
Guia Pandas em Python para Ciência de Dados
O Pandas é uma ferramenta popular de análise de dados na linguagem de programação Python, reconhecida por sua facilidade de uso e versatilidade no tratamento de dados tabulares. Este guia irá apresentar os conceitos essenciais da utilização do Pandas, com foco em exemplos práticos e técnicas eficientes para manipulação e análise de dados.
Entendendo o DataFrame: O Núcleo do Pandas
1. Acessando dados no Pandas
A estrutura principal do Pandas é o DataFrame, uma ferramenta poderosa para análise e manipulação de dados. Para começar, vamos explorar como acessar dados dentro de um DataFrame .
1.1 Carregar dados de um arquivo CSV
Por exemplo, se você tiver um arquivo CSV contendo seus dados, poderá carregá-lo em um DataFrame e começar a manipulá-lo. O código abaixo demonstra como carregar dados de um arquivo CSV:
import pandas as pd
# Load data from a CSV file into a DataFrame
df = pd.read_csv('your_file.csv')import pandas as pd
# Load data from a CSV file into a DataFrame
df = pd.read_csv('your_file.csv')1.2 Acessar dados da coluna
Uma vez carregado, existem várias maneiras de acessar os dados no DataFrame. Você pode acessar os dados da coluna usando o nome da coluna. Por exemplo, o código abaixo acessa dados de uma coluna chamada 'data':
# Access data from a column named 'data'
column_data = df['data']# Access data from a column named 'data'
column_data = df['data']1.3 Acessar dados de linha
Da mesma forma, você também pode acessar os dados das linhas usando índices de linha ou condições:
# Accesses the first row of the DataFrame
row_data = df.loc[0]# Accesses the first row of the DataFrame
row_data = df.loc[0]2. Lidando com valores nulos em DataFrames
Um problema comum na análise de dados é lidar com valores nulos. O Pandas oferece métodos robustos para lidar com esses problemas. O código preenche os valores nulos com um valor especificado, ou você pode remover linhas ou colunas com valores nulos. Aqui está um exemplo de código de como preencher valores nulos:
# Fill null values in the DataFrame with 0
df.fillna(0, inplace=True)# Fill null values in the DataFrame with 0
df.fillna(0, inplace=True)3. Criando e manipulando colunas
Os DataFrames são versáteis, permitindo a criação de novas colunas. Quer se trate de uma nova coluna de números inteiros ou de uma coluna derivada de dados existentes, o processo é simples. Aqui está um exemplo de como adicionar uma nova coluna a um DataFrame:
# Add a new column 'new_column' by multiplying an existing column by 10
df['new_column'] = df['existing_column'] * 10# Add a new column 'new_column' by multiplying an existing column by 10
df['new_column'] = df['existing_column'] * 10Você também pode filtrar os dados com base em condições. Por exemplo, se você quiser criar uma nova coluna com dados de uma coluna chamada 'column_named_data' maiores que um determinado valor:
# Create a new column 'filtered_data' based on the condition
df['filtered_data'] = df[df['column_named_data'] > value]# Create a new column 'filtered_data' based on the condition
df['filtered_data'] = df[df['column_named_data'] > value]Técnicas avançadas de manipulação de dados
1. Agrupamento e agregação de dados
O Pandas se destaca em agrupar e agregar dados. O código a seguir utiliza o método groupby para agrupar dados por uma coluna específica e calcular funções de agregação como média, soma, etc.:
# Group data by 'column_name' and calculate the mean
grouped_data = df.groupby('column_name').mean()# Group data by 'column_name' and calculate the mean
grouped_data = df.groupby('column_name').mean()2. Dados de data e hora
O tratamento de data e hora é crucial em muitos conjuntos de dados. Se o seu DataFrame tiver uma coluna de data, o Pandas simplifica tarefas como filtrar por data, agregar por mês ou ano, etc. Aqui está um exemplo básico:
# Convert 'date_column' to datetime format
df['date_column'] = pd.to_datetime(df['date_column'])# Convert 'date_column' to datetime format
df['date_column'] = pd.to_datetime(df['date_column'])3. Manipulações de Dados Personalizadas
Para necessidades de manipulação de dados mais complexas, o Pandas permite que você escreva funções personalizadas e as aplique ao seu DataFrame. Isso é particularmente útil para cenários que exigem uma abordagem de consulta integrada à linguagem.
def custom_function(row):
# Perform custom manipulation on each row
return modified_row
# Apply custom function to each row in the DataFrame
df = df.apply(custom_function, axis=1)def custom_function(row):
# Perform custom manipulation on each row
return modified_row
# Apply custom function to each row in the DataFrame
df = df.apply(custom_function, axis=1)Visualização e Exibição de Dados
O Pandas integra-se bem com bibliotecas como Matplotlib e Seaborn para visualização de dados. Exibir dados em formato visual pode ser tão simples quanto demonstrado no código-fonte a seguir:
import matplotlib.pyplot as plt
# Plot a bar chart for data visualization
df.plot(kind='bar')
plt.show()import matplotlib.pyplot as plt
# Plot a bar chart for data visualization
df.plot(kind='bar')
plt.show()Integrando o IronPDF com o Pandas para uma análise de dados aprimorada em Python.
Como já discutimos, o Pandas é uma ferramenta robusta para manipulação e análise de dados em Python. Complementando suas capacidades, o IronPDF, uma biblioteca desenvolvida pela Iron Software, oferece funcionalidades adicionais que podem aprimorar os fluxos de trabalho de análise de dados, principalmente ao lidar com conteúdo em PDF.
IronPDF: Uma Visão Geral
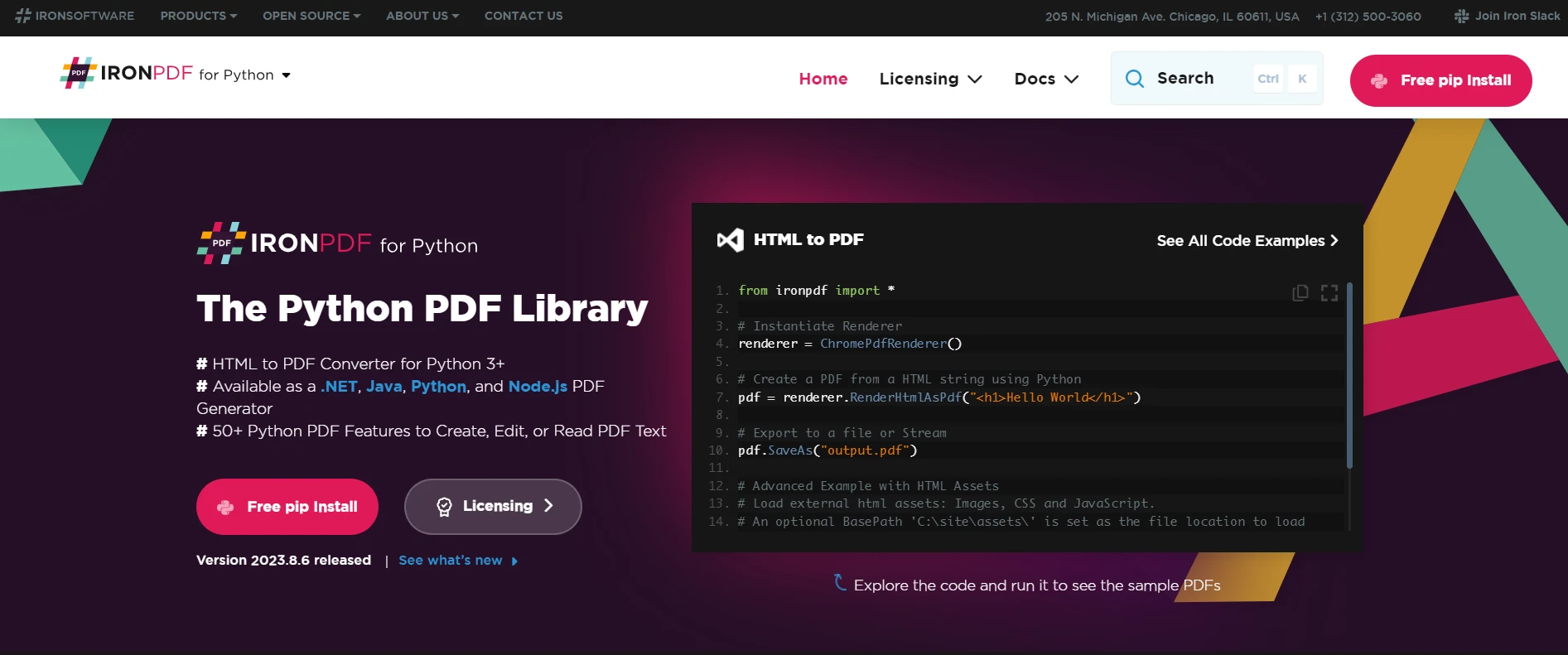
IronPDF é uma biblioteca Python versátil para criar, editar e extrair conteúdo de PDFs em projetos Python. Ele foi projetado para funcionar em diversas plataformas, incluindo Windows, Mac, Linux e ambientes de nuvem, tornando-o uma escolha adequada para vários projetos em Python. Esta biblioteca é particularmente poderosa no processamento de arquivos PDF, oferecendo uma experiência perfeita e um processamento eficiente, o que é crucial para desenvolvedores que trabalham com dados em PDF.
Sinergia com Pandas
A integração do IronPDF com o Pandas abre possibilidades para um processamento e geração de relatórios de dados mais avançados. Imagine um fluxo de trabalho de análise onde você usa o Pandas para manipulação e análise de dados e, em seguida, converte perfeitamente seus resultados e visualizações em um relatório PDF com formatação profissional usando o IronPDF. Essa integração pode agilizar significativamente o processo de compartilhamento e apresentação dos resultados da análise de dados.
Conclusão
Em conclusão, embora o Pandas forneça a base para a análise de dados, a integração do IronPDF adiciona uma nova dimensão ao fluxo de trabalho de análise de dados em Python. Essa combinação não apenas aumenta a eficiência dos processos de manipulação e análise de dados, mas também melhora significativamente a forma como os dados são apresentados e compartilhados, tornando-se um recurso inestimável para analistas e cientistas de dados que utilizam Python.
IronPDF para usuários interessados em explorar seus recursos antes de efetuar a compra.
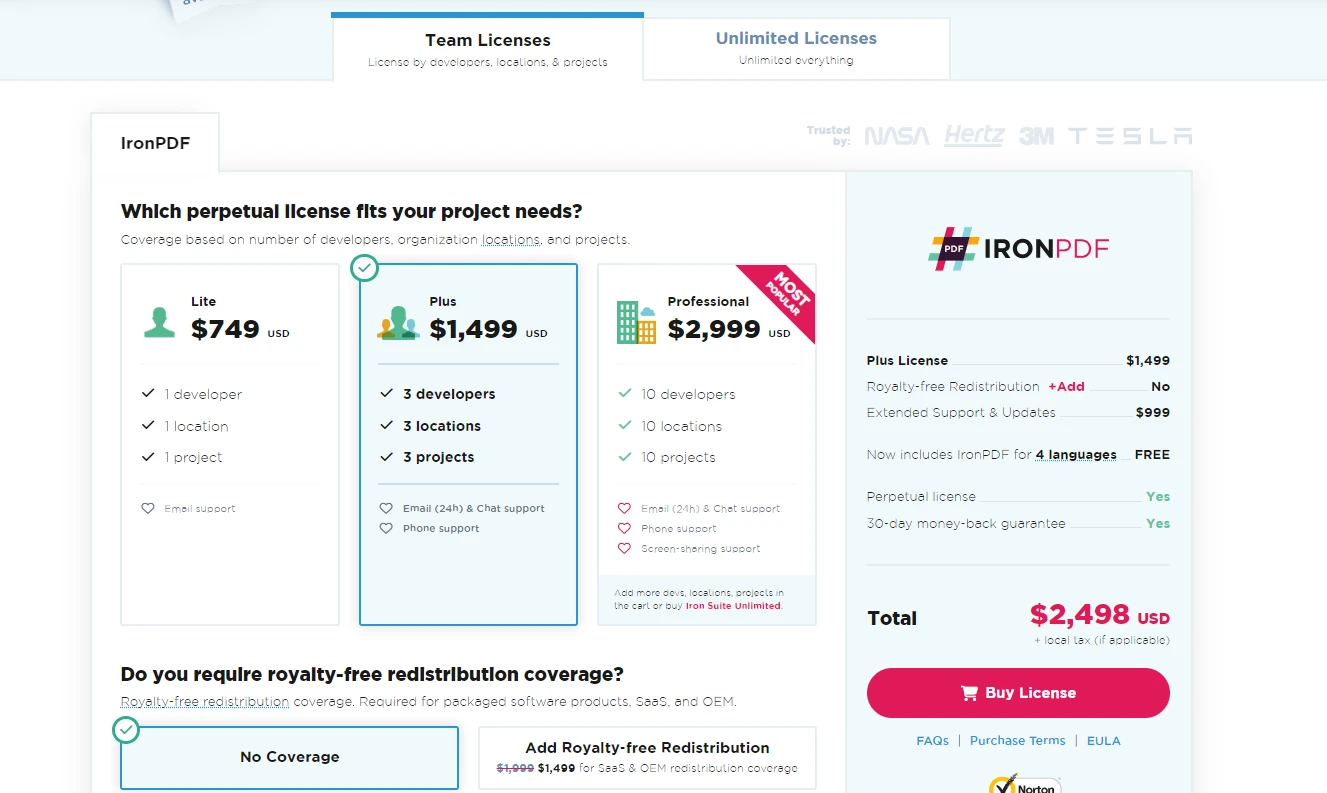
Para quem deseja adquirir uma licença completa, o IronPDF permite que os usuários escolham um plano que melhor se adapte às necessidades e ao orçamento do seu projeto.
















