
如何在 Python 中拆分 PDF 文件
在數位文件管理領域,有效率地操作和組織 PDF 文件的能力對於許多開發人員和專業人士來說是一項至關重要的技能。 Python 是一種功能強大且用途廣泛的程式語言,它提供了各種各樣的程式庫和工具來完成這項任務。 其中一項任務是分割大型 PDF 文件,這對於提取特定頁面、建立較小的文件或自動化文件工作流程等任務至關重要。
在本文中,我們將探索一個 Python 庫,該庫使我們能夠輕鬆地分割 PDF 文件,為任何希望在 PDF 處理工作中利用 Python 的潛力的人提供全面的指南。 無論您是經驗豐富的開發人員還是 Python 新手,本文都將為您提供有效且有效率地分割 PDF 文件所需的知識和工具。 本文將使用的 Python 函式庫和範例是IronPDF for Python 。 它是操作 PDF 文件最簡單且功能強大的軟體之一。
如何在 Python 中分割 PDF 文件
- 安裝用於分割 PDF 檔案的 Python 函式庫。
- 使用RenderHtmlAsPdf方法產生 PDF 檔案。
- 使用 Python 中的Split方法分割產生的 PDF 檔案。
- 使用SaveAs方法儲存新產生的 PDF 文件。
- 使用拆分方法拆分現有 PDF 檔案。
1. IronPDF for Python
IronPDF是一個尖端的函式庫,它將 PDF 產生和操作的強大功能引入 Python 程式設計領域。 在當今的數位時代,創建和使用 PDF 文件是無數應用程式和工作流程中不可或缺的一部分,從生成報告到管理發票和交付內容,無所不包。 IronPDF彌合了 Python 和 PDF 之間的差距,為開發人員提供了一個功能豐富且用途廣泛的解決方案,可以無縫地以程式設計方式建立、編輯和操作 PDF 檔案。
在本文中,我們將深入探討IronPDF的功能,探索它如何簡化 Python 中與 PDF 相關的任務,並為開發人員提供所需的工具,以便在他們的應用程式中充分利用 PDF 文件的潛力。 無論您是建立 Web 應用程式、產生報告或自動化文件工作流程, IronPDF for Python 都是一個強大的助手,可以簡化您的開發流程、節省時間並增強專案的功能。
2. 建立一個新的 Python 項目
在PyCharm中建立一個新的 Python 專案是一個簡單的流程,可以讓你有效地組織 Python 腳本並管理依賴項。 以下是如何在 PyCharm 中建立新 Python 專案的逐步指南:
1.開啟 PyCharm:如果 PyCharm 尚未打開,請啟動它。 你應該會看到 PyCharm 的歡迎介面。 2.建立新項目:點擊頂部選單中的"檔案",然後選擇"新建項目..."。 您也可以使用鍵盤快速鍵"Ctrl + Shift + N"(Windows/Linux)或"Cmd + Shift + N"(macOS)開啟"新專案"對話方塊。
3. 安裝適用於 Python 的IronPDF
IronPDF for Python 的先決條件
IronPDF for Python依賴.NET 6.0 框架作為其底層技術。 因此,要使用IronPDF for Python,必須在您的電腦上安裝.NET 6.0 SDK。
安裝
使用系統終端機或 PyCharm 的內建命令列終端機可以輕鬆安裝IronPDF 。 只需執行以下命令, IronPDF將在幾秒鐘內安裝完成。
pip install ironpdf
下面截圖顯示了 ironpdf 軟體包的安裝過程。
4. 使用IronPDF for Python 分割 PDF 文件
在本文中,我們將深入探討使用IronPDF for Python 分割 PDF 的世界,探索其特性和功能,並示範它如何簡化提取和管理 PDF 內容這一通常很複雜的任務,同時增強您使用 Python 進行的文檔處理工作。
下面的程式碼片段將向您展示如何僅用幾行程式碼輕鬆分割 PDF 檔案。
from ironpdf import ChromePdfRenderer
# Define HTML content with page breaks
html = """<p> Hello Iron </p>
<p> This is the 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is the 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is the 3rd Page</p>"""
# Render the HTML into a PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# Copy and save the first page
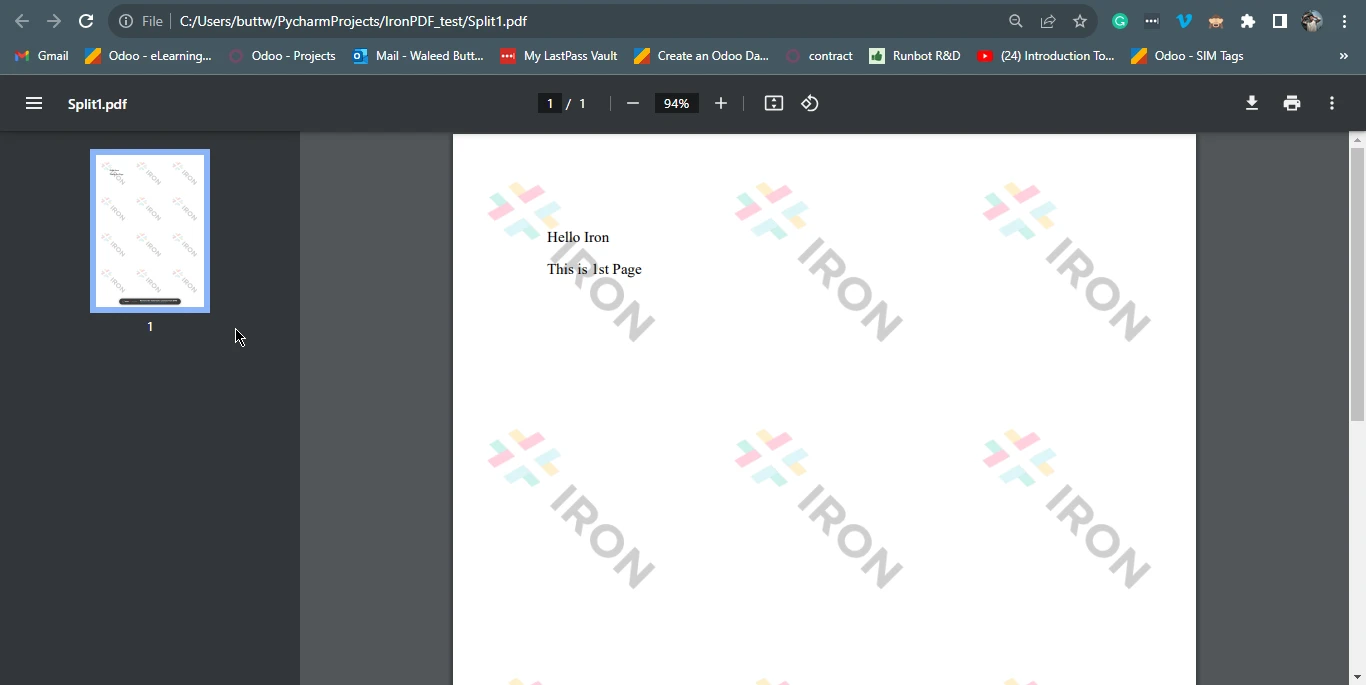
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# Copy and save the second and third pages as a single document
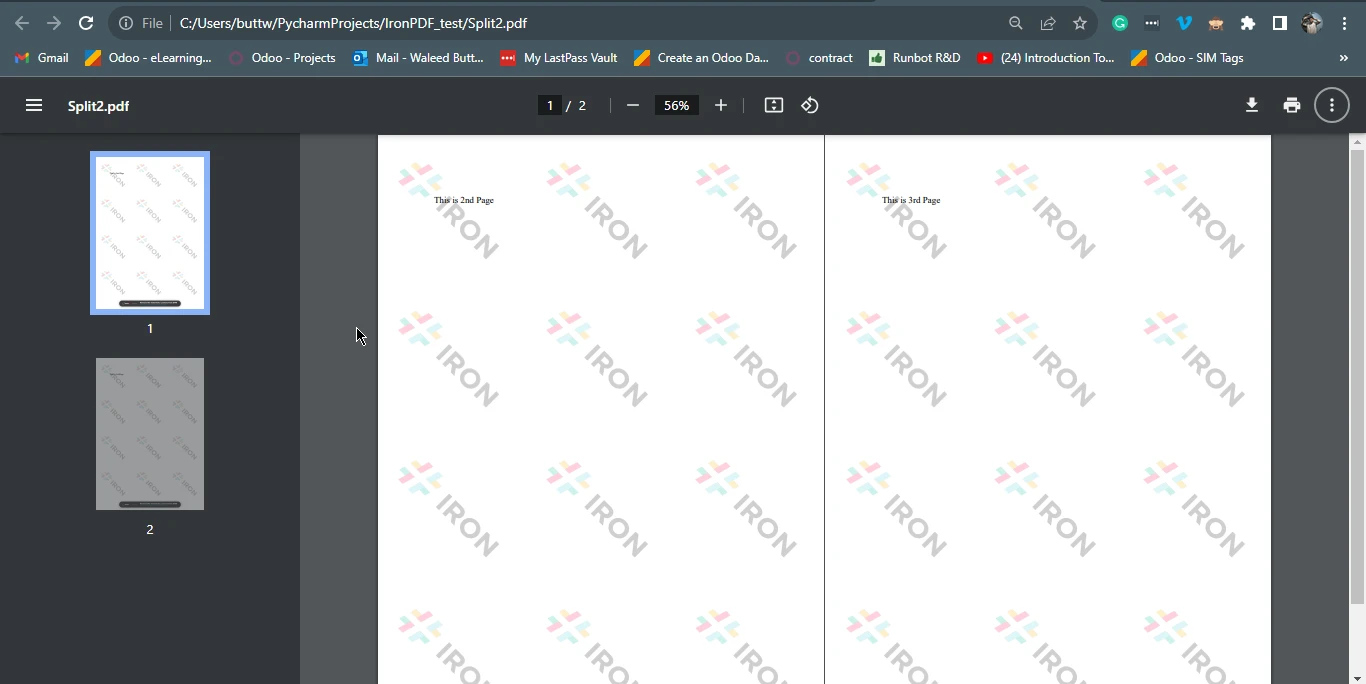
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")from ironpdf import ChromePdfRenderer
# Define HTML content with page breaks
html = """<p> Hello Iron </p>
<p> This is the 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is the 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is the 3rd Page</p>"""
# Render the HTML into a PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# Copy and save the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# Copy and save the second and third pages as a single document
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")這段 Python 腳本利用IronPDF將 HTML 文件拆分成多個 PDF 檔案。 它首先定義一個包含多個段落的 HTML 內容字串,分頁符號由 <div style='page-break-after: always;'></div> 元素指示。 接下來,它利用 IronPDF 的 ChromePdfRenderer 將 HTML 渲染為新的 PDF 檔案。
然後,它根據原始文件的頁碼索引(從 0 開始)將第一頁複製到名為"Split1.pdf"的單獨文件中,使用函數 pdf.CopyPage(0)。 最後,它根據頁數使用函數 pdf.CopyPages(1, 2) 建立另一個包含第二頁和第三頁 PDF 的 PDF,並將其儲存為名為"Split2.pdf"的新檔案。 這段程式碼展示了IronPDF如何輕鬆地將 PDF 內容提取並拆分成多個 PDF 文件,使其成為 Python 應用程式中處理 PDF 文件的寶貴工具。
4.1 輸出 PDF 文件
您也可以將現有的 PDF 檔案拆分成多個頁面,並以新的 PDF 文件格式儲存。 若要將現有 PDF 文件分割為多個 PDF 文件,請依照下列程式碼範例操作:
from ironpdf import PdfDocument
# Open the existing PDF document
pdf = PdfDocument("document.pdf")
# Copy and save the first page as a separate file
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# Copy additional pages and save them as a separate document
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")from ironpdf import PdfDocument
# Open the existing PDF document
pdf = PdfDocument("document.pdf")
# Copy and save the first page as a separate file
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# Copy additional pages and save them as a separate document
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")上面的程式碼使用 PdfDocument 方法,透過提供原始檔案名稱開啟現有的 PDF 文件,並將其拆分為兩個單獨的 PDF 文件。
5. 結論
本文展示了 Python 的多功能性和強大的IronPDF庫,為希望高效分割和操作 PDF 文件的新手和經驗豐富的開發人員提供了全面的指南。 IronPDF彌合了 Python 和 PDF 之間的差距,為各種應用程式和工作流程提供功能豐富的解決方案,從生成報告到自動化文件處理。
這篇文章不僅指導讀者如何設定 Python 專案和安裝IronPDF ,還提供了清晰的程式碼範例,用於分割 PDF 文件,無論是從 HTML 內容還是現有文件。 透過利用 IronPDF 的功能,開發人員可以增強文件處理任務,簡化工作流程,並充分發揮 Python 應用程式中處理 PDF 文件和文件的潛力,使其成為文件管理和操作的寶貴工具。
有關使用IronPDF庫將 HTML 轉換為 PDF 的更多信息,請訪問以下教程頁面。 這裡提供了分割 PDF 檔案的程式碼範例。
IronPDF for Python提供免費試用許可證,供商業用途測試其全部功能。 之後,它還需要獲得商業用途的許可。 如需了解更多信息,您可以訪問 IronPDF 的許可頁面。
常見問題解答
我如何使用 Python 拆分 PDF 文件?
你可以在 Python 中使用 IronPDF 通過採用 CopyPage 和 CopyPages 等方法來拆分 PDF 文件,這些方法允許你從 PDF 中提取特定頁面並將其作為單獨的文檔保存。
安裝 IronPDF for Python 需要哪些步驟?
要安裝 IronPDF for Python,請使用命令 pip install ironpdf。確保您的計算機上已安裝 .NET 6.0 SDK,因為它是使用 IronPDF 的先決條件。
IronPDF 可以在 Python 中將 HTML 轉換為 PDF 嗎?
是的,IronPDF 可以使用 RenderHtmlAsPdf 方法在 Python 中將 HTML 轉換為 PDF,這可以無縫地將 HTML 網頁內容轉換為 PDF 格式。
拆分 PDF 文件有什麼好處?
拆分 PDF 文件有助於提取特定頁面,創建更小、更易於管理的文檔,並自動化文檔工作流。這一功能對於高效的數字文檔管理至關重要。
如何使用 IronPDF 自動化文檔工作流?
IronPDF 通過提供程式化拆分、合併和操作 PDF 文檔的工具來支持文檔工作流的自動化,從而簡化流程並提高效率。
Python 中的 IronPDF 有試用版嗎?
是的,IronPDF 提供了一個商業用途的免費試用許可證,使您可以在承諾購買商業許可證之前測試其功能。
如何在 PyCharm 中創建一個新的 Python 項目來操作 PDF?
To create a new Python project in PyCharm, navigate to 'File' > 'New Project', set the desired project location and interpreter, then click 'Create'. This setup allows you to start integrating libraries like IronPDF.
為什麼 PDF 操作對開發者很重要?
PDF 操作對開發者至關重要,因為它使他們能夠高效地組織、提取和管理 PDF 文件,支持各種文檔工作流和應用程序中的數字文檔管理。
















