
Distributed Computing with Python
Distributed Python
There is a greater need than ever for scalable and effective computing solutions in the rapidly changing field of technology. Distributed computing is becoming more and more necessary for jobs involving large volumes of distributed data processing, concurrent user requests, and computationally demanding tasks. In order to enable developers to fully utilize Distributed Python, we will examine its applications, principles, and tools in this post.
Dynamically producing and modifying PDF documents is a common requirement in the field of web development. The ability to create PDFs programmatically comes in handy for creating invoices, reports, and certificates on the fly.
Python's extensive ecology and versatility make it possible to deal with a multitude of PDF libraries. IronPDF is a formidable solution that helps developers fully utilize their infrastructure by streamlining the process of creating PDFs and enabling task parallelism and distributed computing too.
Understanding Distributed Python
Fundamentally, distributed Python is the process of dividing up computational work into smaller chunks and dividing them up among several nodes, or processing units. These nodes could be individual machines connected to a network, individual CPU cores inside a system, remote objects, remote functions, remote or function call execution, or even individual threads inside a single process. The objective is to increase performance, scalability, and fault tolerance by parallelizing the workload.
Python is a great choice for distributed computing workloads because of its ease of use, adaptability, and a robust ecosystem of libraries. Python offers an abundance of tools for distributed computing across all scales and use cases, ranging from strong frameworks like Celery, Dask, and Apache Spark to built-in modules like multiprocessing and threading.
Before delving into the specifics, let's examine the basic ideas and precepts that Distributed Python is built upon:
Parallelism vs. Concurrency
Parallelism entails carrying out multiple tasks at the same time, while concurrency is concerned with handling many tasks that may be moving forward concurrently but not necessarily simultaneously. Both parallelism and concurrency are covered by distributed Python, depending on the tasks at hand and the system's design.
Task Distribution
A key component of parallel and distributed computing is the distribution of work among several nodes or processing units. Effective work distribution is crucial for optimizing overall performance, efficiency, and resource usage, whether function execution in a computational program is parallelized across multiple cores or a data processing pipeline is divided into smaller stages.
Communication and Coordination
Effective communication and coordination between nodes are essential in distributed systems to facilitate the orchestration of remote function execution, intricate workflows, data exchange, and computation synchronization.
Distributed Python programs benefit from technologies like message queues, distributed data structures, and remote procedure calls (RPC) that enable smooth coordination and communication between remote and actual function execution.
Reliability and Error Prevention
The capacity of a system to accommodate growing workloads by adding nodes or processing units on different machines is referred to as scalability. Contrarily, fault tolerance refers to the design of systems that can withstand malfunctions such as machine failures, network partitions, and node crashes and still function dependably.
To guarantee the stability and resilience of distributed applications across multiple machines, distributed Python frameworks frequently include fault tolerance and automatic scaling features.
Applications of Distributed Python
Data Processing and Analytics: Large datasets may be processed in parallel using distributed Python frameworks like Apache Spark and Dask, which makes it possible to have distributed Python applications perform activities like batch processing, real-time stream processing, and machine learning at scale.
Web Development with Microservices: Scalable web applications and microservices architectures may be created with Python web frameworks like Flask and Django in conjunction with distributed task queues like Celery. Web applications may easily incorporate features like distributed caching, asynchronous request handling, and background job processing.
Scientific Computing and Simulation: High-performance computing (HPC) and parallel simulation over clusters of machines are made possible by Python's robust ecosystem of scientific libraries and distributed computing frameworks. Applications include financial risk analysis, climate modeling, machine learning applications, and simulations of physics and computational biology.
Edge Computing and the Internet of Things (IoT): As IoT devices and edge computing designs proliferate, Distributed Python becomes increasingly important for handling sensor data, coordinating edge computing processes, building distributed applications together, and putting distributed machine learning models into practice for modern applications at the edge.
Creation and Usage of Distributed Python
Distributed Machine Learning with Dask-ML
A strong library called Dask-ML expands the parallel computing framework Dask for jobs involving machine learning. Splitting up the task over several cores or processors in a cluster of machines makes it possible for Python developers to train and apply machine learning models on huge datasets in an effective distributed manner.
import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")Parallel Function Calls with Ray
With the help of the robust distributed computation framework Ray, you can execute Python functions or tasks concurrently on a cluster's many cores or computers. By utilizing the @ray.remote decorator, Ray enables you to specify functions as remote. After that, these remote tasks or operations can be executed asynchronously on the cluster's Ray workers.
import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()Getting Started
What is IronPDF?
We may create, modify, and render PDF documents within .NET programs with the help of the well-known IronPDF for .NET package. Working with PDFs can be done in many different ways: from creating new PDF documents from HTML content, photographs, or raw data, to extracting text and images from existing ones, converting HTML pages to PDFs, and adding text, images, and shapes to pre-existing ones.
IronPDF's simplicity and ease of use are two of its main benefits. Developers may begin producing PDFs within their .NET apps with ease because of its user-friendly API and extensive documentation. IronPDF's speed and efficiency are two more features that make it easier for developers to produce high-quality PDF documents quickly.
Some advantages of IronPDF:
- Creation of PDFs from raw data, images, and HTML.
- Extracting images and text from PDF files.
- Include headers, footers, and watermarks in PDF files.
- PDF files are password- and encryption-protected.
- The capability to fill out and sign documents electronically.
Distributed PDF Generation with IronPDF
Distributing tasks across numerous cores or computers within a cluster is made possible by distributed Python frameworks such as Dask and Ray. This makes it possible to execute complex tasks such as PDF generation in parallel across a cluster and leverage multiple cores within them, which drastically cuts down on the amount of time needed to create a big batch of PDFs.
Begin by installing IronPDF and the ray library using pip:
pip install ironpdf
pip install celerypip install ironpdf
pip install celeryHere is some conceptual Python code that demonstrates two methods using IronPDF and Python for distributed PDF generation:
Task Queue with a Central Worker
Central Worker (worker.py):
from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])Client Script (client.py):
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()Celery is the task queue system that we employ. The jobs are sent to the central worker (worker.py) along with data that contains HTML content. The function creates a PDF using IronPDF and saves it.
A task containing sample data is sent to the queue by the client script (client.py). This script can be changed to send other tasks in from different computers.
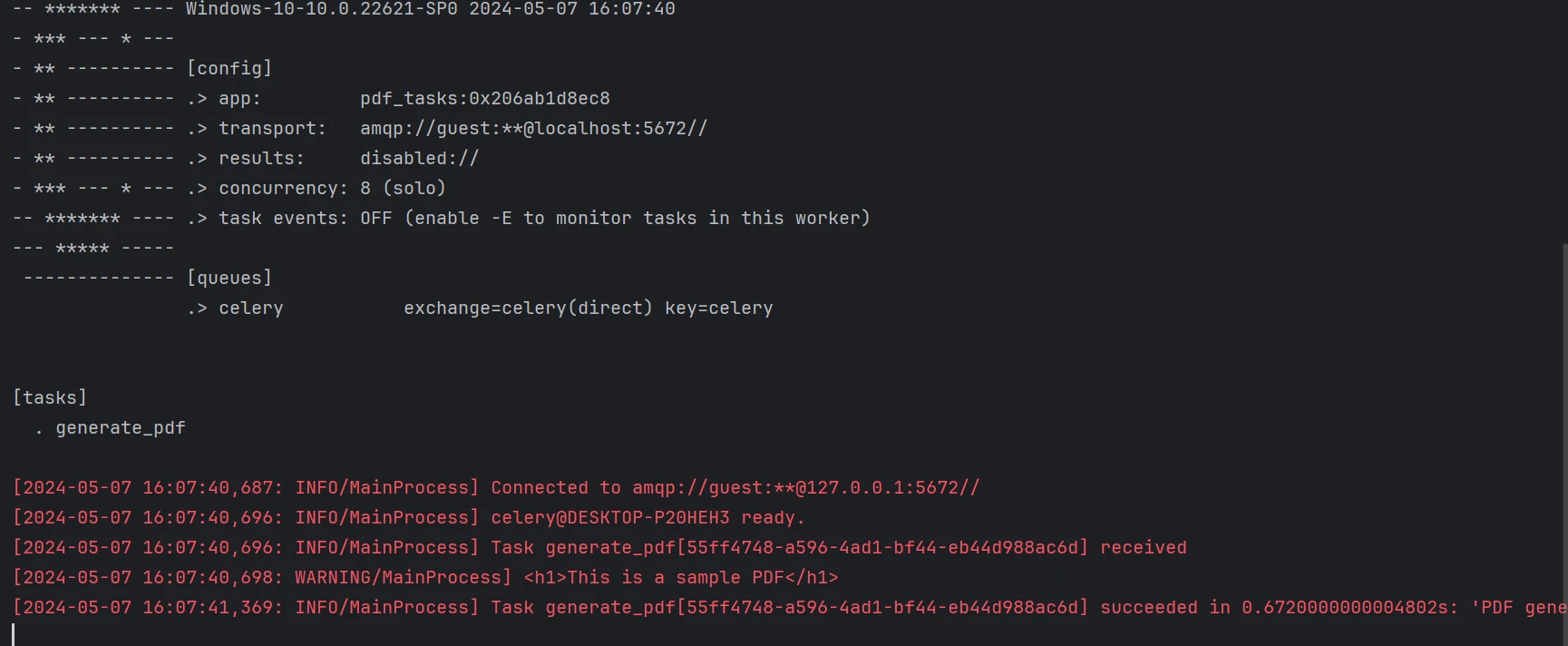
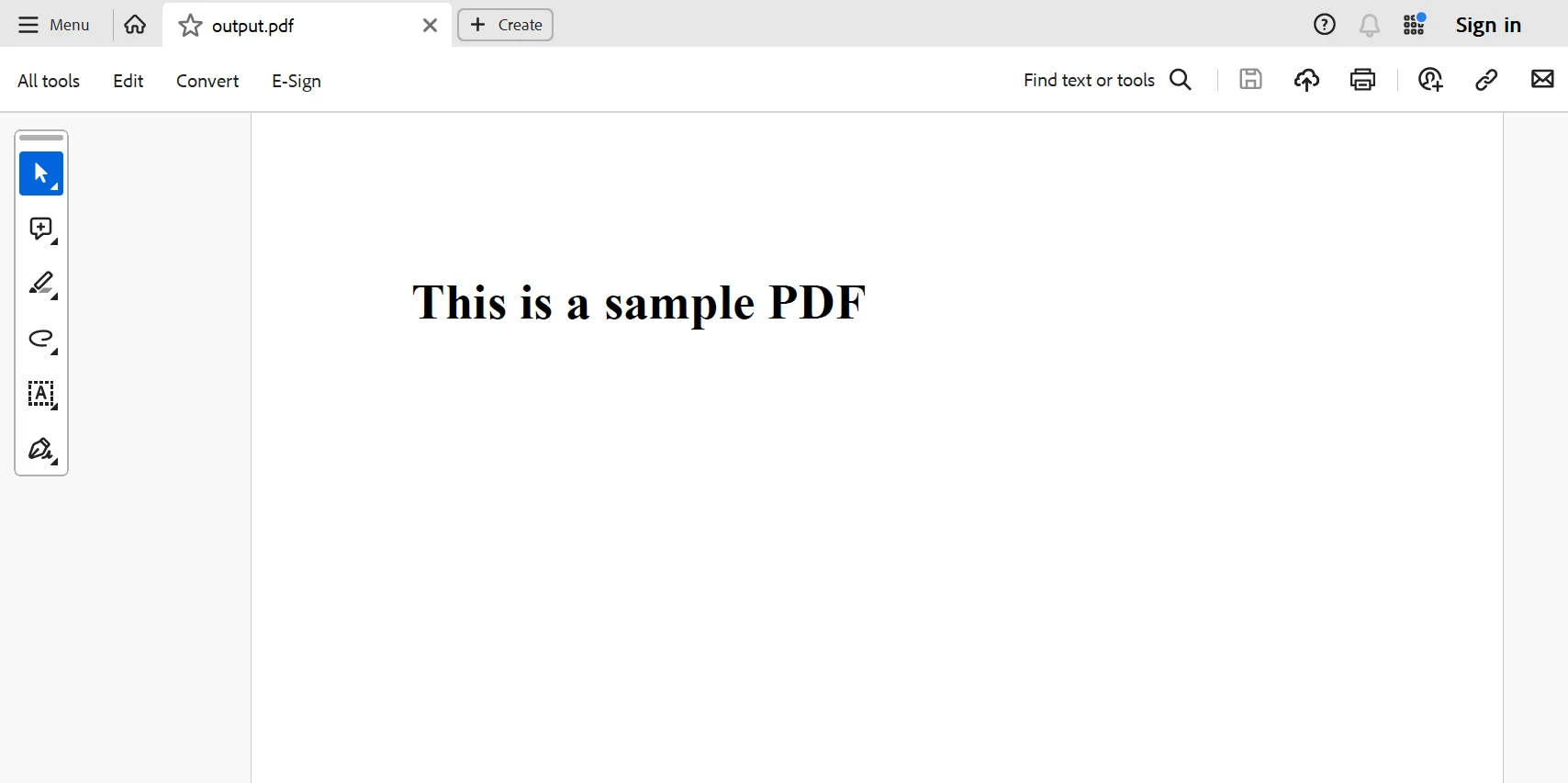
Below is the generated PDF from the above code.
Conclusion
Users of IronPDF who handle large-scale PDF creation activities might unleash enormous potential by utilizing distributed Python and libraries like Ray or Dask. When compared to executing code on a single machine, you can get significant speed improvements by spreading the same code workload across multiple cores and using it across multiple machines.
IronPDF may be enhanced from a powerful tool for creating PDFs on a single system to a reliable solution for effectively managing large datasets by utilizing the distributed Python programming language. To fully utilize IronPDF in your upcoming large-scale PDF creation project, investigate the Python libraries that are offered and try out these methods!
IronPDF is reasonably priced when purchased as a package and comes with a lifetime license. The package is a wonderful value, and for many systems, it can be purchased for just $799. It provides 24/7 online engineering support to license holders. For additional information on the charge, kindly visit the website. To find out more about the products that Iron Software produces, go to this page.
















