
iText7在C#中读取PDF的替代方案(VS IronPDF)
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
IronPDF 与 iTextSharp / iText7 的对比
全面的 .NET PDF 库比较——逐项功能对比,并提供基于事实的上下文分析
| 特征 | iTextSharp / iText7 | IronPDF ✦ |
|---|---|---|
| PDF Creation & Conversion | ||
| HTML/CSS 转 PDF |
$ Paid Add-on
通过
pdfHTML将 HTML 转换为 PDF(单独的软件包;AGPL/商业模式)。 |
✓ Yes
基于 Chromium 内核的引擎,内置像素级精准的 CSS3、Flexbox 和 Grid 渲染。
|
| JavaScript 执行 |
? Unknown
pdfHTML 描述了 HTML/CSS→PDF 的转换,但文档中没有说明是否支持 JS 执行。
|
✓ Yes
在渲染过程中完全执行 JS——动态图表、SPA 和交互式内容。
|
| 程序化生成 |
✓ Yes
定位为面向 .NET 的可编程 PDF SDK——创建、编辑和增强。
|
✓ Yes
可从 HTML 模板、字符串、ASPX 视图或图像生成内容。Chromium 负责布局。
|
| URL 转 PDF |
$ Paid Add-on
可以通过 pdfHTML 插件的 URL 获取功能实现,但这不是核心功能。
|
✓ Yes
RenderUrlAsPdf() 捕获任何实时 URL 并进行完整的 CSS/JS 渲染。 |
| DOCX 转换为 PDF |
✕ No
不支持原生 Word 转换——iText 是一个 PDF 原生 SDK。
|
✓ Yes
DocxToPdfRenderer 转换 Word 文档,保留其结构和格式。 |
| Reading & Extraction | ||
| 文本提取 |
✓ Yes
PdfTextExtractor.GetTextFromPage() 采用多种提取策略。 |
✓ Yes
提取文本时能够感知布局。可与 IronOCR 结合使用,识别扫描文档。
|
| 将页面渲染为图像 |
? Unknown
OCR 工作流程中提到了渲染,但在引用的 iText 文档中没有发现主要来源的"PDF→图像渲染器"模块。
|
✓ Built-in
原生栅格化为PNG、JPEG、BMP格式,DPI可配置。
|
| 内置OCR |
$ Paid Add-on
提供 pdfOCR 插件;安装说明中提到了平台特定的/原生依赖项(例如,Linux/macOS 运行时要求)。
|
✓ Via IronOCR
与 IronOCR 原生集成,可对扫描的 PDF 文件进行 127 种以上语言的 OCR 识别。
|
| Editing & Manipulation | ||
| Merging & Splitting |
✓ Yes
PdfMerger .NET API 中的类;官方示例讨论了通过 PdfMerger 进行合并。
|
✓ Yes
通过直观的 API,实现一行式合并、拆分、追加、前置和页面重新排序。
|
| Headers, Footers & Page Numbers |
✓ Yes
PDF协会的列表证实了向现有PDF添加"页码"和类似功能的能力。
|
✓ Yes
基于 HTML 的页眉/页脚,带有自动页码、日期和自定义内容。
|
| 水印 |
✓ Yes
PDF协会的列表明确包括"在现有PDF文档上添加水印"。
|
✓ Yes
ApplyWatermark() 支持 HTML/CSS——完全控制透明度、旋转角度和位置。 |
| Stamp Text & Images |
✓ Yes
通过 iText 的 canvas 和 layout API 实现程序化内容投放。
|
✓ Yes
TextStamper 以及带有 Google Fonts、定位和页面级控制的ImageStamper 。 |
| 编辑内容 |
✓ Yes
iText 通过清理模块提供编辑注释支持。
|
✓ Yes
RedactTextOnAllPages() 永久删除一行中的敏感文本。
|
| Security & Compliance | ||
| Encryption & Passwords |
✓ Yes
通过 iText 的安全 API 实现完全加密和权限控制。
|
✓ Yes
AES 加密、所有者/用户密码、细粒度权限(打印、复制、注释)。
|
| 数字签名 |
✓ Yes
专用数字签名文档和签名 API (
PdfSigner )。 |
✓ Yes
PdfSignature 支持 X509/PFX 证书。 |
| PDF/A & PDF/UA Compliance |
✓ Yes
文档涵盖了创建 PDF/A 的内容,并解释了其限制(从现有文件转换不是自动的)。
|
✓ Yes
适用于企业环境的原生 PDF/A 归档和 PDF/UA 无障碍访问合规性。
|
| Platform & Deployment | ||
| 跨平台支持 |
✓ Yes
.NET Standard 2.0 / .NET Framework 4.6.1 — 可在 .NET 6+ 及更高版本的操作系统上运行。
|
✓ Yes
Windows、Linux、macOS、x64、x86、ARM。.NET 6–10、Core、Standard 2.0+、Framework 4.6.2+。
|
| 服务器/Docker/云 |
~ Complex
核心安装需要多个软件包(iText + Bouncy Castle 适配器);附加组件(pdfHTML/pdfOCR)会增加进一步的依赖/合规步骤。
|
✓ Yes
Docker、Azure、AWS、IIS。官方 Docker 镜像和部署指南。
|
| 安装简便 |
~ Complex
核心安装需要多个软件包(Bouncy Castle 适配器);HTML/OCR 需要额外的插件,有时还需要原生依赖项。
|
✓ Simple
只需一条 NuGet
Install-Package IronPdf安装。 |
| Licensing & Support | ||
| 许可模式 |
~ Complex
双重许可:AGPLv3(网络使用需披露源代码)或商业许可。AGPL 对专有应用程序的限制可能较大。
|
✓ Commercial
永久授权。30天全功能免费试用,无水印。
|
| Commercial Support & SLA |
✓ Yes
iText 网站的许可模式包括商业许可和支持协议。
|
✓ 24/5 Support
提供专属工程支持,并保证服务水平协议 (SLA)——电子邮件、在线聊天、电话。
|
| 文档 |
✓ Yes
提供安装指南、知识库文章和 API 参考(核心 + 附加组件)。
|
✓ Extensive
完整的 API 参考、100 多个操作指南、教程、代码示例、故障排除、视频。
|
数据来源于 iText 官方文档、PDF 协会列表和 NuGet 包参考资料。
iText7 功能强大,但 AGPL 许可较为复杂,且需要安装多个软件包,因此设置起来比较麻烦。
IronPDF 提供全面覆盖,设置更简单——免费试用 30 天。
PDF 是由 Adobe Acrobat Reader 创建的一种便携文档格式,被广泛用于在互联网上数字信息共享。 它保留数据格式,并提供设置安全权限和密码保护等功能。 作为 C# 开发人员,您可能遇到过需要将 PDF 功能集成到您的软件应用程序中的情况。 从头构建它可能是一项耗时且繁琐的任务。 因此,考虑到应用程序的性能、效果和效率,从头创建一个新服务或使用预构建库之间的权衡是显著的。
有几个适用于 C# 的 PDF 库可用。 在本文中,我们将探索两个最流行的用于在 C# 中读取 PDF 文档的 PDF 库。
iText 软件
iText 7,前称 iText 7 Core,是一个用于在 .NET C# 和 Java 编写 PDF 文档的 PDF 库。 它可作为开源许可证 (AGPL) 使用,并可用于商业应用。
iText Core 是一个高级 API,提供便捷的方法来生成和编辑 PDF。 使用 iText 7 Core,您可以拆分、合并、注释、填写表单、数字签名,以及对 PDF 文件进行更多操作。 iText 7 提供一个HTML 到 PDF 转换器。
IronPDF。
了解更多关于 IronPDF 是一个 .NET 和 .NET Framework C# 和 Java API,用于从 HTML、CSS 和 JavaScript 生成 PDF 文档,无论是从 URL、HTML 文件还是 HTML 字符串。 IronPDF 允许您操作现有的 PDF 文件,如拆分、合并、注释、数字签名等等。
IronPDF 具有 50 多个功能以创建、读取和编辑 PDF 文件。 当您需要使用 Adobe Acrobat Reader 提供高质量、像素完美的专业 PDF 文件时,它优先考虑速度、易用性和准确性。 API 文档详细,而且可以在其代码示例页面找到大量样本源代码。
创建控制台应用程序
我们将使用 Visual Studio 2022 IDE 来创建一个应用程序作为开始。 Visual Studio 是 C# 开发的官方 IDE,您必须安装它。 如果尚未安装,可以从微软 Visual Studio 网站下载。
以下步骤将创建一个名为"DemoApp"的新项目。
- 打开 Visual Studio 并点击"创建新项目"。
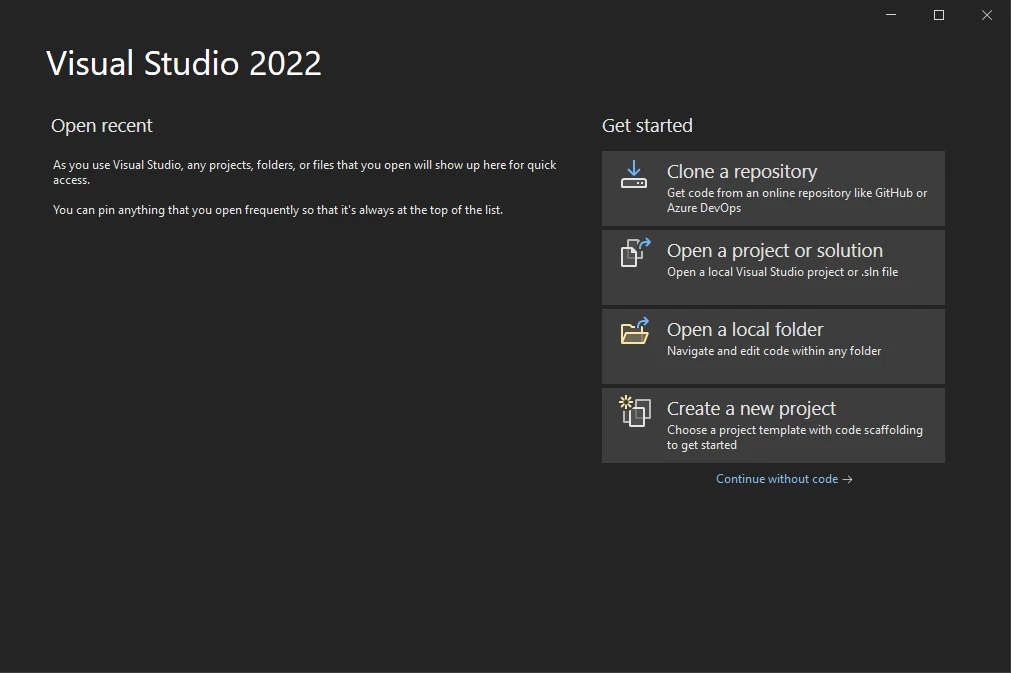
- 选择"控制台应用程序"并点击"下一步"。
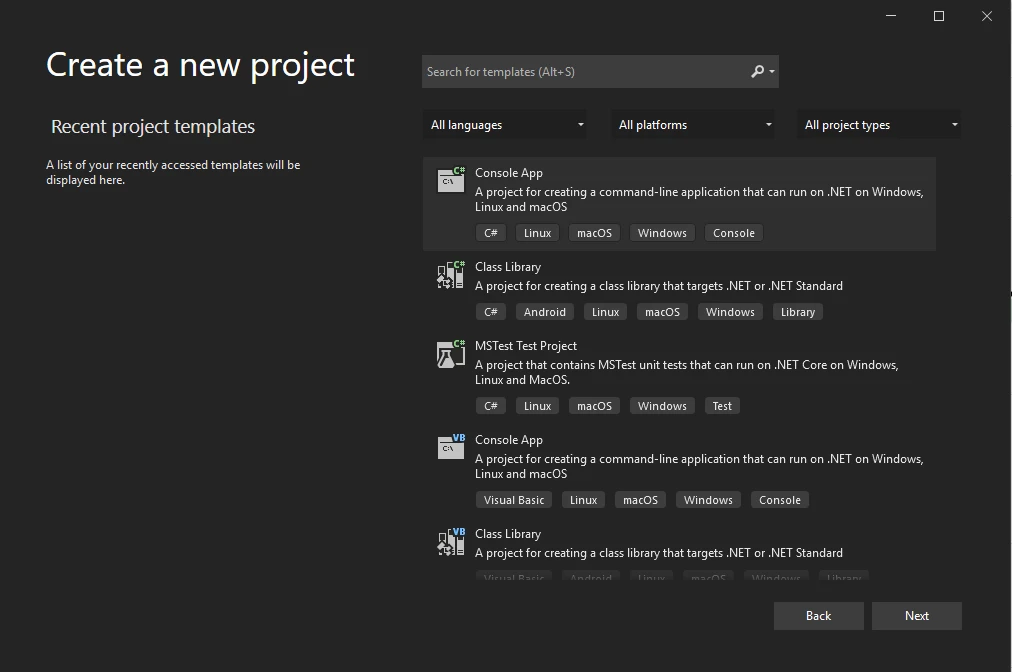
- 设置项目名称。
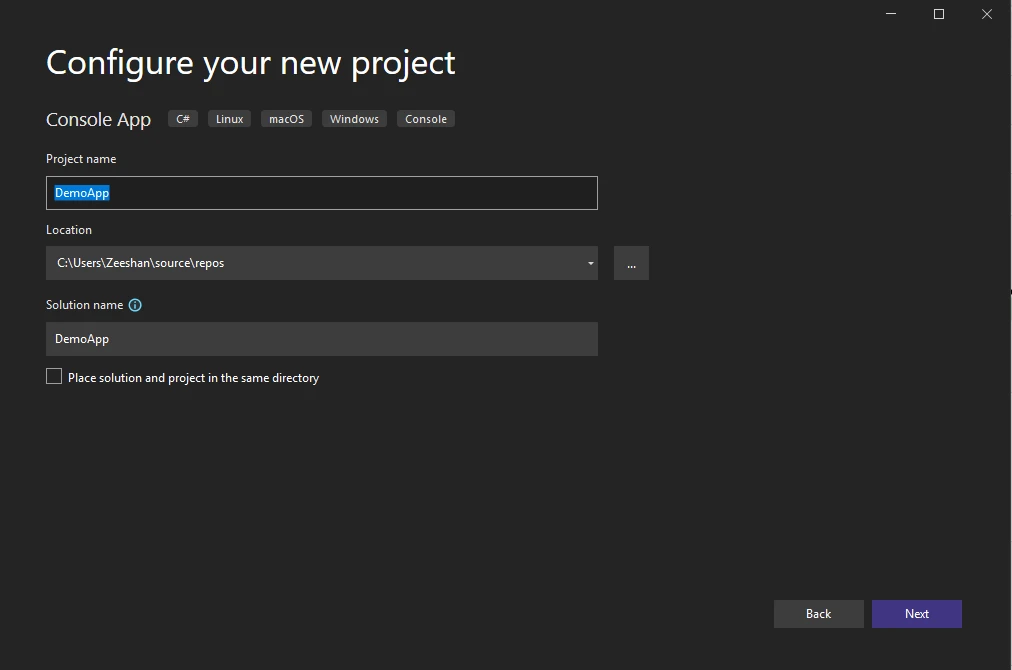
- 选择 .NET 版本。 选择稳定版本 .NET 6.0。
安装 IronPDF 库
一旦项目创建完成,就需要在项目中安装 IronPDF 库以便使用。 按照以下步骤安装。
- 打开 NuGet 包管理器,可以从解决方案资源管理器或工具中找到。
- 浏览 IronPDF 库并为当前项目选择。 点击安装。
在 Program.cs 文件顶部添加以下命名空间:
using IronPdf;using IronPdf;Imports IronPdf安装 iText 7 库
一旦项目创建完成,就需要在项目中安装 iText 7 库以便使用。 按照以下步骤安装。
- 打开 NuGet 包管理器,可以从解决方案资源管理器或工具中找到。
- 浏览 iText 7 库并为当前项目选择。 点击安装。
在 Program.cs 文件顶部添加以下命名空间:
using iText.Kernel.Pdf.Canvas.Parser.Listener;
using iText.Kernel.Pdf.Canvas.Parser;
using iText.Kernel.Pdf;using iText.Kernel.Pdf.Canvas.Parser.Listener;
using iText.Kernel.Pdf.Canvas.Parser;
using iText.Kernel.Pdf;Imports iText.Kernel.Pdf.Canvas.Parser.Listener
Imports iText.Kernel.Pdf.Canvas.Parser
Imports iText.Kernel.Pdf打开 PDF 文件
我们将使用以下 PDF 文件从中提取文本。 这是一个两页的 PDF 文档。
使用 iText 库
使用 iText 库打开 PDF 文件是一个两步过程。 首先,我们创建一个 PdfReader 对象,并将文件位置作为参数传递。 然后我们使用 PdfDocument 类创建一个新的 PDF 文档。 代码如下
// Initialize a reader instance by specifying the path of the PDF file
PdfReader pdfReader = new PdfReader("sample.pdf");
// Initialize a document instance using the PdfReader
PdfDocument pdfDoc = new PdfDocument(pdfReader);// Initialize a reader instance by specifying the path of the PDF file
PdfReader pdfReader = new PdfReader("sample.pdf");
// Initialize a document instance using the PdfReader
PdfDocument pdfDoc = new PdfDocument(pdfReader);' Initialize a reader instance by specifying the path of the PDF file
Dim pdfReader As New PdfReader("sample.pdf")
' Initialize a document instance using the PdfReader
Dim pdfDoc As New PdfDocument(pdfReader)使用 IronPDF.
使用 IronPDF 打开 PDF 文件很容易。 使用 PdfDocument 类的 FromFile 方法从任何文件位置打开 PDF 文件。 以下一行代码打开了一个 PDF 文件以读取数据:
// Open a PDF file using IronPDF and create a PdfDocument instance
var pdf = PdfDocument.FromFile("sample.pdf");// Open a PDF file using IronPDF and create a PdfDocument instance
var pdf = PdfDocument.FromFile("sample.pdf");' Open a PDF file using IronPDF and create a PdfDocument instance
Dim pdf = PdfDocument.FromFile("sample.pdf")从 PDF 文件读取数据
使用 iText7 库
在 iText 7 库中读取 PDF 数据并不是那么简单。 我们必须手动遍历 PDF 文档的每一页以从每一页提取文本。 以下源代码帮助逐页提取 PDF 文档中的文本:
// Iterate through each page and extract text
for (int page = 1; page <= pdfDoc.GetNumberOfPages(); page++)
{
// Define the text extraction strategy
ITextExtractionStrategy strategy = new SimpleTextExtractionStrategy();
// Extract text from the current page using the strategy
string pageContent = PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(page), strategy);
// Output the extracted text to the console
Console.WriteLine(pageContent);
}
// Close document and reader to release resources
pdfDoc.Close();
pdfReader.Close();// Iterate through each page and extract text
for (int page = 1; page <= pdfDoc.GetNumberOfPages(); page++)
{
// Define the text extraction strategy
ITextExtractionStrategy strategy = new SimpleTextExtractionStrategy();
// Extract text from the current page using the strategy
string pageContent = PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(page), strategy);
// Output the extracted text to the console
Console.WriteLine(pageContent);
}
// Close document and reader to release resources
pdfDoc.Close();
pdfReader.Close();' Iterate through each page and extract text
Dim page As Integer = 1
Do While page <= pdfDoc.GetNumberOfPages()
' Define the text extraction strategy
Dim strategy As ITextExtractionStrategy = New SimpleTextExtractionStrategy()
' Extract text from the current page using the strategy
Dim pageContent As String = PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(page), strategy)
' Output the extracted text to the console
Console.WriteLine(pageContent)
page += 1
Loop
' Close document and reader to release resources
pdfDoc.Close()
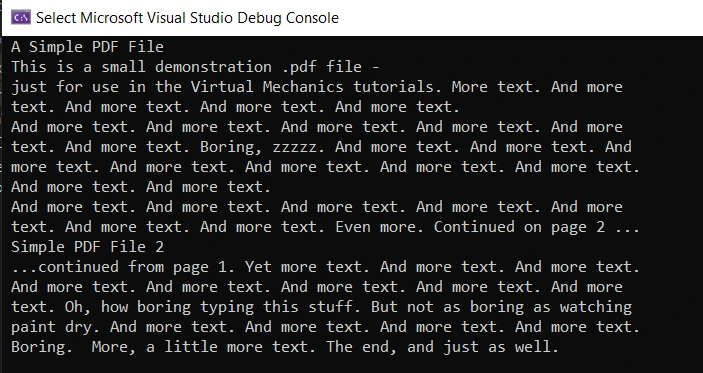
pdfReader.Close()上面的代码中有很多内容。 首先,我们声明文本提取策略,然后使用 PdfExtractor 类的 GetTextFromPage 方法读取文本。 此方法接受两个参数:第一个是 PDF 文档页码,第二个是策略。 要获取 PDF 文档页码,请使用 PdfDocument 实例调用 GetPage 方法,并将页码作为参数传递。 输出将作为字符串返回,然后显示在控制台输出屏幕上。 最后,PDFReader 和 PdfDocument 对象被关闭。 另外,查看以下关于 使用 iText7 从 PDF 提取文本 的代码示例。
输出
使用 IronPDF.
就像打开 PDF 文件是一行代码一样,从 PDF 文件中读取文本同样是一个一行的过程。 PDFDocument 类提供了 ExtractAllText 方法,用于从 PDF 中读取全部内容。 Console.WriteLine 用于在屏幕上打印文本。 代码如下:
// Extract all text from the PDF document
string text = pdf.ExtractAllText();
// Display the extracted text
Console.WriteLine(text);// Extract all text from the PDF document
string text = pdf.ExtractAllText();
// Display the extracted text
Console.WriteLine(text);' Extract all text from the PDF document
Dim text As String = pdf.ExtractAllText()
' Display the extracted text
Console.WriteLine(text)输出
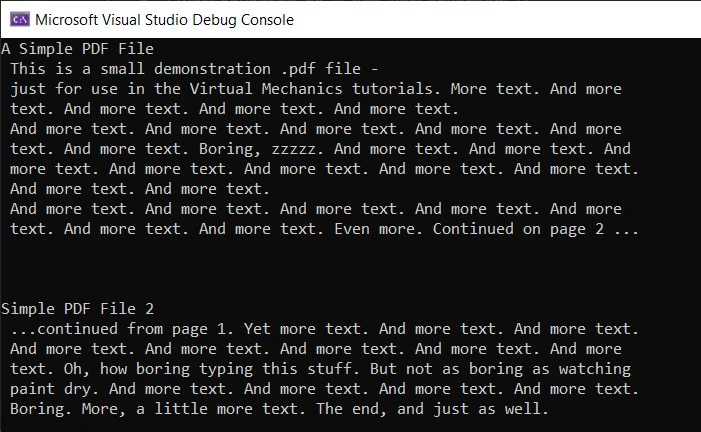
输出准确且没有任何错误。 但是,要使用 ExtractAllText 方法,您需要拥有许可证,因为它只能在生产模式下工作。 您可以从IronPDF 试用许可证页面获取 30 天的试用许可证密钥。
比较
对比中,两者在从 PDF 文档中提取文本时都能给出 100% 精确的结果。 在准确性方面,它们是相同的。 然而,IronPDF 在性能和代码可读性方面更具效率。
IronPDF 只需要两行代码就可以实现与 iText 相同的任务。 它提供现成的文本提取方法,无需额外的逻辑实现。 iText 代码有些棘手,您必须关闭在打开 PDF 文档时创建的两个实例。 而 IronPDF 则在任务完成后自动清除内存。
摘要
在本文中,我们研究了如何使用 iText 库在 C# 中读取 PDF 文档,然后与 IronPDF 进行了比较。 两个库都提供准确的结果,并提供众多的 PDF 操作方法进行使用。 您可以通过这两个库创建、编辑和读取 PDF 文件中的数据。
iText 是开源的,可以免费使用,但有一些限制。 它可以被许可用于商业用途。 IronPDF 也是免费使用的,可以被许可用于商业活动,带有 30 天的免费试用。
[{i:(iText 7 是其各自所有者的注册商标。 本网站与 iText 7 无关,未获得其认可或赞助。所有产品名称、徽标和品牌均为其各自所有者的财产。 比较仅供参考,反映撰写时公开可用的信息。)}]
常见问题解答
IronPDF 是什么,它与 iText 7 有何比较?
IronPDF 是一个 .NET 库,设计用于从 HTML、CSS 和 JavaScript 生成和操作 PDF 文档。相比 iText 7,IronPDF 强调速度、易用性和准确性,需要更少的代码行来完成 PDF 任务。
如何在C#中将HTML转换为PDF?
您可以使用 IronPDF 的 RenderHtmlAsPdf 方法将 HTML 字符串转换为 PDF。此外,您可以使用 RenderHtmlFileAsPdf 将 HTML 文件转换为 PDF。
在 C# 项目中安装 IronPDF 的步骤是什么?
要在 C# 项目中安装 IronPDF,请在 Visual Studio 中打开 NuGet 包管理器,搜索 IronPDF,选择它用于您的项目,然后点击安装。在您的 C# 文件顶部包含 using IronPDF;。
如何使用 IronPDF 从 PDF 中提取文本?
要使用 IronPDF 从 PDF 中提取文本,利用 PdfDocument 类的 FromFile 方法加载 PDF,然后使用 ExtractAllText 方法检索文本。
使用 IronPDF 时有哪些故障排除提示?
确保 IronPDF 通过 NuGet 正确安装,并且在您的 C# 文件中包含正确的命名空间。验证文件路径,并确保 HTML 内容在转换为 PDF 时结构良好。
IronPDF 能否处理 PDF 表单和注释?
是的,IronPDF 支持填写表单和添加注释等功能,允许您创建交互式和动态 PDF 文档。
IronPDF 是免费使用的吗?
IronPDF 提供一个限于功能的免费版本以及一个商业版本的 30 天免费试用,商业版本提供全功能。
使用 iText 7 进行 PDF 操作有哪些限制?
虽然 iText 7 是一个强大的 PDF 库,但对于某些任务如文本提取,需要额外的逻辑,这可能导致比使用 IronPDF 更复杂和冗长的代码。












