
如何在 Python 中從 PDF 中提取圖像
本文章將使用IronPDF for Python透過Python程式碼從PDF文件中提取圖像。
IronPDF for Python
IronPDF for Python是一個尖端且功能強大的程式庫,為Python中的PDF文件處理帶來了新的維度。 作為PDF任務的綜合解決方案,IronPDF使先進的PDF功能能夠無縫整合到應用程式中。
IronPDF提供廣泛的工具和API,可用於從頭開始創建PDF、將HTML轉換為高質量的PDF,以及通過合併、拆分和編輯等動作管理PDF頁面。 這些工具是用戶友好且高效的。 憑藉其用戶友好的介面和豐富的文件,IronPDF為開發者開啟了可能性。
無論是創建專業的報告和發票、自動化工作流程還是管理文件,IronPDF在文件管理和自動化的領域提供了有價值的資產,使其成為任何尋求在Python應用中利用PDF威力的開發者不可或缺的工具。
如何使用IronPDF for Python從PDF提取圖像
- 安裝IronPDF程式庫,以便在Python中從PDF提取圖像。
- 使用
PdfDocument.FromFile方法從本地磁碟載入PDF文件。 - 應用
ExtractAllImages方法從PDF文件中提取圖像。 - 使用迴圈來迭代PDF中找到的所有提取圖像。
- 以所需的圖像格式擴展名保存這些從PDF文件中提取的圖像。
準備工作
在深入了解如何使用Python從PDF中獲取圖像之前,讓我們安裝必要的前置條件:
- Python安裝:確保您的系統上已安裝Python解釋器。 從PDF中獲取圖像的過程將需要Python 3.0或更新版本。 確保您有相容的Python安裝。
IronPDF程式庫:要利用IronPDF的強大功能,您需要使用
pip安裝它,即Python程序包管理器。 只需打開您的命令行界面,並執行以下命令:pip install ironpdfpip install ironpdfSHELL- 集成開發環境 (IDE):雖然不是必需的,但是使用IDE可以大大提升您的開發體驗。 IDE提供如代碼完成、調試以及更流暢的工作流程等功能。 一個高度流行的Python開發IDE是PyCharm。 您可以從JetBrains網站下載並安裝PyCharm。
一旦這些必要條件到位,您可以通過逐步指南探索使用Python和IronPDF提取PDF中圖像的激動人心的世界。
步驟1 創建新的Python專案
以下是在PyCharm中創建新Python專案的步驟。
- 要在PyCharm中啟動新Python專案,請打開PyCharm應用並導航至頂部菜單。
點擊文件,然後從下拉菜單中選擇新專案。
 PyCharm IDE
PyCharm IDE- 點擊新專案後,將出現標題為創建專案的新窗口。
在此窗口中,在頂部的位置欄位中輸入您的專案名稱。選擇環境; 如果您使用虛擬環境,請從提供的選項中選擇它。
 Create a new Python project in PyCharm
Create a new Python project in PyCharm- 一旦選擇環境,單擊創建按鈕來創建您的Python專案。
您的Python專案現在已創建,可以用於各種任務,例如提取圖像。
步驟2 安裝IronPDF
要安裝IronPDF,請打開終端或單獨的命令提示符,然後輸入命令pip install ironpdf,然後按Enter鍵。 終端將顯示以下輸出。
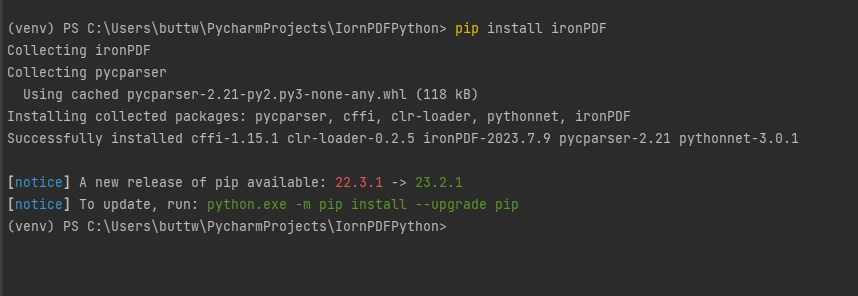 安裝IronPDF套件
安裝IronPDF套件
步驟3 使用IronPDF從PDF文件中提取圖像
IronPDF為開發者提供了工具和API以無縫導航PDF並識別和提取嵌入的圖像。 無論是用於分析或整合,IronPDF利用Python的靈活性簡化提取過程。 這使其成為處理PDF和基於圖像的應用程式的必要工具。只需幾行代碼便能從PDF文件中提取所有圖像,這相當簡單。
請參閱以下代碼,以便使用Python編程語言從PDF提取圖像。
from ironpdf import PdfDocument
# Open PDF file
pdf = PdfDocument.FromFile("FYP Thesis.pdf")
# Get all images found in the PDF Document
all_images = pdf.ExtractAllImages()
# Save each image to the local disk with a dynamic name
for i, image in enumerate(all_images):
image.SaveAs(f"output_image_{i}.png")from ironpdf import PdfDocument
# Open PDF file
pdf = PdfDocument.FromFile("FYP Thesis.pdf")
# Get all images found in the PDF Document
all_images = pdf.ExtractAllImages()
# Save each image to the local disk with a dynamic name
for i, image in enumerate(all_images):
image.SaveAs(f"output_image_{i}.png")此代碼首先匯入IronPDF程式庫,然後使用檔案路徑與PdfDocument.FromFile方法從本地空間載入PDF文件。 它訪問PDF的每一頁以提取圖像位元組作為圖像對象。 這些來自PDF頁面的圖像對象然後使用SaveAs方法保存。 代碼根據圖像索引和所需的圖像文件擴展名(在此範例中為PNG)分配動態圖像名稱。
此方法比使用其他Python程式庫如PyMuPDF和Pillow要簡單,後者需要更多代碼來實現相同的提取和保存圖像文件的任務。
步驟4 保存PDF文件中的圖像
圖像從PDF文件的所有頁面中提取,並以PNG格式保存。 您還可以通過調整文件擴展名以符合所需的圖像文件格式來修改輸出格式。
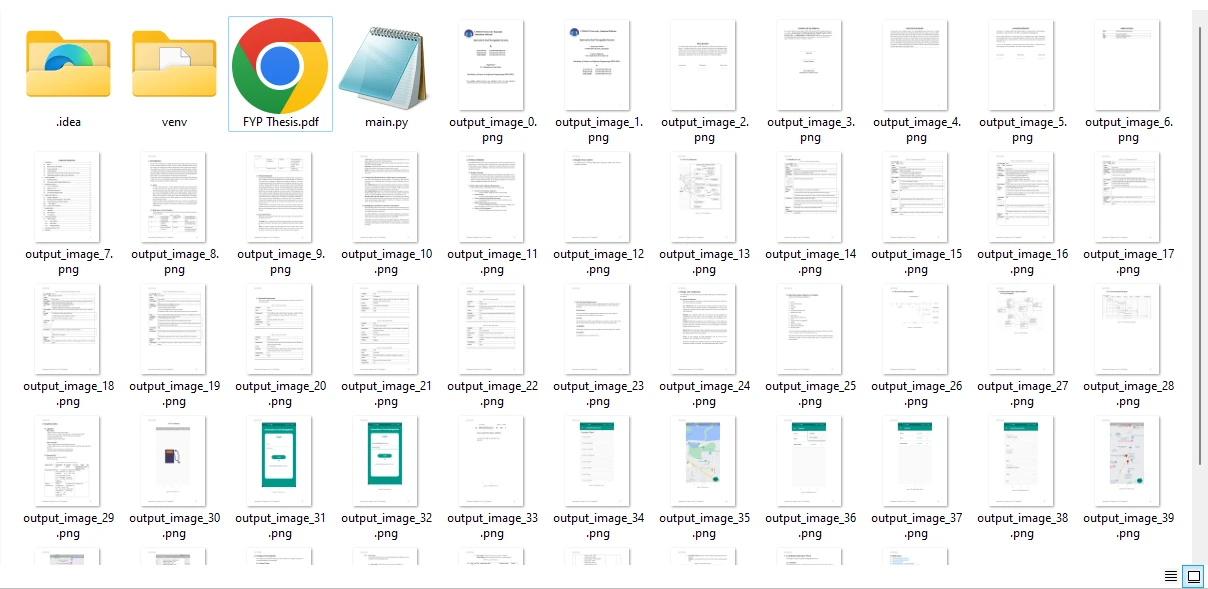從示例PDF文件中提取的圖像
結論
Python與強大的IronPDF相結合,提供了一個多功能且有效的解決方案,用於從PDF文件中獲取圖像的任務。 利用Python的靈活性和IronPDF的功能,開發者可以無縫地導航PDF文件,定位其中的圖像位元組,並以所需的圖像擴展名保存這些圖像。 過程涉及從PDF獲取圖像,並且獲得的圖像列表可以進一步處理和操作以滿足需要。 通過掌握使用Python從PDF中獲取圖像的技術,開發者可以提升工作流程,自動化文件管理,並探索各種基於圖像的應用,使其在數位時代中成為一項有價值的技能。
有關從PDF文件中提取圖像的更多功能,請訪問以下示例。 您可以探索其他操作,如將PDF文件內容轉換為圖像; 完整教程可在此如何Python文章中找到。
常見問題解答
如何使用 Python 從 PDF 中提取圖片?
您可以利用 IronPDF for Python 的 PdfDocument.FromFile 方法加載 PDF 文件,並使用 ExtractAllImages 方法來提取圖片。
使用 Python 保存從 PDF 中提取的圖片的步驟是什麼?
要保存提取的圖片,迭代圖片並使用 SaveAs 方法以指定的文件擴展名(如 PNG)存儲每張圖片。
為什麼選擇 IronPDF 來從 Python 中的 PDF 提取圖片?
與其他庫如 PyMuPDF 和 Pillow 相比,IronPDF 簡化了圖片提取過程,減少了實現類似結果所需的代碼量。
在 Python 中使用 IronPDF 處理 PDF 的要求是什麼?
您需要 Python 3.0 或更新版本,並通過 pip 安裝 IronPDF 庫。使用像 PyCharm 這樣的 IDE 進行開發也是有益的。
如何安裝 IronPDF for Python?
可以使用 pip 包管理器安裝 IronPDF。在命令行界面中運行命令 pip install ironpdf。
IronPDF 可以用於在 Python 中自動化 PDF 文檔管理嗎?
可以,IronPDF 允許自動化文檔管理任務,如提取圖片和轉換 PDF 內容,增強工作流程效率。
IronPDF 支持哪些圖片格式以保存提取的圖片?
提取的圖片可以保存為 PNG 等格式,通過在 SaveAs 方法中指定所需文件擴展名。
IronPDF 適合用於開發基於圖片的應用程序嗎?
IronPDF 很適合用於開發基於圖片的應用程序,因為它在提取和管理 PDF 文檔中的圖片方面提供了強大的功能。
















