数据处理和动态PDF文档生成。 在本深入指南中,我们将深入研究 Python 的 xml.etree,探索其主要特性和功能,并向您展示如何将其与IronPDF集成,从而解锁数据处理的新可能性。
什么是xml.etree?
xml.etree是Python标准库的一部分。 它的后缀是.etree,也称为ElementTree,提供了一种简单而有效的XML API,用于处理和修改XML文档。 它允许程序员以层次树状结构与XML数据进行交互,简化了XML文件的导航、修改和编程生成。
虽然它轻巧易用,但 xml.etree 提供了处理 XML 根元素数据的强大功能。 它提供了一种从文件、字符串或类似文件的对象中解析XML数据文档的方法。 解析后生成的XML文件显示为元素对象的树形结构。 开发人员可以导航此树,访问元素和属性,并执行各种操作,诸如编辑、删除或添加元素。

xml.etree的特点
解析XML文档
xml.etree 中提供了从字符串、文件或类似文件的对象解析 XML 文档的方法。 可以使用 parse() 函数处理 XML 材料,该函数还会生成一个 ElementTree 对象,该对象表示已解析的 XML 文档,其中包含有效的元素对象。
导航XML树
开发人员可以使用 xml.etree 来遍历 XML 声明树的元素,并在文档处理完成后使用 findall() 和 iter() 等函数。 通过这些方法可以简单地根据标签、属性或XPath表达式访问特定元素。
修改XML文档
在 XML 文档中,可以使用 xml.etree 来添加、编辑和删除组件和属性。 以编程方式改变XML树固有的层次数据格式结构和内容,使数据得以修改、更新和转换。
序列化XML文档
xml.etree 允许在修改 XML 文档后,使用 ElementTree.write() 等函数将 XML 树序列化为字符串或类似文件的对象。 这使开发人员能够创建或修改XML树并从中生成XML输出。
XPath支持
xml.etree 提供了对 XPath(一种用于从 XML 文档中选择节点的查询语言)的支持。 开发人员可以通过使用XPath表达式在XML树中查询和过滤项目,执行复杂的数据检索和处理活动。
迭代解析
由于 xml.etree 支持迭代解析,开发人员可以按顺序处理 XML 文档,而无需一次性将整个文档加载到内存中。 这对于有效管理大型XML文件非常有帮助。
命名空间支持
开发人员可以使用 xml.etree 对 XML 命名空间的支持来处理使用命名空间进行元素和属性标识的 XML 文档。 它提供了解决默认XML命名空间前缀和在XML文档内指定命名空间的方法。
错误处理
xml.etree 中包含了对不正确的 XML 文档和解析错误的错误处理功能。 它提供了错误管理和捕获的技术,确保在处理XML数据时的可靠性和稳健性。
兼容性和可移植性
由于 xml.etree 是 Python 标准库的一个组件,因此无需任何进一步安装即可在 Python 程序中立即使用。 它与Python 2和Python 3兼容,因此适用于许多Python设置。
创建和配置xml.etree
创建一个XML文档
通过构建代表XML树的元素的对象并将它们附加到根元素,可以生成XML文档。 这是如何创建XML数据的示例:
import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Create a book element as a child of the root
book1 = ET.SubElement(root, "book")
book1.set("id", "1")
# Add child elements to the book
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Create another book element
book2 = ET.SubElement(root, "book")
book2.set("id", "2")
# Add child elements to the second book
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create an ElementTree object from the root element
tree = ET.ElementTree(root)import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Create a book element as a child of the root
book1 = ET.SubElement(root, "book")
book1.set("id", "1")
# Add child elements to the book
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Create another book element
book2 = ET.SubElement(root, "book")
book2.set("id", "2")
# Add child elements to the second book
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create an ElementTree object from the root element
tree = ET.ElementTree(root)将XML文档写入文件
ElementTree 对象的 write() 函数可用于写入 XML 文件:
# Write XML document to file
tree.write("catalog.xml")# Write XML document to file
tree.write("catalog.xml")这将在名为"catalog.xml"的文件中创建一个XML文档。
解析XML文档
ElementTree 使用 parse() 函数解析 XML 数据:
# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()这将解析XML文档"catalog.xml",产生XML树的根元素。
访问元素和属性
使用Element对象提供的各种方法和属性,可以访问XML文档的元素和属性。 例如,查看第一本书的标题:
# Access the title of the first book
first_book_title = root[0].find("title").text
print("Title of the first book:", first_book_title)# Access the title of the first book
first_book_title = root[0].find("title").text
print("Title of the first book:", first_book_title)修改XML文档
通过添加、修改或删除组件和属性,可以更改XML文档。 比如要改变第二本书的作者:
# Modify the author of the second book
root[1].find("author").text = "Alice Smith"# Modify the author of the second book
root[1].find("author").text = "Alice Smith"序列化XML文档
ElementTree 模块中的 tostring() 函数可用于将 XML 文档序列化为字符串:
# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)IronPDF 入门
什么是 IronPDF?
IronPDF是一个强大的.NET库,用于以C#、VB.NET和其他.NET语言编程方式创建、编辑和更改PDF文档。 它为开发人员提供了全面的功能集,可以动态创建高质量的PDF,使其成为许多应用的热门选择。
IronPDF的关键特性
PDF 生成:使用IronPDF,程序员可以创建新的 PDF 文档,或将现有的 HTML 标签、文本、图像和其他文件格式转换为 PDF。 这一特性对于动态创建报告、发票、收据和其他文档非常有用。
HTML 转 PDF 转换: IronPDF 使开发人员能够轻松地将 HTML 文档(包括 JavaScript 和 CSS 中的样式)转换为 PDF 文件。 这允许从网页、动态生成的内容和HTML模板创建PDF。
PDF 文档的修改和编辑: IronPDF提供了一套全面的功能,用于修改和更改预先存在的 PDF 文档。 开发人员可以合并多个PDF文件,将它们分开成其他文档,删除页面,并添加书签、注释和水印等特性,以根据需要定制PDF。
IronPDF和xml.etree结合
本节将演示如何使用基于解析XML数据的IronPDF生成PDF文档。 通过利用XML和IronPDF的优势,可以有效地将结构化数据转化为专业的PDF文档。 这是一个详细的指南:
安装
在开始之前,请确保已安装IronPDF。 它可以通过pip安装:
pip install ironpdf
使用IronPDF和解析的XML生成PDF文档
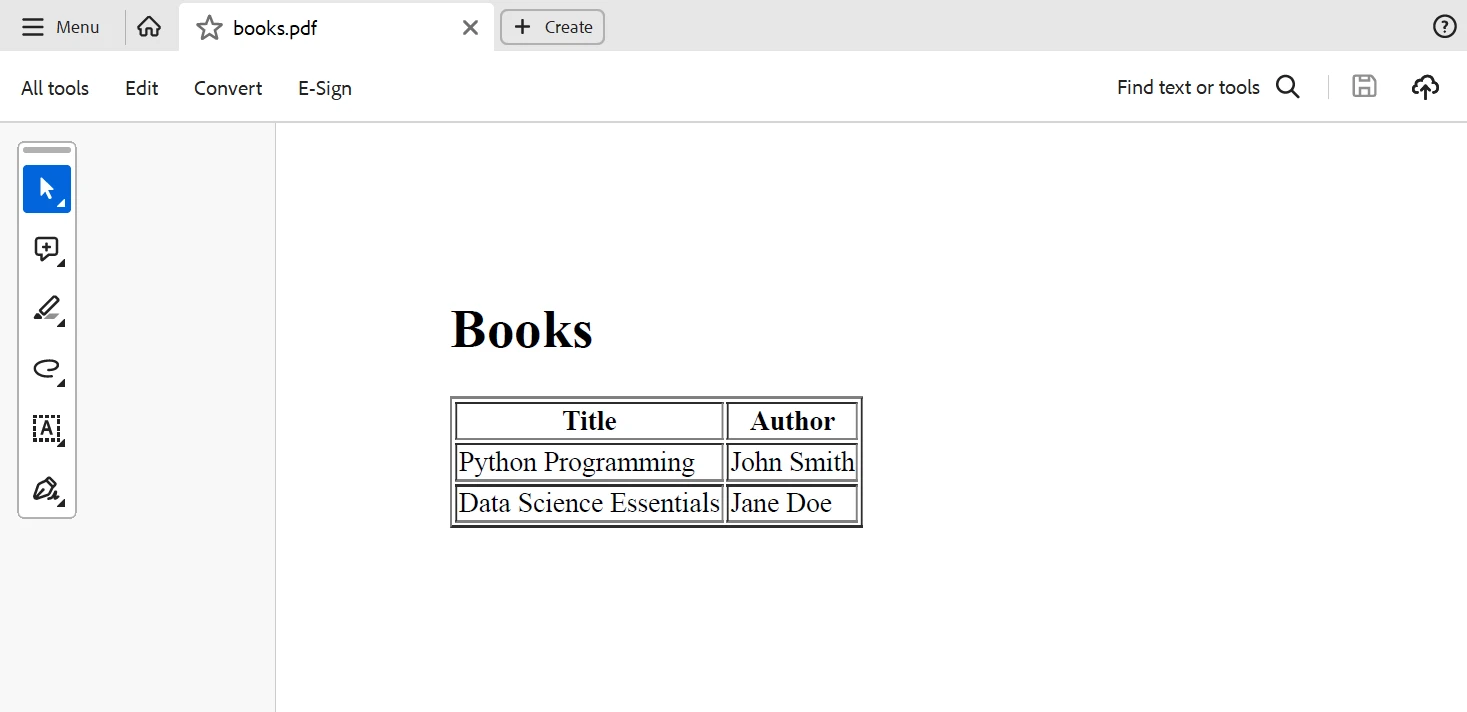
在处理XML数据后,可以使用IronPDF创建基于提取数据的PDF文档。 让我们创建一个包含书名和作者的表格的PDF文档:
from ironpdf import *
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Loop through books to add each to the table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
html_content += """
</table>
</body>
</html>
"""
# Generate PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
pdf.SaveAs("books.pdf")from ironpdf import *
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Loop through books to add each to the table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
html_content += """
</table>
</body>
</html>
"""
# Generate PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
pdf.SaveAs("books.pdf")这段Python代码生成一个包含书名和作者的HTML表格,IronPDF然后将其转换为PDF文档。 下面是从上述代码生成的输出。
输出
结论
总之, IronPDF和 Python 的结合为希望解析 XML 数据并根据解析后的数据生成动态 PDF 文档的开发人员提供了一个强大的解决方案。 借助可靠高效的 Python API,开发人员可以轻松地从 XML 文档中提取结构化数据。 IronPDF通过提供从处理的XML数据创建美观且可编辑的PDF文档的能力来增强这一点。
xml.etree Python 和IronPDF携手合作,使开发人员能够自动化数据处理任务,从 XML 数据源中提取有价值的见解,并通过 PDF 文档以Professional且引人入胜的方式呈现这些见解。 无论是生成报告、创建发票还是生成文档,xml.etree Python 和IronPDF之间的协同作用,都为数据处理和文档生成开启了新的可能性。
IronPDF捆绑购买价格相当合理,终身许可证物超所值(例如,$999 一次性购买即可在多个系统中使用)。 持证用户可以24/7访问在线技术支持。 有关费用的更多详细信息,请前往此网站。 请访问此页面以了解更多关于Iron Software产品的信息。
















