
如何在 Python 中解析 PDF 文件
1.0 引言
現代圖書館已經簡化了PDF文件的創建流程。 在為 PDF 專案選擇庫時,請考慮其建置、讀取和轉換功能,以實現最佳整合和效能。 Python 提供了諸如IronPDF之類的工具,可以有效地解析現有的 PDF 檔案。
2.0 IronPDF
Python 是一種程式語言,它使開發人員能夠快速輕鬆地建立圖形使用者介面。 與其他語言相比,它為程式設計師提供了更大的靈活性。 因此,將IronPDF庫與 Python 整合是一個簡單的過程。
為了快速、安全地建立功能齊全的 GUI,開發人員可以利用幾個預裝工具,包括 PyQt、wxWidgets、Kivy 以及許多其他軟體包和函式庫。 值得注意的是, IronPDF並不是一個純粹的 Python PDF 函式庫; 相反,它允許包含來自其他框架(如.NET Core)的各種功能。
IronPDF簡化了 Python Web 設計和開發,這主要歸功於 Django、Flask 和 Pyramid 等 Python Web 開發範式的流行。 包括 Reddit、Mozilla 和 Spotify 在內的知名網站和線上服務都使用了這些框架。 您可以在IronPDF for Python 網站上了解更多關於IronPDF中 Python 的資訊。
2.1 IronPDF的特點
- IronPDF能夠從各種來源產生 PDF 文件,包括 HTML、HTML5、ASPX 和Razor/MVC View。 它提供了從 HTML 頁面和圖像創建 PDF 的功能。
- IronPDF工具包提供了一系列工具,用於執行諸如創建互動式 PDF、填寫和提交互動式表單、拆分和合併PDF 文件、從 PDF 文件中提取文字和圖像、在 PDF 文件中搜尋特定單字、將 PDF 頁面柵格化為圖像、將 PDF 轉換為 HTML 等任務。 IronPDF支援使用者代理、代理、cookie、HTTP 標頭和形狀變量,因此可以驗證 HTML 登入表單。
- 透過使用者名稱和密碼,可以存取IronPDF中的受保護文件。
- IronPDF只需幾行程式碼即可從字串、串流、URL 等各種來源產生 PDF 檔案並進行列印。
3.0 安裝 Python
3.1 環境搭建
請確保您的電腦上已安裝Python。 造訪Python 官方網站,下載並安裝適合您作業系統的最新版 Python。 Python 安裝完成後,設定一個虛擬環境來隔離專案的依賴項。 使用"venv"模組建立和管理虛擬環境,為您的轉換專案提供一個乾淨、獨立的工作空間。
3.2 PyCharm中的新項目
我們將使用 PyCharm(一款用於編寫 Python 程式碼的 IDE)進行本次示範。
啟動 PyCharm IDE 後,點選"新建專案"。
 PyCharm 歡迎介面
PyCharm 歡迎介面
選擇"新建項目"後,將彈出一個新窗口,讓您指定項目的位置及其環境。 這個新視窗可以在下面的截圖中看到。
 PyCharm中的新專案介面
PyCharm中的新專案介面
設定專案位置和環境路徑後,按一下"建立"按鈕開始新專案。 這將打開一個新窗口,可以在其中開發程式。 本教學推薦使用 Python 3.9 版本。
 在 PyCharm 中開啟的主文件
在 PyCharm 中開啟的主文件
3.3 IronPDF庫要求
IronPDF是一個 Python 函式庫,主要依賴.NET 6.0。因此,要使用 Python 版IronPDF ,您的電腦必須安裝.NET 6.0 執行環境。 Linux 和 Mac 使用者在使用此 Python 模組之前可能需要安裝.NET 。 您可以從.NET網站取得所需的執行環境。
3.4 IronPDF庫設置
要建立、編輯和開啟副檔名為".pdf"的文件,需要安裝"IronPDF"軟體包。 若要在 PyCharm 中安裝該軟體包,請開啟終端機視窗並輸入以下命令:
pip install ironpdfpip install ironpdf下面的截圖顯示了"IronPDF"軟體包的設定。
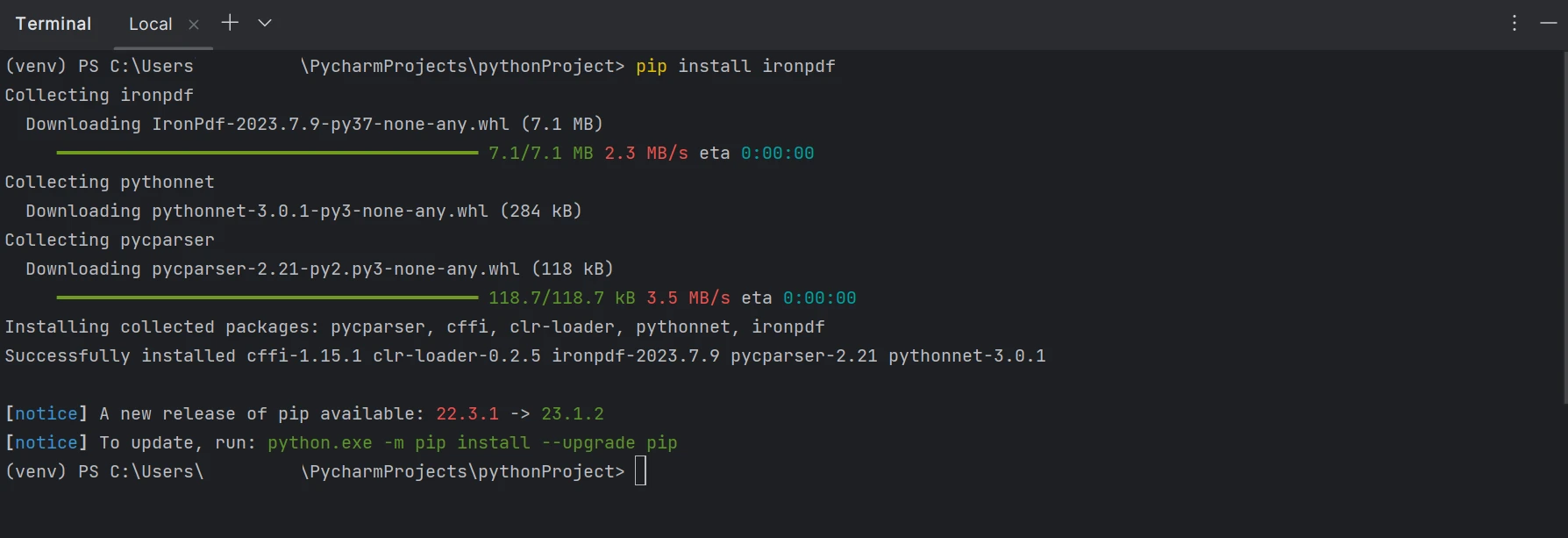 終端機顯示使用 pip 安裝IronPDF的過程。
終端機顯示使用 pip 安裝IronPDF的過程。
4.0 使用IronPDF解析 PDF
借助IronPDF庫,可以從 PDF 文件中提取文字。 IronPDF提供了多種文字擷取技術。 第一種方法是將頁面上的所有內容檢索為一個字串。 第二種方法是從第一頁開始,一頁一頁地閱讀內容。 以下程式碼片段示範了使用IronPDF檢查目前 PDF 檔案的模式。
從PDF文件中提取資料有兩種方法:
- 從 PDF 中按頁提取。
- 將整個 PDF 提取為文字。
下面這個PDF文件將用於本文。 它有兩頁。
 PDF 文件,每頁頂部都有頁碼
PDF 文件,每頁頂部都有頁碼
4.0.1 按頁擷取文本
下面提供的範例程式碼示範如何使用頁碼從 PDF 檔案中檢索資料。
from ironpdf import PdfDocument
# Open a PDF file and create a PDF document object
pdfDocument = PdfDocument.FromFile("F:\\PDF\\1.pdf")
# Extract text from the first page (index 0)
AllText = pdfDocument.ExtractTextFromPage(0)
# Print the extracted text from the first page
print(AllText)from ironpdf import PdfDocument
# Open a PDF file and create a PDF document object
pdfDocument = PdfDocument.FromFile("F:\\PDF\\1.pdf")
# Extract text from the first page (index 0)
AllText = pdfDocument.ExtractTextFromPage(0)
# Print the extracted text from the first page
print(AllText)此程式碼片段示範如何使用 FromFile 函數讀取 PDF 檔案並建立 PDF 文件物件。 此物件允許存取 PDF 中的文字和圖像。 若要從特定頁面提取文本,可以使用 ExtractTextFromPage 方法,並將頁碼作為參數提供。 此方法將傳回一個字串,其中包含指定頁面上的所有單字。 輸出結果將顯示如下。
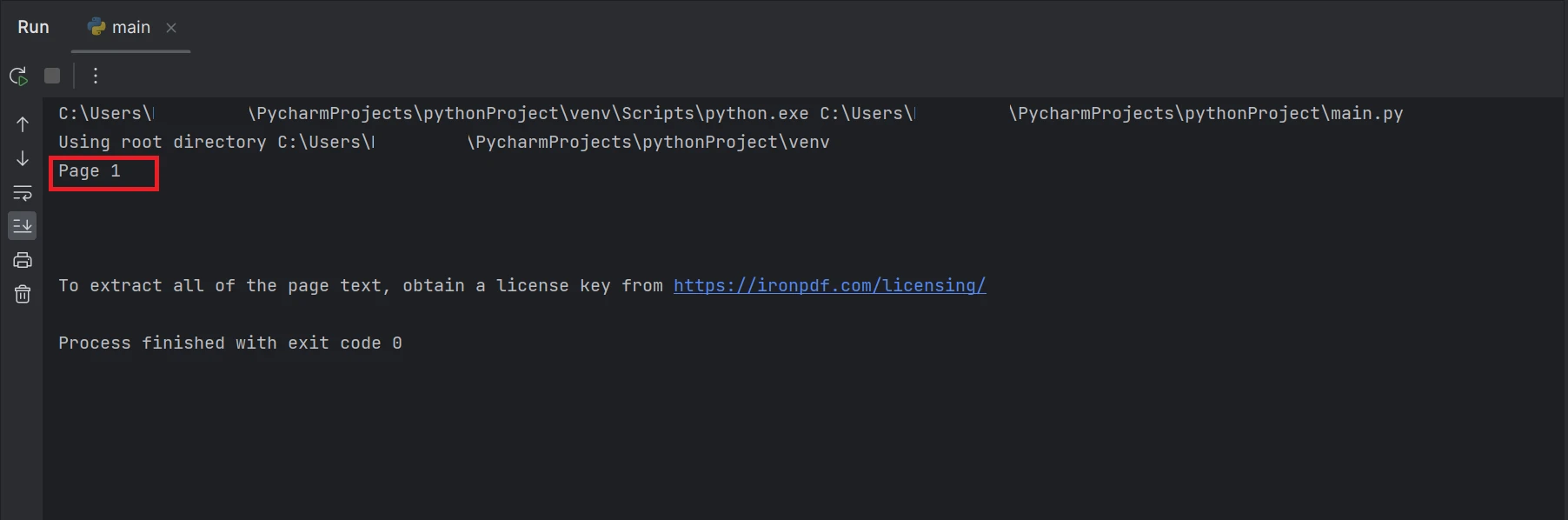 終端機螢幕截圖,顯示文字輸出"第 1 頁"
終端機螢幕截圖,顯示文字輸出"第 1 頁"
結果中反白的矩形框是從 PDF 文件第 1 頁(索引為 0)提取的資料文字。
4.0.2 從所有頁面提取
下面的程式碼範例展示了快速簡單地將所有 PDF 內容作為字串取得的第一種方法。
from ironpdf import PdfDocument
# Create a PDF file object from the file path
pdf = PdfDocument.FromFile('F:\\PDF\\1.pdf')
# Extract all text from the entire PDF
all_text = pdf.ExtractAllText()
# Print the extracted text from the entire PDF
print(all_text)from ironpdf import PdfDocument
# Create a PDF file object from the file path
pdf = PdfDocument.FromFile('F:\\PDF\\1.pdf')
# Extract all text from the entire PDF
all_text = pdf.ExtractAllText()
# Print the extracted text from the entire PDF
print(all_text)上面顯示的範例程式碼解釋瞭如何從現有文件路徑讀取 PDF 並使用 FromFile 函數將其轉換為 PDF 文件物件。 將會提取 PDF 的純文本,並使用該物件的 ExtractAllText 函數將其轉換為字串,然後將提取的文本列印到終端上。 結果將如下所示。
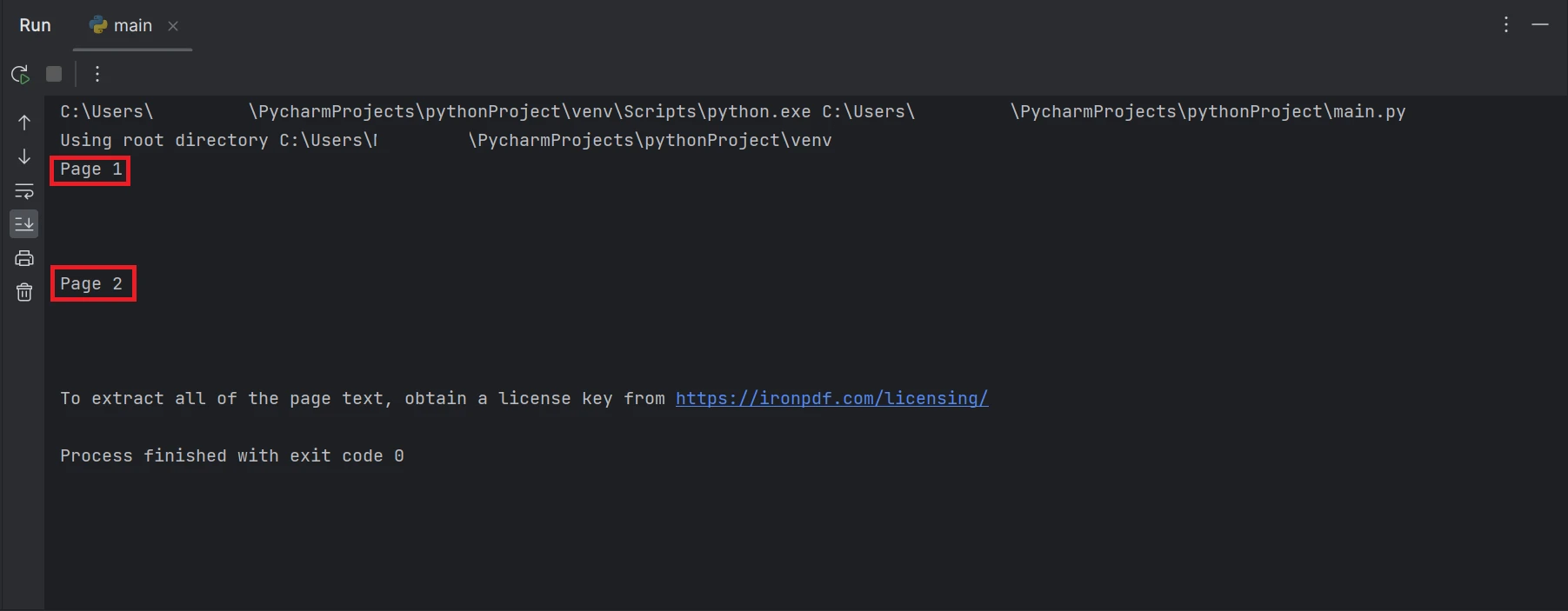 終端機螢幕截圖,顯示文字輸出"第 1 頁"和"第 2 頁"。
終端機螢幕截圖,顯示文字輸出"第 1 頁"和"第 2 頁"。
結果中高亮顯示的矩形框包含了從 PDF 檔案所有頁面中提取的資料文字。
使用IronPDF,我們可以使用 C# 建立 PDF 檔案。 要了解更多關於IronPDF 的信息,請訪問IronPDF網站。
5.0 結論
為了最大限度地降低風險並確保資料安全, IronPDF庫提供了強大的安全措施。 它與所有常用瀏覽器相容,不局限於任何單一瀏覽器。 IronPDF讓程式設計師只需幾行程式碼即可輕鬆建立和讀取 PDF 檔案。 為了滿足開發人員的各種需求, IronPDF庫提供了多種許可選項,包括免費的開發人員許可證和其他可供購買的開發許可證。
$799 Lite 套餐包含永久許可證、30 天退款保證、一年軟體支援和升級選項。 除首次購買外,沒有其他額外費用。 生產環境、測試環境和開發環境都會用到這些許可證。 IronPDF也提供免費許可證,但有一些時間和分發限制。 在免費試用期內,使用者可以在無浮水印的情況下實際體驗產品。 有關 IronPDF 試用版的費用和許可詳情,請造訪IronPDF許可頁面。
常見問題解答
如何使用 Python 解析 PDF 文件?
您可以使用 IronPDF 在 Python 中解析 PDF 文件。該庫允許您創建 PDF 文件對象並使用 ExtractTextFromPage 等方法從特定頁面提取文本,或使用 ExtractAllText 從整個文件中提取文本。
在 Python 環境中運行 IronPDF 的先決條件是什麼?
要在 Python 環境中運行 IronPDF,您需要在系統上安裝 .NET 6.0 運行時,因為 IronPDF 依賴 .NET 進行操作。
IronPDF 可以與流行的 Python 網路框架一起使用嗎?
可以,IronPDF 與流行的 Python 網路框架如 Django、Flask 和 Pyramid 無縫集成,使其成為網路開發專案的多功能工具。
How do you install IronPDF in a Python virtual environment?
要在 Python 虛擬環境中安裝 IronPDF,首先確保已安裝 Python 並建立虛擬環境。在 IDE 的終端中使用命令 pip install ironpdf 來安裝此包。
IronPDF 為 Python 開發者提供了一些主要功能是什麼?
IronPDF 提供了從 HTML、圖像、字符串和流生成 PDF、創建互動式 PDF、填寫表單、拆分和合併 PDF,以及提取文本和圖像等功能。
IronPDF是否與不同的操作系統兼容?
Yes, IronPDF is compatible with different operating systems. However, Linux and Mac users need to ensure that .NET is installed on their systems to use the Python module.
IronPDF 的許可選擇有哪些?
IronPDF 提供多種授權選項,包括具有限制的免費開發者授權以及具有永久授權和 30 天退款保證的付費 Lite 套餐。這些選擇提供了靈活性,能根據開發需要而選用。
如何在 PyCharm 中設置新的 IronPDF 項目?
要在 PyCharm 中設置新的 IronPDF 專案,打開 IDE,點擊 'New Project',並配置專案的位置和環境。使用 PyCharm 中的終端使用 pip install ironpdf 安裝 IronPDF。
IronPDF 如何確保 PDF 文檔的安全性?
IronPDF 採用了強大的安全措施以確保 PDF 文件的安全性和完整性,使其成為需要 PDF 處理的應用程式的可靠選擇。
IronPDF 可以提取 PDF 中的圖像嗎?
可以,IronPDF 可以用於通過訪問文件對象並使用適當的方法檢索圖像數據。
















