
Analisando XML em Python com ElementTree
XML (eXtensible Markup Language) é um formato popular e flexível para representar dados estruturados no processamento de dados e na geração de documentos. A biblioteca padrão do Python inclui xml.etree, uma biblioteca que fornece aos desenvolvedores um conjunto poderoso de ferramentas para analisar ou criar dados XML, manipular elementos filho e gerar documentos XML programaticamente.
Quando combinado com o IronPDF, uma biblioteca .NET para criação e edição de documentos PDF, os desenvolvedores podem agilizar o processamento de dados de objetos de elementos XML e a geração dinâmica de documentos PDF. Neste guia detalhado, vamos nos aprofundar no xml.etree do Python, explorar seus principais recursos e funcionalidades, e mostrar como integrá-lo com IronPDF para desbloquear novas possibilidades no processamento de dados.
O que é xml.etree?
xml.etree faz parte da biblioteca padrão do Python. Possui o sufixo .etree , também conhecido como ElementTree, que oferece uma API XML simples e eficaz para processar e modificar documentos XML. Permite aos programadores interagir com dados XML em uma estrutura de árvore hierárquica, simplificando a navegação, a modificação e a geração programática de arquivos XML.
Apesar de ser leve e simples de usar, xml.etree oferece funcionalidade robusta para lidar com dados de elementos raiz XML. Ele fornece uma maneira de analisar documentos de dados XML a partir de arquivos, strings ou objetos semelhantes a arquivos. O arquivo XML analisado resultante é exibido como uma árvore de objetos Element. Os desenvolvedores podem navegar por essa árvore, acessar elementos e atributos e executar várias ações, como editar, remover ou adicionar elementos.

Características do xml.etree
Análise de documentos XML
Métodos para analisar documentos XML a partir de strings, arquivos ou objetos semelhantes a arquivos estão disponíveis em xml.etree. O material XML pode ser processado usando a função parse(), que também produz um objeto ElementTree representando o documento XML analisado com um objeto de elemento válido.
Navegando em árvores XML
Os desenvolvedores podem usar xml.etree para percorrer os elementos de uma árvore de declaração XML usando funções como find(), findall() e iter() após o documento ter sido processado. Essas abordagens simplificam o acesso a determinados elementos com base em tags, atributos ou expressões XPath.
Modificando documentos XML
Dentro de um documento XML, existem maneiras de adicionar, editar e remover componentes e atributos usando xml.etree. A alteração programática da estrutura e do conteúdo do formato de dados inerentemente hierárquico da árvore XML permite a modificação, atualização e transformação dos dados.
Serializando documentos XML
xml.etree permite a serialização de árvores XML para strings ou objetos semelhantes a arquivos usando funções como ElementTree.write() após a modificação de um documento XML. Isso possibilita aos desenvolvedores criar ou modificar árvores XML e gerar saída XML a partir delas.
Suporte a XPath
Suporte para XPath, uma linguagem de consulta para escolher nós de um documento XML, é fornecido por xml.etree. Os desenvolvedores podem realizar atividades sofisticadas de recuperação e manipulação de dados usando expressões XPath para consultar e filtrar itens em uma árvore XML.
Análise sintática iterativa
Em vez de carregar todo o documento na memória de uma vez, os desenvolvedores podem manipular documentos XML sequencialmente graças ao suporte de xml.etree para análise iterativa. Isso é muito útil para gerenciar arquivos XML grandes de forma eficaz.
Suporte a namespaces
Os desenvolvedores podem trabalhar com documentos XML que usam namespaces para identificação de elementos e atributos, usando o suporte de xml.etree para namespaces XML. Ele fornece maneiras de resolver prefixos de namespace XML padrão e especificar namespaces dentro de um documento XML.
Tratamento de erros
Capacidades de tratamento de erros para documentos XML incorretos e erros de análise estão incluídas em xml.etree. Oferece técnicas para gerenciamento e captura de erros, garantindo confiabilidade e robustez ao trabalhar com dados XML.
Compatibilidade e portabilidade
Como xml.etree é um componente da biblioteca padrão do Python, ele pode ser usado imediatamente em programas Python sem exigir quaisquer instalações adicionais. É portátil e compatível com diversas configurações do Python, pois funciona tanto com Python 2 quanto com Python 3.
Criar e configurar xml.etree
Criar um documento XML
Ao construir objetos que representam os elementos da árvore XML e anexá-los a um elemento raiz, você pode gerar um documento XML. Esta é uma ilustração de como criar dados XML:
import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Create a book element as a child of the root
book1 = ET.SubElement(root, "book")
book1.set("id", "1")
# Add child elements to the book
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Create another book element
book2 = ET.SubElement(root, "book")
book2.set("id", "2")
# Add child elements to the second book
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create an ElementTree object from the root element
tree = ET.ElementTree(root)import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Create a book element as a child of the root
book1 = ET.SubElement(root, "book")
book1.set("id", "1")
# Add child elements to the book
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Create another book element
book2 = ET.SubElement(root, "book")
book2.set("id", "2")
# Add child elements to the second book
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create an ElementTree object from the root element
tree = ET.ElementTree(root)Gravar documento XML em arquivo
A função write() do objeto ElementTree pode ser usada para gravar o arquivo XML:
# Write XML document to file
tree.write("catalog.xml")# Write XML document to file
tree.write("catalog.xml")Isso criará um documento XML em um arquivo chamado "catalog.xml".
Analisar um documento XML
O ElementTree analisa dados XML usando a função parse():
# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()Este comando analisará o documento XML "catalog.xml", retornando o elemento raiz da árvore XML.
Acessar elementos e atributos
Utilizando uma variedade de métodos e propriedades oferecidos pelos objetos Element, você pode acessar os elementos e atributos do documento XML. Por exemplo, para ver o título do primeiro livro:
# Access the title of the first book
first_book_title = root[0].find("title").text
print("Title of the first book:", first_book_title)# Access the title of the first book
first_book_title = root[0].find("title").text
print("Title of the first book:", first_book_title)Modificar documento XML
O documento XML pode ser alterado adicionando, modificando ou excluindo componentes e atributos. Para alterar o autor do segundo livro, por exemplo:
# Modify the author of the second book
root[1].find("author").text = "Alice Smith"# Modify the author of the second book
root[1].find("author").text = "Alice Smith"Serializar documento XML
A função tostring() do módulo ElementTree pode ser usada para serializar o documento XML para uma string:
# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)Primeiros passos com o IronPDF
O que é o IronPDF?
IronPDF é uma poderosa biblioteca .NET para criar, editar e alterar documentos PDF programaticamente em C#, VB .NET e outras linguagens .NET . Ele oferece aos desenvolvedores um conjunto abrangente de recursos para a criação dinâmica de PDFs de alta qualidade, tornando-se uma escolha popular para muitas aplicações.
Principais funcionalidades do IronPDF
Geração de PDFs: Usando o IronPDF, os programadores podem criar novos documentos PDF ou converter tags HTML, textos, imagens e outros formatos de arquivo existentes em PDFs. Essa funcionalidade é muito útil para criar relatórios, faturas, recibos e outros documentos de forma dinâmica.
Conversão de HTML para PDF: O IronPDF facilita para os desenvolvedores a transformação de documentos HTML, incluindo estilos de JavaScript e CSS, em arquivos PDF. Isso permite a criação de PDFs a partir de páginas da web, conteúdo gerado dinamicamente e modelos HTML.
Modificação e edição de documentos PDF: O IronPDF oferece um conjunto abrangente de recursos para modificar e alterar documentos PDF preexistentes. Os desenvolvedores podem mesclar vários arquivos PDF, separá-los em outros documentos, remover páginas e adicionar marcadores, anotações e marcas d'água, entre outros recursos, para personalizar os PDFs de acordo com suas necessidades.
IronPDF e xml.etree combinados
Esta seção demonstrará como gerar documentos PDF com o IronPDF com base em dados XML analisados. Aproveitando os pontos fortes do XML e do IronPDF, você pode transformar dados estruturados em documentos PDF profissionais de forma eficiente. Aqui está um guia detalhado:
Instalação
Certifique-se de que o IronPDF esteja instalado antes de começar. Pode ser instalado usando o pip:
pip install ironpdf
Gere um documento PDF com o IronPDF usando XML analisado.
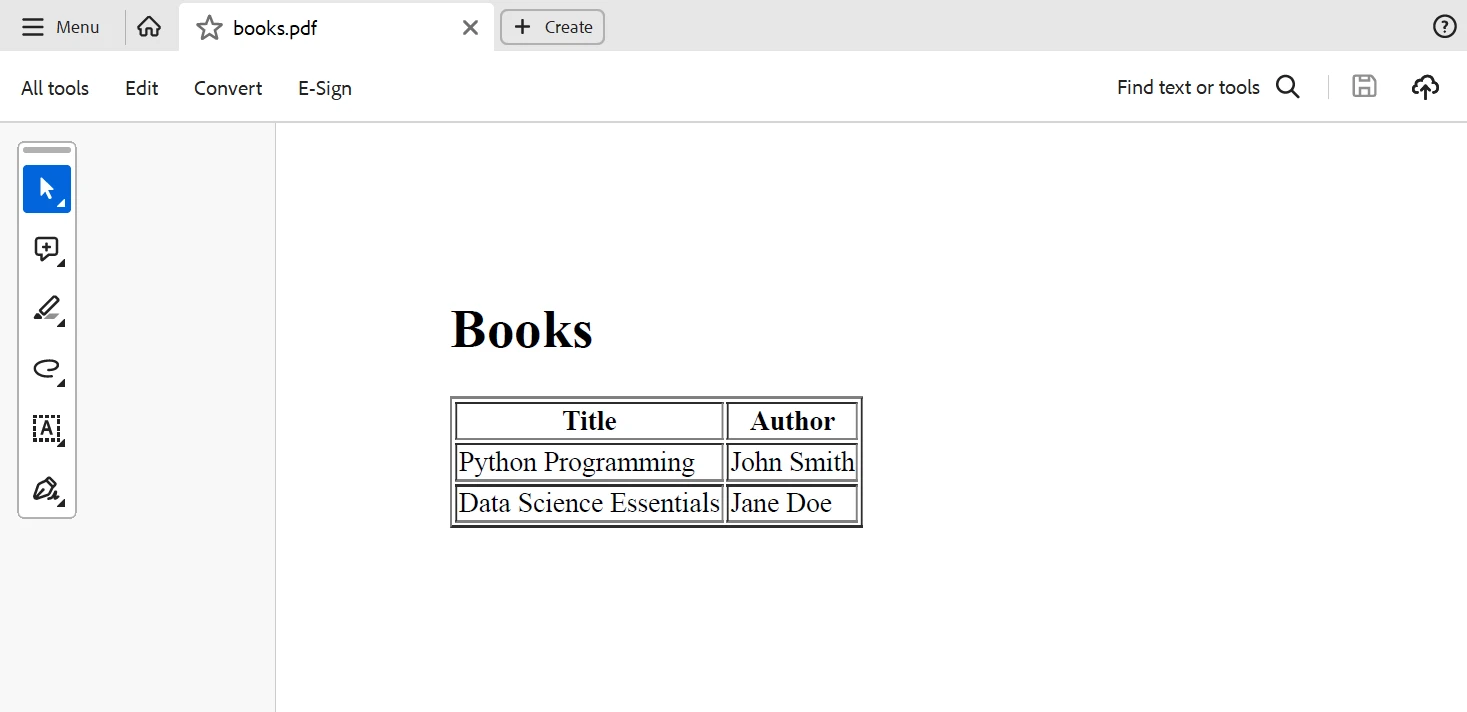
O IronPDF pode ser usado para criar um documento PDF com base nos dados extraídos do XML após o seu processamento. Vamos criar um documento PDF com uma tabela contendo os nomes dos livros e seus autores:
from ironpdf import *
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Loop through books to add each to the table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
html_content += """
</table>
</body>
</html>
"""
# Generate PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
pdf.SaveAs("books.pdf")from ironpdf import *
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Loop through books to add each to the table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
html_content += """
</table>
</body>
</html>
"""
# Generate PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
pdf.SaveAs("books.pdf")Este código Python gera uma tabela HTML contendo os nomes dos livros e seus autores, que o IronPDF então transforma em um documento PDF. Abaixo está o resultado gerado pelo código acima.
Saída
Conclusão
Em conclusão, a combinação de IronPDF e xml.etree Python oferece uma solução robusta para desenvolvedores que buscam analisar dados XML e produzir documentos PDF dinâmicos com base nos dados analisados. Com a API xml.etree do Python, confiável e eficaz, os desenvolvedores podem facilmente extrair dados estruturados de documentos XML. O IronPDF aprimora isso, oferecendo a capacidade de criar documentos PDF visualmente atraentes e editáveis a partir dos dados XML processados.
Juntos, xml.etree Python e IronPDF capacitam os desenvolvedores a automatizar tarefas de processamento de dados, extrair insights valiosos de fontes de dados XML, e apresentá-los de uma maneira profissional e visualmente atraente através de documentos PDF. Seja gerando relatórios, criando faturas ou produzindo documentação, a sinergia entre xml.etree Python e IronPDF desbloqueia novas possibilidades no processamento de dados e geração de documentos.
IronPDF tem um preço justo quando comprado em um pacote, oferecendo excelente valor com uma licença vitalícia (por exemplo, $999 para uma compra única para diversos sistemas). Usuários licenciados têm acesso a suporte técnico online 24 horas por dia, 7 dias por semana. Para obter mais detalhes sobre a taxa, acesse este site . Visite esta página para saber mais sobre os produtos da Iron Software.
















