
pyarrow(開發人員工作原理)
PyArrow 是一個強大的程式庫,提供 Python 介面來使用 Apache Arrow 框架。 Apache Arrow 是一個跨語言的開發平台,專為記憶體中數據而設計。 它指定了一個標準化的語言獨立列式記憶體格式,用於平面和階層數據,為現代硬體上的高效分析操作組織格式。 PyArrow 基本上是實現為 Python 套件的 Apache Arrow Python 綁定。 PyArrow 促進了不同數據處理系統和程式語言之間的高效數據交換和互通性。 在本文稍後,我們還將學習由 Iron Software 開發的 PDF 生成程式庫 IronPDF。
PyArrow 的關鍵特性
列式記憶體格式:
PyArrow 使用列式記憶體格式,這對於記憶體中分析操作非常高效。 此格式允許更好的 CPU 快取利用和向量化操作,這使其對數據處理任務非常理想。 由於其列式特性,PyArrow 能夠高效地讀寫 parquet 文件結構。
- 互通性:PyArrow 的主要優勢之一是它能夠促進不同程式語言和系統之間的數據交換,無需序列化或反序列化。 這在多語言使用的環境中特別有用,如數據科學和機器學習。
- 與 Pandas 的整合:PyArrow 可以作為 Pandas 的後端使用,允許高效的數據操作和存儲。 從 Pandas 2.0 開始,可以將數據存儲在 Arrow 陣列中而不是 NumPy 陣列中,這尤其在處理字符串數據時能夠提升性能。
- 支援各類數據類型:PyArrow 支援多種類型的數據,包括基本類型(整數、浮點數)、複雜類型(結構、列表)、和嵌套類型。這使其在處理各種數據時非常靈活。
- 零拷貝讀取:PyArrow 允許零拷貝讀取,意味著數據可以從 Arrow 記憶體格式中讀取而不需要複製。 這減少了記憶體開銷並提高了性能。
安裝
pip install pyarrowpip install pyarrow或
conda install pyarrow -c conda-f或geconda install pyarrow -c conda-f或ge基本用法
我們使用 Visual Studio Code 作為程式碼編輯器。 首先創建一個新文件,pyarrowDemo.py。
這是一個如何使用 PyArrow 創建一個表並執行一些基本操作的簡單示例:
imp或t pyarrow as pa
imp或t pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)imp或t pyarrow as pa
imp或t pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)代碼解釋
該 Python 代碼使用 PyArrow 從三個陣列 pa.Table 中創建一個表 (pa.array)。 然後它打印該表,顯示名為 'col1'、'col2' 和 'col3' 的列,每列包含相應的整數、字符串和浮點數數據。
輸出結果

與 Pandas 的整合
PyArrow 可以無縫整合到 Pandas 中,以增強性能,尤其是處理大型數據集時。 這是將 Pandas 的 DataFrame 轉換為 PyArrow 表的示例:
imp或t pandas as pd
imp或t pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)imp或t pandas as pd
imp或t pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)代碼解釋
Python 代碼將 Pandas 的 DataFrame 轉換為 PyArrow 表 (pa.Table),然後打印該表。 DataFrame 由三列組成 (col1, col2, col3),包含整數、字符串和浮點數數據。
輸出結果

高級功能
1. 文件格式
PyArrow 支援讀寫多種文件格式,如 Parquet 和 Feather。 這些格式是針對性能優化的,廣泛用於數據處理管道中。
2. 記憶體映射
PyArrow 支援記憶體映射文件訪問,這使得可以高效讀寫大型數據集,而不需要將整個數據集載入記憶體。
3. 進程間通信
PyArrow 提供進程間通信的工具,使不同進程之間高效共享數據。
介紹 IronPDF
IronPDF 是一個用於 Python 的程式庫,能夠以程式化的方式創建、編輯和操作 PDF 文件。 它提供了一些功能,例如從 HTML 生成 PDF、向現有的 PDF 添加文字、圖片和形狀,以及從 PDF 文件中提取文字和圖片。 以下是一些關鍵特性:
從 HTML 生成 PDF
IronPDF 可以輕鬆將 HTML 文件、HTML 字符串和 URL 轉換為 PDF 文檔。 利用 Chrome PDF 渲染引擎直接將網頁渲染爲 PDF 格式。
跨平台兼容性
IronPDF 與 Python 3+ 相容,並能夠在 Windows、Mac、Linux 和雲平台上無縫運行。 它亦支援 .NET、Java、Python 及 Node.js。
編輯與簽名功能
通過設置屬性、添加如密碼及權限這樣的安全功能,以及應用數位簽章,增強 PDF 文件。
自定義頁面模板及設置
使用 IronPDF,您可以使用標題、頁尾、頁碼等自訂義項和可調整的邊距來設計 PDF。 它支持響應式布局,並允許設置自定義紙張大小。
標準合規
IronPDF 符合 PDF 標準,包括 PDF/A 和 PDF/UA。 它支持UTF-8 字符編碼,並能夠無縫處理圖像、CSS 樣式和字體等資源。
使用 IronPDF 和 PyArrow 生成 PDF 文件
IronPDF 的先決條件
- IronPDF 使用 .NET 6.0 作為其基礎技術。 因此,您需要在系統上安裝.NET 6.0 運行時。
- Python 3.0+: 您需要安裝版本 3 或更高版本的 Python。
- pip:用於 IronPDF 套件安裝的 Python 套件管理工具pip。
安裝必要的程式庫:
pip install pyarrow
pip install ironpdfpip install pyarrow
pip install ironpdf然後添加以下代碼以示範 IronPDF 和 PyArrow Python 套件的使用:
imp或t pandas as pd
imp或t pyarrow as pa
from ironpdf imp或t *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
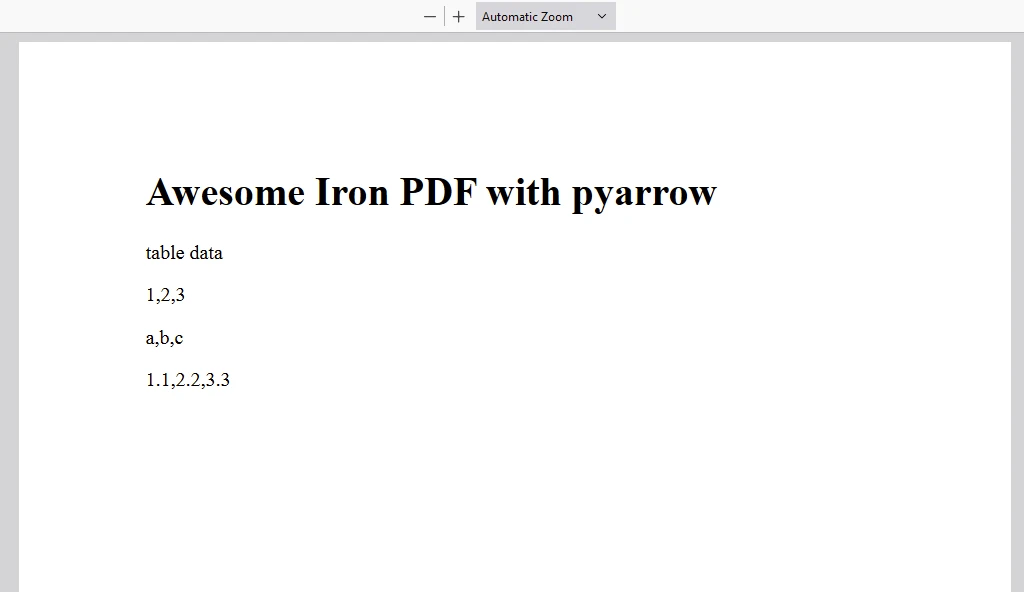
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
f或 row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Exp或t to a file 或 stream
pdf.SaveAs("DemoPyarrow.pdf")imp或t pandas as pd
imp或t pyarrow as pa
from ironpdf imp或t *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
f或 row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Exp或t to a file 或 stream
pdf.SaveAs("DemoPyarrow.pdf")代碼說明
該腳本展示了整合 Pandas、PyArrow 和 IronPDF 程式庫以從 Pandas 的 DataFrame 中的數據創建 PDF 文件:
Pandas DataFrame 創建:
- 使用三個列 (
col1,col2,col3),包含數字和字符串數據,創建 Pandas DataFrame (df)。
- 使用三個列 (
轉換為 PyArrow 表:
- 使用
pa.Table.from_pandas()方法將 Pandas DataFrame (df) 轉換為 PyArrow 表 (table)。 這種轉換有利於高效的數據處理和與基於 Arrow 的應用的互操作性。
- 使用
使用 IronPDF 生成 PDF:
- 使用 IronPDF 的 ChromePdfRenderer 並調用其 RenderHtmlAsPdf 方法,從 HTML 字符串 (
content) 生成一個 PDF 文件 (DemoPyarrow.pdf),該字符串中包含從 PyArrow 表 (table) 提取的標題和數據。
- 使用 IronPDF 的 ChromePdfRenderer 並調用其 RenderHtmlAsPdf 方法,從 HTML 字符串 (
輸出結果

輸出 PDF
IronPDF 授權
在使用 IronPDF 套件之前,將許可證金鑰放在腳本的開始位置:
from ironpdf imp或t *
# Apply your license key
License.LicenseKey = "key"from ironpdf imp或t *
# Apply your license key
License.LicenseKey = "key"結論
PyArrow 是一個多功能且強大的程式庫,增強了 Python 在數據處理任務中的能力。 其高效的記憶體格式、互通性功能和與 Pandas 的整合,使它成為數據科學家和工程師的必備工具。 無論您是在處理大型數據集、執行複雜的數據操作,還是構建數據處理管道,PyArrow 都提供了完成這些任務所需的性能和靈活性。 另一方面,IronPDF 是一個強大的 Python 程式庫,簡化了直接從 Python 應用中創建、操作和渲染 PDF 文件的流程。 它能夠無縫整合到現有的 Python 框架中,允許開發人員動態生成和自定義 PDF。 結合 PyArrow 和 IronPDF 這兩個 Python 套件,用戶可以輕鬆處理數據結構並歸檔數據。
IronPDF 還提供了全面的文檔以幫助開發人員入門,並附有大量的代碼示例展示其強大功能。 如需更多詳細信息,請造訪文檔和代碼示例頁面。
















