
데이터 과학을 위한 Python 판다 가이드
판다스는 Python 프로그래밍 언어에서 널리 사용되는 데이터 분석 도구로, 사용 편의성과 표 형식 데이터 처리 능력의 탁월함으로 유명합니다. 이 가이드는 Pandas 사용의 필수 사항을 안내하며, 실용적인 예제와 효율적인 데이터 조작 및 분석 기법에 중점을 둡니다.
데이터프레임 이해하기: Pandas의 핵심
1. Pandas에서 데이터 접근하기
Pandas 의 주요 구조는 데이터 분석 및 조작을 위한 강력한 도구인 DataFrame입니다. 먼저, DataFrame 내의 데이터에 접근하는 방법을 살펴보겠습니다.
1.1 CSV 파일에서 데이터 불러오기
예를 들어, 데이터가 포함된 CSV 파일이 있는 경우, 해당 파일을 DataFrame으로 불러와서 조작을 시작할 수 있습니다. 아래 코드는 CSV 파일에서 데이터를 불러오는 방법을 보여줍니다.
import pandas as pd
# Load data from a CSV file into a DataFrame
df = pd.read_csv('your_file.csv')import pandas as pd
# Load data from a CSV file into a DataFrame
df = pd.read_csv('your_file.csv')1.2 열 데이터 액세스
일단 로드되면 DataFrame의 데이터에 접근하는 방법은 여러 가지가 있습니다. 열 이름을 사용하여 열 데이터에 접근할 수 있습니다. 예를 들어, 아래 코드는 'data'라는 이름의 열에서 데이터를 가져옵니다.
# Access data from a column named 'data'
column_data = df['data']# Access data from a column named 'data'
column_data = df['data']1.3 행 데이터 액세스
마찬가지로 행 인덱스 또는 조건을 사용하여 행 데이터에 접근할 수도 있습니다.
# Accesses the first row of the DataFrame
row_data = df.loc[0]# Accesses the first row of the DataFrame
row_data = df.loc[0]2. 데이터프레임에서 null 값 처리하기
데이터 분석에서 흔히 발생하는 문제 중 하나는 결측값 처리입니다. Pandas는 이러한 문제를 처리하기 위한 강력한 방법을 제공합니다. 이 코드는 null 값을 지정된 값으로 채우거나, null 값이 있는 행 또는 열을 삭제할 수 있습니다. 다음은 null 값을 채우는 코드 예제입니다.
# Fill null values in the DataFrame with 0
df.fillna(0, inplace=True)# Fill null values in the DataFrame with 0
df.fillna(0, inplace=True)3. 열 생성 및 조작
데이터프레임은 새로운 열을 생성할 수 있다는 점에서 매우 다재다능합니다. 새로운 정수 열을 추가하든 기존 데이터에서 파생된 열을 추가하든 과정은 간단합니다. 다음은 DataFrame에 새 열을 추가하는 예입니다.
# Add a new column 'new_column' by multiplying an existing column by 10
df['new_column'] = df['existing_column'] * 10# Add a new column 'new_column' by multiplying an existing column by 10
df['new_column'] = df['existing_column'] * 10조건을 기준으로 데이터를 필터링할 수도 있습니다. 예를 들어, 'column_named_data'라는 열의 데이터 중 특정 값보다 큰 데이터로 새 열을 만들려면 다음과 같이 하면 됩니다.
# Create a new column 'filtered_data' based on the condition
df['filtered_data'] = df[df['column_named_data'] > value]# Create a new column 'filtered_data' based on the condition
df['filtered_data'] = df[df['column_named_data'] > value]고급 데이터 조작 기술
1. 데이터 그룹화 및 집계
Pandas는 데이터 그룹화와 집계에서 뛰어납니다. 다음 코드는 groupby 메서드를 사용하여 지정된 열을 기준으로 데이터를 그룹화하고 평균, 합계 등의 집계 함수를 계산합니다.
# Group data by 'column_name' and calculate the mean
grouped_data = df.groupby('column_name').mean()# Group data by 'column_name' and calculate the mean
grouped_data = df.groupby('column_name').mean()2. 날짜 및 시간 데이터
많은 데이터 세트에서 날짜와 시간을 처리하는 것은 매우 중요합니다. 데이터프레임에 날짜 열이 있는 경우 Pandas는 날짜별 필터링, 월별 또는 연도별 집계 등의 작업을 간소화합니다. 다음은 기본적인 예입니다.
# Convert 'date_column' to datetime format
df['date_column'] = pd.to_datetime(df['date_column'])# Convert 'date_column' to datetime format
df['date_column'] = pd.to_datetime(df['date_column'])3. 사용자 지정 데이터 조작
보다 복잡한 데이터 조작이 필요한 경우, Pandas를 사용하면 사용자 지정 함수를 작성하고 이를 DataFrame에 적용할 수 있습니다. 이는 언어 통합형 쿼리 방식이 필요한 시나리오에 특히 유용합니다.
def custom_function(row):
# Perform custom manipulation on each row
return modified_row
# Apply custom function to each row in the DataFrame
df = df.apply(custom_function, axis=1)def custom_function(row):
# Perform custom manipulation on each row
return modified_row
# Apply custom function to each row in the DataFrame
df = df.apply(custom_function, axis=1)데이터 시각화 및 표시
Pandas는 데이터 시각화를 위해 Matplotlib 및 Seaborn과 같은 라이브러리와 잘 통합됩니다. 데이터를 시각적인 형식으로 표시하는 것은 다음 소스 코드에서 보여주는 것처럼 간단할 수 있습니다.
import matplotlib.pyplot as plt
# Plot a bar chart for data visualization
df.plot(kind='bar')
plt.show()import matplotlib.pyplot as plt
# Plot a bar chart for data visualization
df.plot(kind='bar')
plt.show()Python에서 IronPDF 와 Pandas를 통합하여 데이터 분석 기능을 향상시키는 방법
앞서 논의했듯이, Pandas는 Python에서 데이터를 조작하고 분석하는 데 매우 강력한 도구입니다. Iron Software 에서 개발한 라이브러리인 IronPDF 는 기존 기능을 보완하여 특히 PDF 콘텐츠를 다룰 때 데이터 분석 워크플로를 향상시킬 수 있는 추가 기능을 제공합니다.
IronPDF: 개요
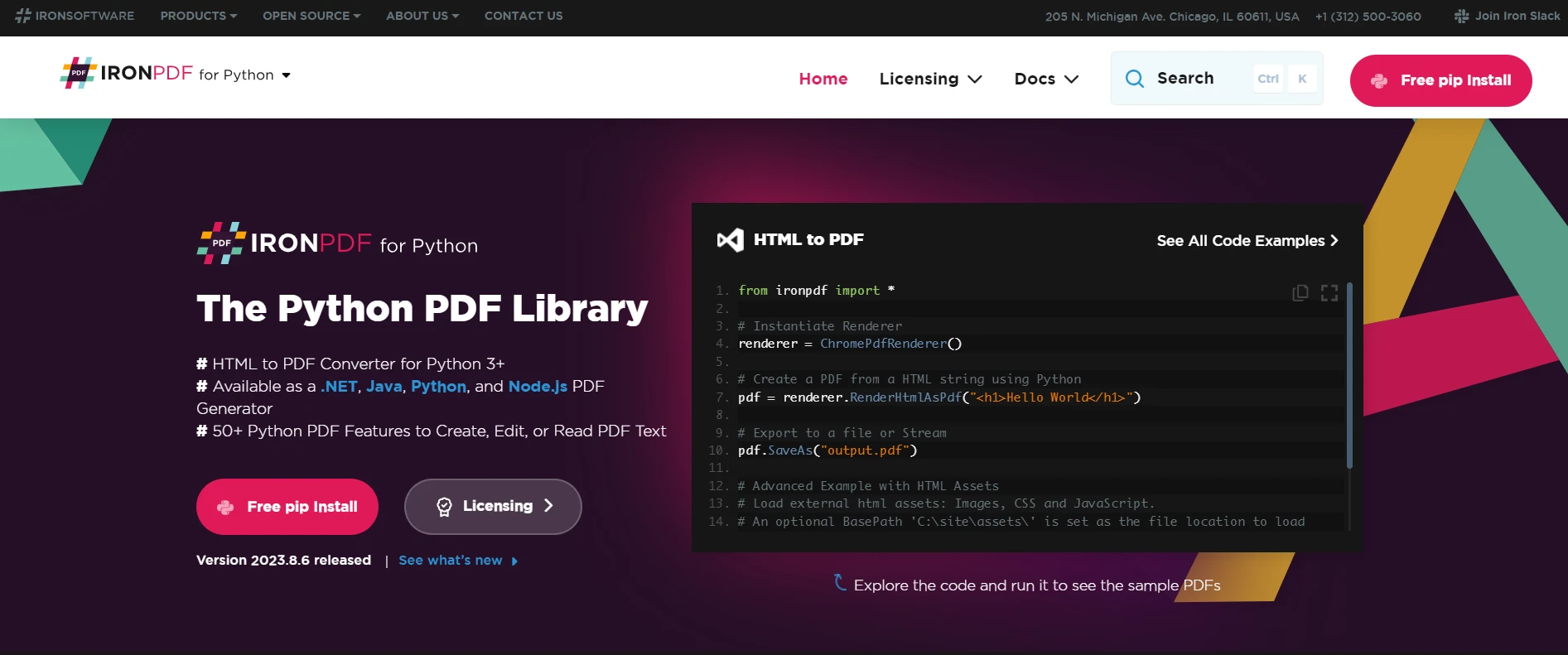
IronPDF 는 Python 프로젝트 내에서 PDF 콘텐츠를 생성, 편집 및 추출하는 데 사용할 수 있는 다목적 Python PDF 라이브러리입니다. 이 제품은 Windows, Mac, Linux 및 클라우드 환경을 포함한 다양한 플랫폼에서 작동하도록 설계되어 다양한 Python 프로젝트에 적합합니다. 이 라이브러리는 특히 PDF 파일 처리에 탁월하며, 원활한 사용 경험과 효율적인 처리를 제공하여 PDF 데이터를 다루는 개발자에게 매우 중요합니다.
판다와의 시너지 효과
IronPDF Pandas와 통합하면 더욱 고급스러운 데이터 처리 및 보고 기능을 활용할 수 있는 가능성이 열립니다. 데이터 조작 및 분석에 Pandas를 사용한 다음, IronPDF 사용하여 결과와 시각화를 전문적인 형식의 PDF 보고서로 원활하게 변환하는 분석 워크플로를 상상해 보세요. 이러한 통합을 통해 데이터 분석 결과를 공유하고 발표하는 프로세스를 크게 간소화할 수 있습니다.
결론
결론적으로, Pandas는 데이터 분석의 기반을 제공하지만, IronPDF 통합하면 Python을 사용한 데이터 분석 워크플로에 새로운 차원을 더할 수 있습니다. 이러한 조합은 데이터 조작 및 분석 프로세스의 효율성을 높일 뿐만 아니라 데이터의 표현 및 공유 방식을 크게 개선하여 Python 기반 데이터 분석가와 과학자에게 매우 귀중한 자산이 됩니다.
구매 전에 IronPDF 의 기능을 살펴보고 싶은 사용자를 위한 안내입니다.
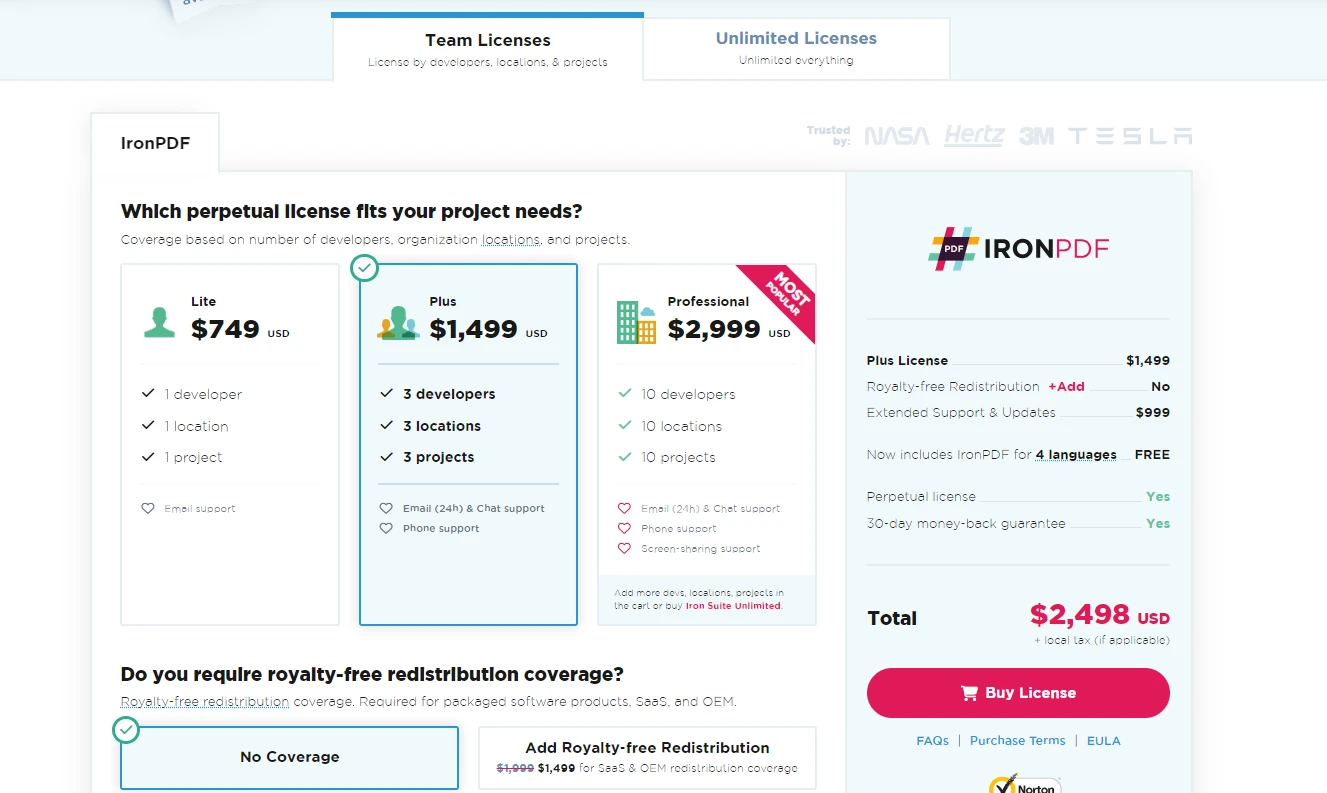
정식 라이선스를 구매하려는 사용자를 위해 IronPDF 프로젝트 요구 사항과 예산에 가장 적합한 플랜을 선택할 수 있도록 지원합니다.
















