
Parsing XML en Python avec ElementTree
XML (eXtensible Markup Language) est un format populaire et flexible pour représenter des données structurées dans le traitement de données et la génération de documents. La bibliothèque standard de Python inclut xml.etree, une bibliothèque qui fournit aux développeurs un ensemble puissant d'outils pour analyser ou créer des données XML, manipuler des éléments enfants et générer des documents XML par programmation.
Lorsqu'elle est combinée avec IronPDF, une bibliothèque .NET pour créer et modifier des documents PDF, les développeurs peuvent accélérer le traitement des données des objets élémentaires XML et la génération dynamique de documents PDF. Dans ce guide approfondi, nous allons explorer en détail le xml.etree de Python, découvrir ses principales caractéristiques et fonctionnalités, et vous montrer comment l'intégrer à IronPDF pour débloquer de nouvelles possibilités dans le traitement des données.
Qu'est-ce que xml.etree ?
xml.etree fait partie de la bibliothèque standard de Python. Il possède le suffixe .etree, également appelé ElementTree, qui offre une API XML simple et efficace pour traiter et modifier des documents XML. Il permet aux programmeurs d'interagir avec les données XML dans une structure arborescente hiérarchique, simplifiant la navigation, la modification et la génération programmée de fichiers XML.
Bien qu'il soit léger et simple à utiliser, xml.etree offre une fonctionnalité puissante pour la gestion des données de l'élément racine XML. Il fournit un moyen d'analyser des documents de données XML à partir de fichiers, de chaînes ou d'objets de type fichier. Le fichier XML analysé en résultant est présenté comme un arbre d'objets Element. Les développeurs peuvent naviguer dans cet arbre, accéder aux éléments et aux attributs, et effectuer diverses actions telles que l'édition, la suppression ou l'ajout d'éléments.

Caractéristiques de xml.etree
Analyse des documents XML
Des méthodes d'analyse de documents XML à partir de chaînes de caractères, de fichiers ou d'objets de type fichier sont disponibles dans xml.etree. Le matériel XML peut être traité à l'aide de la fonction parse(), qui produit également un objet ElementTree représentant le document XML analysé avec un objet élément valide.
Navigation dans les arbres XML
Les développeurs peuvent utiliser xml.etree pour parcourir les éléments d'un arbre de déclaration XML à l'aide de fonctions telles que find(), findall() et iter() une fois que le document a été traité. Accéder à certains éléments en fonction de balises, d'attributs ou d'expressions XPath est rendu simple par ces approches.
Modification des documents XML
Dans un document XML, il existe des moyens d'ajouter, de modifier et de supprimer des composants et des attributs en utilisant xml.etree. Modifier par programmation la structure et le contenu des données intrinsèquement hiérarchiques de l'arbre XML permet la modification, les mises à jour et les transformations des données.
Sérialisation des documents XML
xml.etree permet la sérialisation d'arbres XML en chaînes de caractères ou en objets de type fichier à l'aide de fonctions comme ElementTree.write() après modification d'un document XML. Cela permet aux développeurs de créer ou de modifier des arbres XML et de produire un résultat XML à partir de ceux-ci.
Prise en charge XPath
La prise en charge de XPath, un langage de requête permettant de choisir des nœuds dans un document XML, est fournie par xml.etree. Les développeurs peuvent effectuer des activités sophistiquées de récupération et de manipulation de données en utilisant des expressions XPath pour interroger et filtrer des éléments au sein d'un arbre XML.
Analyse itérative
Au lieu de charger l'intégralité du document en mémoire en une seule fois, les développeurs peuvent traiter les documents XML de manière séquentielle grâce à la prise en charge de l'analyse itérative par xml.etree. Ceci est très utile pour gérer efficacement de grands fichiers XML.
Support des espaces de noms
Les développeurs peuvent travailler avec des documents XML qui utilisent des espaces de noms pour l'identification des éléments et des attributs en utilisant la prise en charge des espaces de noms XML par xml.etree. Il offre des moyens de résoudre les préfixes d'espaces de noms XML par défaut et de spécifier des espaces de noms au sein d'un document XML.
Gestion des erreurs
Les capacités de gestion des erreurs pour les documents XML incorrects et les erreurs d'analyse sont incluses dans xml.etree. Il propose des techniques de gestion et de capture des erreurs, garantissant la fiabilité et la robustesse lors du travail avec des données XML.
Compatibilité et portabilité
Étant donné que xml.etree est un composant de la bibliothèque standard Python, il peut être utilisé immédiatement dans les programmes Python sans nécessiter d'installations supplémentaires. Il est portable et compatible avec de nombreux environnements Python car il fonctionne à la fois sous Python 2 et Python 3.
Créer et configurer xml.etree
Créer un document XML
En construisant des objets qui représentent les éléments de l'arbre XML et en les attachant à un élément racine, vous pouvez générer un document XML. Voici une illustration de la manière de créer des données XML :
import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Create a book element as a child of the root
book1 = ET.SubElement(root, "book")
book1.set("id", "1")
# Add child elements to the book
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Create another book element
book2 = ET.SubElement(root, "book")
book2.set("id", "2")
# Add child elements to the second book
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create an ElementTree object from the root element
tree = ET.ElementTree(root)import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Create a book element as a child of the root
book1 = ET.SubElement(root, "book")
book1.set("id", "1")
# Add child elements to the book
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Create another book element
book2 = ET.SubElement(root, "book")
book2.set("id", "2")
# Add child elements to the second book
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create an ElementTree object from the root element
tree = ET.ElementTree(root)Écrire un document XML dans un fichier
La fonction write() de l'objet ElementTree peut être utilisée pour écrire le fichier XML :
# Write XML document to file
tree.write("catalog.xml")# Write XML document to file
tree.write("catalog.xml")Cela créera un document XML dans un fichier appelé "catalog.xml".
Analyser un document XML
ElementTree analyse les données XML à l'aide de la fonction parse() :
# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()Cela analysera le document XML "catalog.xml", donnant l'élément racine de l'arbre XML.
Accéder aux éléments et aux attributs
En utilisant une variété de méthodes et de propriétés offertes par les objets Element, vous pouvez accéder aux éléments et aux attributs du document XML. Par exemple, pour visualiser le titre du premier livre :
# Access the title of the first book
first_book_title = root[0].find("title").text
print("Title of the first book:", first_book_title)# Access the title of the first book
first_book_title = root[0].find("title").text
print("Title of the first book:", first_book_title)Modifier le document XML
Le document XML peut être modifié en ajoutant, changeant ou supprimant des composants et des attributs. Pour modifier l'auteur du deuxième livre, par exemple :
# Modify the author of the second book
root[1].find("author").text = "Alice Smith"# Modify the author of the second book
root[1].find("author").text = "Alice Smith"Sérialiser un document XML
La fonction tostring() du module ElementTree peut être utilisée pour sérialiser le document XML en une chaîne de caractères :
# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)Commencer avec IronPDF
Qu'est-ce qu'IronPDF ?
IronPDF est une puissante bibliothèque .NET pour créer, éditer et modifier des documents PDF par programmation en C#, VB.NET et d'autres langages .NET. Il offre aux développeurs un ensemble complet de fonctionnalités pour créer dynamiquement des PDF de haute qualité, ce qui en fait un choix populaire pour de nombreuses applications.
Caractéristiques clés d'IronPDF
Génération de PDF : grâce à IronPDF, les programmeurs peuvent créer de nouveaux documents PDF ou convertir des balises HTML, du texte, des images et d'autres formats de fichiers existants en PDF. Cette fonctionnalité est très utile pour créer dynamiquement des rapports, des factures, des reçus et d'autres documents.
Conversion HTML en PDF : IronPDF permet aux développeurs de transformer facilement des documents HTML, y compris les styles de JavaScript et CSS, en fichiers PDF. Cela permet la création de PDF à partir de pages Web, de contenu généré dynamiquement et de modèles HTML.
Modification et édition de documents PDF : IronPDF offre un ensemble complet de fonctionnalités pour modifier et altérer des documents PDF préexistants. Les développeurs peuvent fusionner plusieurs fichiers PDF, les séparer en d'autres documents, supprimer des pages et ajouter des signets, des annotations et des filigranes, entre autres fonctionnalités, pour personnaliser les PDF selon leurs besoins.
IronPDF et xml.etree combinés
Cette section démontrera comment générer des documents PDF avec IronPDF basé sur des données XML analysées. En tirant parti des forces du XML et de IronPDF, vous pouvez transformer efficacement des données structurées en documents PDF professionnels. Voici un guide détaillé :
Installation
Assurez-vous que IronPDF est installé avant de commencer. Il peut être installé via pip :
pip install ironpdf
Générer un document PDF avec IronPDF en utilisant XML analysé
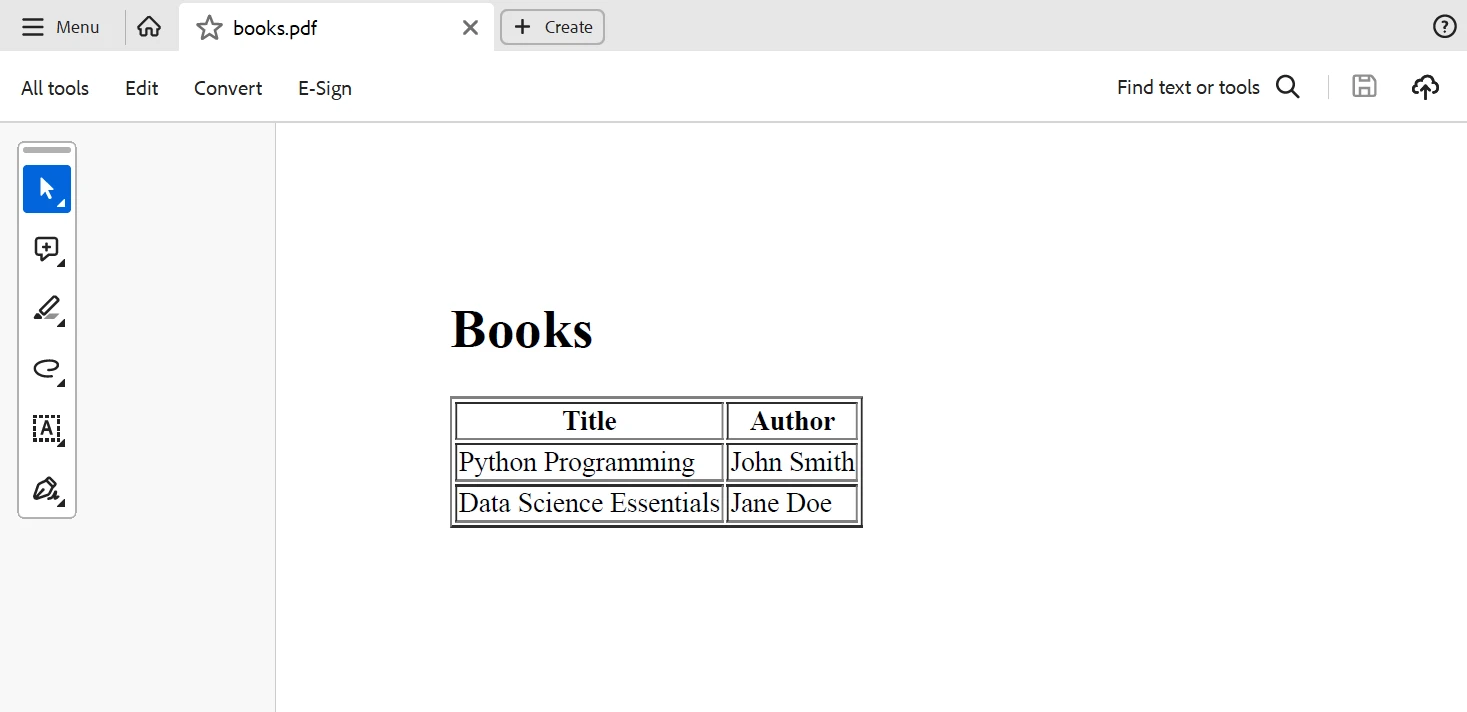
IronPDF peut être utilisé pour créer un document PDF basé sur les données extraites de l'XML après qu'elles aient été traitées. Créons un document PDF avec un tableau qui contient les noms des livres et des auteurs :
from ironpdf import *
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Loop through books to add each to the table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
html_content += """
</table>
</body>
</html>
"""
# Generate PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
pdf.SaveAs("books.pdf")from ironpdf import *
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Loop through books to add each to the table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
html_content += """
</table>
</body>
</html>
"""
# Generate PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
pdf.SaveAs("books.pdf")Ce code Python génère un tableau HTML contenant les noms des livres et des auteurs, qu'IronPDF transforme ensuite en un document PDF. Ci-dessous se trouve la sortie générée par le code ci-dessus.
Sortie
Conclusion
En conclusion, la combinaison d' IronPDF et de Python offre une solution robuste aux développeurs cherchant à analyser des données XML et à produire des documents PDF dynamiques basés sur les données analysées. Grâce à l'API Python fiable et efficace xml.etree, les développeurs peuvent facilement extraire des données structurées à partir de documents XML. IronPDF améliore cela en fournissant la capacité de créer des documents PDF esthétiquement agréables et modifiables à partir des données XML traitées.
Ensemble, Python et IronPDF permettent aux développeurs d'automatiser les tâches de traitement des données, d'extraire des informations précieuses à partir de sources de données XML et de les présenter de manière Professional et visuellement attrayante grâce à des documents PDF. Qu'il s'agisse de générer des rapports, de créer des factures ou de produire de la documentation, la synergie entre xml.etree Python et IronPDF ouvre de nouvelles possibilités dans le traitement des données et la génération de documents.
IronPDF est proposé à un prix raisonnable lorsqu'il est acheté en pack, offrant un excellent rapport qualité-prix avec une licence à vie (par exemple, $999 pour un achat unique pour plusieurs systèmes). Les utilisateurs sous licence ont accès à un support technique en ligne 24h/24 et 7j/7. Pour plus de détails sur le tarif, veuillez vous rendre sur ce site Web. Visitez cette page pour en savoir plus sur les produits Iron Software.
















