
Przewodnik po Python Pandas dla Data Science
Pandas to popularne narzędzie do analizy danych w języku programowania Python, znane z łatwości obsługi i wszechstronności w pracy z danymi tabelarycznymi. Ten przewodnik przeprowadzi Cię przez podstawy korzystania z Pandas, skupiając się na praktycznych przykładach i skutecznych technikach manipulacji danymi oraz ich analizy.
Zrozumienie DataFrame: rdzeń biblioteki Pandas
1. Dostęp do danych w Pandas
Podstawową strukturą w Pandas jest DataFrame, potężne narzędzie do analizy i manipulacji danymi. Na początek przyjrzyjmy się, jak uzyskać dostęp do danych w ramach DataFrame.
1.1 Wczytanie danych z pliku CSV
Na przykład, jeśli masz plik CSV zawierający dane, możesz załadować go do DataFrame i rozpocząć manipulowanie nim. Poniższy kod pokazuje, jak wczytać dane z pliku CSV:
import pandas as pd
# Load data from a CSV file into a DataFrame
df = pd.read_csv('your_file.csv')import pandas as pd
# Load data from a CSV file into a DataFrame
df = pd.read_csv('your_file.csv')1.2 Dostęp do danych w kolumnach
Po załadowaniu istnieje kilka sposobów uzyskania dostępu do danych w DataFrame. Dostęp do danych kolumny można uzyskać, używając nazwy kolumny. Na przykład poniższy kod uzyskuje dostęp do danych z kolumny o nazwie "data":
# Access data from a column named 'data'
column_data = df['data']# Access data from a column named 'data'
column_data = df['data']1.3 Dostęp do danych wierszowych
Podobnie, można również uzyskać dostęp do danych wierszy za pomocą indeksów wierszy lub warunków:
# Accesses the first row of the DataFrame
row_data = df.loc[0]# Accesses the first row of the DataFrame
row_data = df.loc[0]2. Obsługa wartości null w DataFrames
Częstym problemem w analizie danych jest radzenie sobie z wartościami null. Pandas zapewnia solidne metody do obsługi tych zadań. Kod wypełnia wartości null określoną wartością lub można usunąć wiersze lub kolumny zawierające wartości null. Oto przykład kodu pokazujący, jak wypełnić wartości null:
# Fill null values in the DataFrame with 0
df.fillna(0, inplace=True)# Fill null values in the DataFrame with 0
df.fillna(0, inplace=True)3. Tworzenie i edycja kolumn
DataFrames są wszechstronne, umożliwiając tworzenie nowych kolumn. Niezależnie od tego, czy chodzi o nową kolumnę typu integer, czy kolumnę wyprowadzoną z istniejących danych, proces ten jest prosty. Oto przykład dodania nowej kolumny do DataFrame:
# Add a new column 'new_column' by multiplying an existing column by 10
df['new_column'] = df['existing_column'] * 10# Add a new column 'new_column' by multiplying an existing column by 10
df['new_column'] = df['existing_column'] * 10Można również filtrować dane na podstawie warunków. Na przykład, jeśli chcesz utworzyć nową kolumnę z danymi z kolumny o nazwie "column_named_data", których wartość jest większa od określonej wartości:
# Create a new column 'filtered_data' based on the condition
df['filtered_data'] = df[df['column_named_data'] > value]# Create a new column 'filtered_data' based on the condition
df['filtered_data'] = df[df['column_named_data'] > value]Zaawansowane techniki manipulacji danymi
1. Grupowanie i agregowanie danych
Pandas doskonale sprawdza się w grupowaniu i agregowaniu danych. Poniższy kod wykorzystuje metodę groupby i grupuje dane według określonej kolumny oraz oblicza funkcje agregujące, takie jak średnia, suma itp.:
# Group data by 'column_name' and calculate the mean
grouped_data = df.groupby('column_name').mean()# Group data by 'column_name' and calculate the mean
grouped_data = df.groupby('column_name').mean()2. Dane dotyczące daty i godziny
Obsługa daty i godziny ma kluczowe znaczenie w wielu zestawach danych. Jeśli Twoja ramka danych (DataFrame) zawiera kolumnę z datą, Pandas ułatwia zadania takie jak filtrowanie według daty, agregowanie według miesiąca lub roku itp. Oto podstawowy przykład:
# Convert 'date_column' to datetime format
df['date_column'] = pd.to_datetime(df['date_column'])# Convert 'date_column' to datetime format
df['date_column'] = pd.to_datetime(df['date_column'])3. Niestandardowe operacje na danych
W przypadku bardziej złożonych potrzeb związanych z manipulacją danymi, Pandas pozwala na pisanie niestandardowych funkcji i stosowanie ich do DataFrame. Jest to szczególnie przydatne w scenariuszach wymagających podejścia opartego na zapytaniach zintegrowanych z językiem.
def custom_function(row):
# Perform custom manipulation on each row
return modified_row
# Apply custom function to each row in the DataFrame
df = df.apply(custom_function, axis=1)def custom_function(row):
# Perform custom manipulation on each row
return modified_row
# Apply custom function to each row in the DataFrame
df = df.apply(custom_function, axis=1)Wizualizacja i wyświetlanie danych
Pandas dobrze integruje się z bibliotekami takimi jak Matplotlib i Seaborn do wizualizacji danych. Wyświetlanie danych w formacie wizualnym może być tak proste, jak pokazano w poniższym kodzie źródłowym:
import matplotlib.pyplot as plt
# Plot a bar chart for data visualization
df.plot(kind='bar')
plt.show()import matplotlib.pyplot as plt
# Plot a bar chart for data visualization
df.plot(kind='bar')
plt.show()Integracja IronPDF z Pandas w celu ulepszonej analizy danych w języku Python
Pandas, jak już wspomnieliśmy, to solidne narzędzie do manipulacji danymi i analizy w języku Python. Uzupełniając swoje możliwości, IronPDF, biblioteka opracowana przez Iron Software, oferuje dodatkowe funkcje, które mogą usprawnić procesy analizy danych, szczególnie w przypadku treści w formacie PDF.
IronPDF: przegląd
IronPDF to wszechstronna biblioteka PDF dla języka Python, służąca do tworzenia, edytowania i wyodrębniania treści PDF w ramach projektów realizowanych w tym języku. Jest zaprojektowany do pracy na różnych platformach, w tym Windows, Mac, Linux i środowiskach chmurowych, co czyni go odpowiednim wyborem dla różnorodnych projektów w języku Python. Ta biblioteka jest szczególnie wydajna w obsłudze plików PDF, oferując płynne działanie i wydajne przetwarzanie, co ma kluczowe znaczenie dla programistów pracujących z danymi PDF.
Synergia z Pandas
Integracja IronPDF z Pandas otwiera możliwości bardziej zaawansowanej obsługi danych i raportowania. Wyobraź sobie proces analityczny, w którym używasz biblioteki Pandas do manipulacji danymi i analizy, a następnie płynnie konwertujesz wyniki i wizualizacje na profesjonalnie sformatowany raport PDF za pomocą IronPDF. Ta integracja może znacznie usprawnić proces udostępniania i prezentowania wyników analizy danych.
Wnioski
Podsumowując, podczas gdy Pandas stanowi podstawę analizy danych, integracja IronPDF nadaje nowy wymiar procesowi analizy danych w języku Python. To połączenie nie tylko zwiększa wydajność procesów przetwarzania i analizy danych, ale także znacznie poprawia sposób ich prezentacji i udostępniania, co czyni je nieocenionym atutem dla analityków danych i naukowców korzystających z języka Python.
IronPDF dla użytkowników zainteresowanych zapoznaniem się z jego funkcjami przed dokonaniem zakupu.
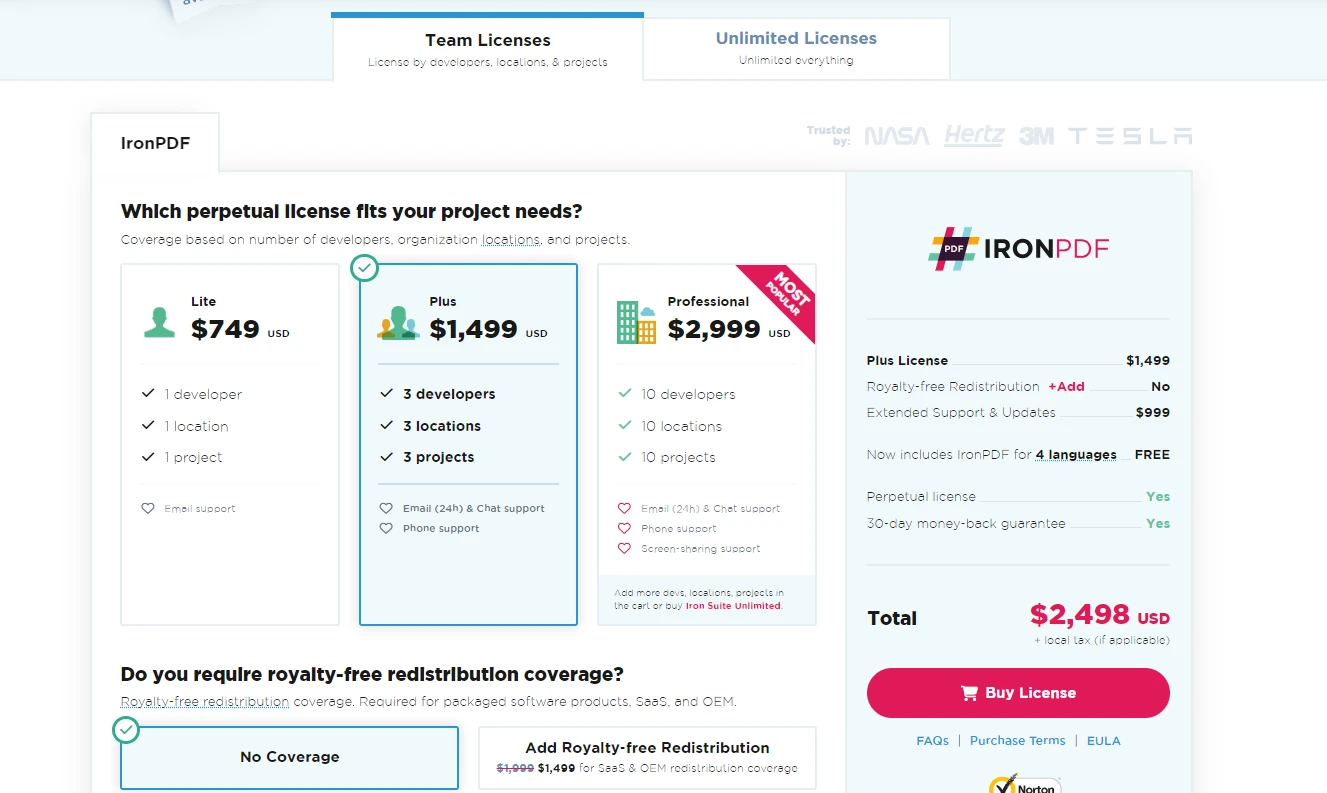
Osobom zainteresowanym zakupem pełnej licencji IronPDF umożliwia wybór planu najlepiej odpowiadającego potrzebom projektu i budżetowi.
















