
Parsing XML in Python with ElementTree
XML (eXtensible Markup Language) is a popular and flexible format for representing structured data in data processing and document generation. Python's standard library includes xml.etree, a library that provides developers with a powerful set of tools for parsing or creating XML data, manipulating child elements, and generating XML documents programmatically.
When combined with IronPDF, a .NET library for creating and editing PDF documents, developers can expedite XML element object data processing and dynamic PDF document generation. In this in-depth guide, we'll delve into Python's xml.etree, explore its main features and functionalities, and show you how to integrate it with IronPDF to unlock new possibilities in data processing.
What is xml.etree?
xml.etree is part of Python's standard library. It has the suffix .etree, also referred to as ElementTree, which offers a straightforward and effective XML API for processing and modifying XML documents. It enables programmers to interact with XML data in a hierarchical tree structure, simplifying the navigation, modification, and programmatic generation of XML files.
Although it is lightweight and simple to use, xml.etree offers strong functionality for handling XML root element data. It provides a way to parse XML data documents from files, strings, or file-like objects. The resulting parsed XML file is shown as a tree of Element objects. Developers can navigate this tree, access elements and attributes, and perform various actions like editing, removing, or adding elements.

Features of xml.etree
Parsing XML Documents
Methods for parsing XML documents from strings, files, or file-like objects are available in xml.etree. XML material can be processed using the parse() function, which also produces an ElementTree object representing the parsed XML document with a valid element object.
Navigating XML Trees
Developers can use xml.etree to traverse over the elements of an XML declaration tree using functions like find(), findall(), and iter() once the document has been processed. Accessing certain elements based on tags, attributes, or XPath expressions is made simple by these approaches.
Modifying XML Documents
Within an XML document, there are ways to add, edit, and remove components and attributes using xml.etree. Programmatically altering the XML tree's inherently hierarchical data format structure and content enables data modification, updates, and transformations.
Serializing XML Documents
xml.etree allows the serialization of XML trees to strings or file-like objects using functions like ElementTree.write() after modifying an XML document. This makes it possible for developers to create or modify XML trees and produce XML output from them.
XPath Support
Support for XPath, a query language for choosing nodes from an XML document, is provided by xml.etree. Developers can perform sophisticated data retrieval and manipulation activities by using XPath expressions to query and filter items within an XML tree.
Iterative Parsing
Instead of loading the entire document into memory at once, developers can handle XML documents sequentially thanks to xml.etree's support for iterative parsing. This is very helpful for effectively managing big XML files.
Namespaces Support
Developers can work with XML documents that use namespaces for element and attribute identification by using xml.etree's support for XML namespaces. It provides ways to resolve default XML namespace prefixes and specify namespaces inside an XML document.
Error Handling
Error-handling capabilities for incorrect XML documents and parsing errors are included in xml.etree. It offers techniques for error management and capturing, guaranteeing dependability and robustness when working with XML data.
Compatibility and Portability
Since xml.etree is a component of the Python standard library, it may be used immediately in Python programs without requiring any further installations. It is portable and compatible with many Python settings because it works with both Python 2 and Python 3.
Create and Configure xml.etree
Create an XML Document
By building objects that represent the XML tree's elements and attaching them to a root element, you can generate an XML document. This is an illustration of how to create XML data:
import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Create a book element as a child of the root
book1 = ET.SubElement(root, "book")
book1.set("id", "1")
# Add child elements to the book
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Create another book element
book2 = ET.SubElement(root, "book")
book2.set("id", "2")
# Add child elements to the second book
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create an ElementTree object from the root element
tree = ET.ElementTree(root)import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Create a book element as a child of the root
book1 = ET.SubElement(root, "book")
book1.set("id", "1")
# Add child elements to the book
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Create another book element
book2 = ET.SubElement(root, "book")
book2.set("id", "2")
# Add child elements to the second book
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create an ElementTree object from the root element
tree = ET.ElementTree(root)Write XML Document to File
The write() function of the ElementTree object can be used to write the XML file:
# Write XML document to file
tree.write("catalog.xml")# Write XML document to file
tree.write("catalog.xml")This will create an XML document in a file called "catalog.xml".
Parse an XML Document
The ElementTree parses XML data using the parse() function:
# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()This will parse the XML document "catalog.xml", yielding the root element of the XML tree.
Access Elements and Attributes
Using a variety of methods and properties offered by Element objects, you can access the elements and attributes of the XML document. For instance, to view the first book's title:
# Access the title of the first book
first_book_title = root[0].find("title").text
print("Title of the first book:", first_book_title)# Access the title of the first book
first_book_title = root[0].find("title").text
print("Title of the first book:", first_book_title)Modify XML Document
The XML document can be altered by adding, changing, or deleting components and attributes. To change the author of the second book, for instance:
# Modify the author of the second book
root[1].find("author").text = "Alice Smith"# Modify the author of the second book
root[1].find("author").text = "Alice Smith"Serialize XML Document
The tostring() function from the ElementTree module can be used to serialize the XML document to a string:
# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)Getting Started With IronPDF
What is IronPDF?
IronPDF is a powerful .NET library for creating, editing, and altering PDF documents programmatically in C#, VB.NET, and other .NET languages. It provides developers with a comprehensive feature set for dynamically creating high-quality PDFs, making it a popular choice for many applications.
IronPDF's Key Features
PDF Generation: Using IronPDF, programmers can create new PDF documents or convert existing HTML tags, text, images, and other file formats into PDFs. This feature is very useful for creating reports, invoices, receipts, and other documents dynamically.
HTML to PDF Conversion: IronPDF makes it simple for developers to transform HTML documents, including styles from JavaScript and CSS, into PDF files. This enables the creation of PDFs from web pages, dynamically generated content, and HTML templates.
Modification and Editing of PDF Documents: IronPDF provides a comprehensive set of features for modifying and altering pre-existing PDF documents. Developers can merge several PDF files, separate them into other documents, remove pages, and add bookmarks, annotations, and watermarks, among other features, to customize PDFs to their requirements.
IronPDF and xml.etree Combined
This section will demonstrate how to generate PDF documents with IronPDF based on parsed XML data. By leveraging the strengths of both XML and IronPDF, you can efficiently transform structured data into professional PDF documents. Here's a detailed guide:
Installation
Make sure that IronPDF is installed before you begin. It may be installed using pip:
pip install ironpdf
Generate PDF Document with IronPDF using Parsed XML
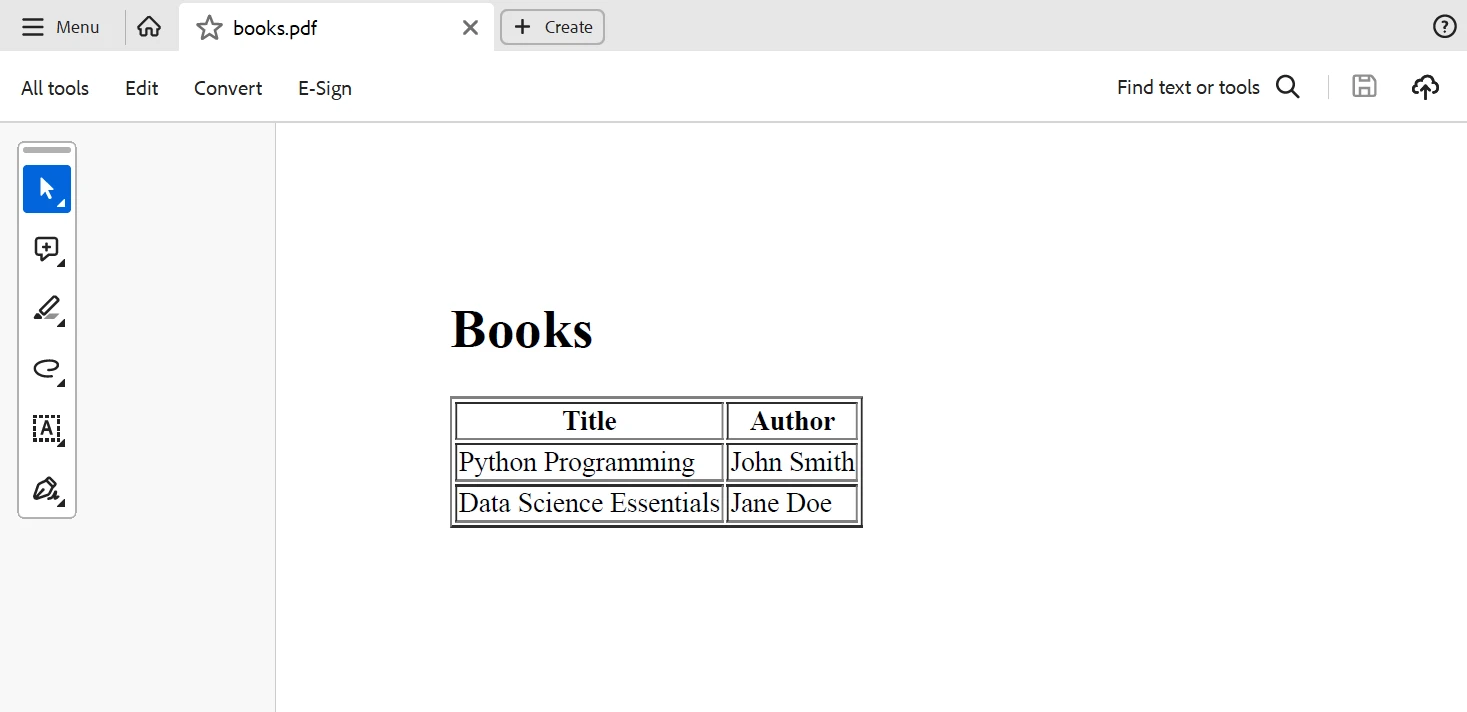
IronPDF can be used to create a PDF document based on the data extracted from the XML after it has been processed. Let's create a PDF document with a table that contains the book names and authors:
from ironpdf import *
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Loop through books to add each to the table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
html_content += """
</table>
</body>
</html>
"""
# Generate PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
pdf.SaveAs("books.pdf")from ironpdf import *
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Loop through books to add each to the table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
html_content += """
</table>
</body>
</html>
"""
# Generate PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
pdf.SaveAs("books.pdf")This Python code generates an HTML table containing the book names and authors, which IronPDF then turns into a PDF document. Below is the output generated from the above code.
Output
Conclusion
In conclusion, the combination of IronPDF and xml.etree Python offers a robust solution for developers looking to parse XML data and produce dynamic PDF documents based on the parsed data. With the reliable and effective Python xml.etree API, developers can easily extract structured data from XML documents. IronPDF enhances this by providing the capability to create aesthetically pleasing and editable PDF documents from the processed XML data.
Together, xml.etree Python and IronPDF empower developers to automate data processing tasks, extract valuable insights from XML data sources, and present them in a professional and visually engaging manner through PDF documents. Whether it's generating reports, creating invoices, or producing documentation, the synergy between xml.etree Python and IronPDF unlocks new possibilities in data processing and document generation.
IronPDF is fairly priced when purchased in a bundle, providing excellent value with a lifetime license (e.g., $999 for a one-time purchase for several systems). Licensed users have 24/7 access to online technical support. For further details on the fee, kindly go to this website. Visit this page to learn more about Iron Software's products.
















