body parser node(开发者如何使用)
Node.js 是一种基于 Chrome 的 V8 JavaScript 引擎的强大 JavaScript 运行时,凭借其事件驱动、非阻塞 I/O 架构,Node.js 彻底改变了服务器端网络开发。 解析传入的请求体是使用 Node.js 快速处理 HTTP 请求过程中的一个常见步骤,对于网络开发和开发可靠的网络应用程序至关重要。 正文分析器中间件在这种情况下非常有用。
Body-parser 是著名的 Node.js 框架 Express.js 的中间件,通过简化处理程序之前对传入请求体的解析过程,可以更轻松地访问和修改客户端发送的数据。 Body-parser 中间件提供了一种高效的方法来处理不同的内容类型,如 JSON 有效负载、URL 编码表单或原始文本,从而使您的应用程序可以高效地处理用户输入。
另一方面,IronPDF 是适用于 Node.js 的强大 PDF 生成库。 它允许开发人员轻松地以编程方式创建、编辑和操作PDF文档。 将body-parser与IronPDF结合使用,为需要处理用户输入并基于该数据生成动态PDF文档的Web应用程序开辟了丰富的可能性。
在本文中,我们将探讨如何将 body-parser 与 Node.js 集成以处理 HTTP 请求,随后使用 IronPDF 从已解析的 body 对象生成 PDF 文档。 这种组合对于需要自动生成报告、创建发票或任何需要动态PDF内容的场景特别有用。
Body Parser的关键特性
JSON 解析
解析JSON格式的请求主体,使得使用这些主体解析器在API中处理JSON数据变得简单。
URL编码数据解析
解析 HTML 表单提交中常见的 URL 编码数据。 支持基本和复杂的对象结构。
原始数据解析
解析传入请求的原始二进制数据,帮助管理独特的数据格式和非标准内容类型。
文本数据解析
解析接收到的纯文本数据请求,使基于文本的内容处理变得简单。
可配置的大小限制
可对请求正文的大小进行限制,以防止重型有效载荷使服务器超载。 这有助于提高安全性和控制资源使用。
自动内容类型检测
根据 Content-Type 标头自动识别和处理请求正文,从而更高效地处理不同类型的内容,无需手动交互。
错误处理
强大的错误处理功能,确保应用程序能够礼貌地处理导致问题的请求,如无效的媒体格式、畸形的 JSON 或过大的正文。
与其他中间件集成
通过与现有的 Express 中间件无缝集成,实现模块化和有序的中间件堆栈。 这样可以提高应用程序的可维护性和灵活性。
扩展配置选项
提供配置选项以改变解析过程的行为,如修改文本解析的编码类型或定义 URL 编码数据的处理深度。
性能优化
有效管理解析操作,降低性能开销,并保证程序即使在负载较重的情况下也能保持响应速度。
在 Node.js 中创建和配置正文解析器
使用 Express.js 在 Node.js 应用程序中构建和设置 Body Parser
安装 Express 和 Body-Parser.
在命令行中使用以下 npm 命令安装 Express 和 Body-Parser 软件包:
npm install express
npm install body-parsernpm install express
npm install body-parser创建和配置应用程序
在您的项目目录中,创建一个名为app.js的新JavaScript文件,并为Express应用程序配置body-parser中间件:
const express = require('express');
const bodyParser = require('body-parser');
const app = express();
// Use body-parser middleware to parse JSON and URL-encoded data
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: true }));
// Example route that handles POST requests using the req.body property
app.post('/submit', (req, res) => {
const data = req.body;
res.send(`Received data: ${JSON.stringify(data)}`);
});
// Start the server
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});const express = require('express');
const bodyParser = require('body-parser');
const app = express();
// Use body-parser middleware to parse JSON and URL-encoded data
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: true }));
// Example route that handles POST requests using the req.body property
app.post('/submit', (req, res) => {
const data = req.body;
res.send(`Received data: ${JSON.stringify(data)}`);
});
// Start the server
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});处理不同的内容类型
此外,我们还可以设置 Body Parser 来处理多种数据,包括纯文本或原始二进制形式的数据:
原始数据解析
app.use(bodyParser.raw({ type: 'application/octet-stream' }));app.use(bodyParser.raw({ type: 'application/octet-stream' }));文本数据解析
app.use(bodyParser.text({ type: 'text/plain' }));app.use(bodyParser.text({ type: 'text/plain' }));错误处理
处理错误的中间件可用于管理正文解析过程中出现的潜在问题。
app.use((err, req, res, next) => {
if (err) {
res.status(400).send('Invalid request body');
} else {
next();
}
});app.use((err, req, res, next) => {
if (err) {
res.status(400).send('Invalid request body');
} else {
next();
}
});IronPDF 入门
什么是 IronPDF?
通过 IronPDF,开发人员可以以编程方式制作、修改和操作 PDF 文档。 IronPDF 是适用于 Node.js 的强大 PDF 生成库,支持多种功能,包括样式、脚本和复杂的布局,它使 HTML 资料转换为 PDF 的过程变得更简单。
使用 IronPDF 可以直接从网络应用程序生成动态报告、发票和其他文档。 对于任何需要 PDF 功能的应用程序来说,它都是一个灵活的解决方案,因为它可以轻松地与 Node.js 和其他框架进行交互。 IronPDF 是开发人员创建和修改 PDF 的首选工具,因为它具有广泛的功能集和易用性。
IronPDF 主要特性
将 HTML 转换为 PDF
在将 HTML 内容转换为 PDF 文档时,可以使用复杂的布局、CSS 和 JavaScript。 允许开发者使用现有的网页模板创建 PDF。
渲染的高级选项
提供页码、页脚和页眉的选择。 支持水印、背景图片和其他复杂的布局元素。
编辑和处理 PDFs
允许在已有的 PDF 文档中进行页面修改、页面合并和页面分割。 允许在 PDF 中添加、删除或重新排列页面。
安装 IronPDF
要启用 IronPDF 功能,请使用 Node Package Manager 在 Node.js 中安装必要的软件包。
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdf使用 IronPDF 创建报告 PDF.
通过 IronPDF 和 Node.js 中的 Body Parser 协同工作,开发人员可以处理请求数据并高效地生成动态 PDF 文档。 这是在 Node.js 应用程序中配置和使用这些功能的详细操作方法。
使用Body Parser和IronPDF建立Express应用程序,然后创建一个名为app.js的文件。
const express = require('express');
const bodyParser = require('body-parser');
const IronPdf = require("@ironsoftware/ironpdf");
const app = express();
// Middleware to parse JSON and URL-encoded data
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: true }));
// Route to handle PDF generation
app.post('/generate-pdf', async (req, res) => {
const data = req.body;
// HTML content to be converted into PDF
const htmlContent = `
<html>
<head></head>
<body>
<h1>${JSON.stringify(data, null, 2)}</h1>
</body>
</html>
`;
try {
// Create an instance of IronPDF document
const document = await IronPdf.PdfDocument.fromHtml(htmlContent);
// Convert to PDF buffer
let pdfBuffer = await document.saveAsBuffer();
// Set response headers to serve the PDF
res.setHeader('Content-Type', 'application/pdf');
res.setHeader('Content-Disposition', 'attachment; filename=generated.pdf');
// Send the PDF as the response
res.send(pdfBuffer);
} catch (error) {
console.error('Error generating PDF:', error);
res.status(500).send('Error generating PDF');
}
});
// Start the server
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});const express = require('express');
const bodyParser = require('body-parser');
const IronPdf = require("@ironsoftware/ironpdf");
const app = express();
// Middleware to parse JSON and URL-encoded data
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: true }));
// Route to handle PDF generation
app.post('/generate-pdf', async (req, res) => {
const data = req.body;
// HTML content to be converted into PDF
const htmlContent = `
<html>
<head></head>
<body>
<h1>${JSON.stringify(data, null, 2)}</h1>
</body>
</html>
`;
try {
// Create an instance of IronPDF document
const document = await IronPdf.PdfDocument.fromHtml(htmlContent);
// Convert to PDF buffer
let pdfBuffer = await document.saveAsBuffer();
// Set response headers to serve the PDF
res.setHeader('Content-Type', 'application/pdf');
res.setHeader('Content-Disposition', 'attachment; filename=generated.pdf');
// Send the PDF as the response
res.send(pdfBuffer);
} catch (error) {
console.error('Error generating PDF:', error);
res.status(500).send('Error generating PDF');
}
});
// Start the server
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});在此配置中,IronPDF 用于生成 PDF,同时结合 Node.js Body Parser 的功能。 首先,我们导入所需的模块,如用于生成 PDF 的 IronPDF、用于解析传入请求正文的 Body Parser 和用于构建服务器的 Express。 接下来,我们设置了 Express 中间件,使用 Body Parser 解析 JSON 和 URL 编码的表单数据。
为了处理 POST 请求,我们建立了一个名为 generate-pdf 的路由,并在其中接收请求正文的内容。 这些 JSON 格式的数据将整合到一个 HTML 模板中,作为 PDF 的内容使用。 我们使用IronPdf实例化一个文档,并将HTML内容转换为PDF文档。
PDF 成功生成后,我们会发送带有适当标头的响应,以指示文件名和内容类型。 错误处理可确保在创建 PDF 时出现的任何问题都能被识别、记录并通过相关状态代码传达给客户。
输出
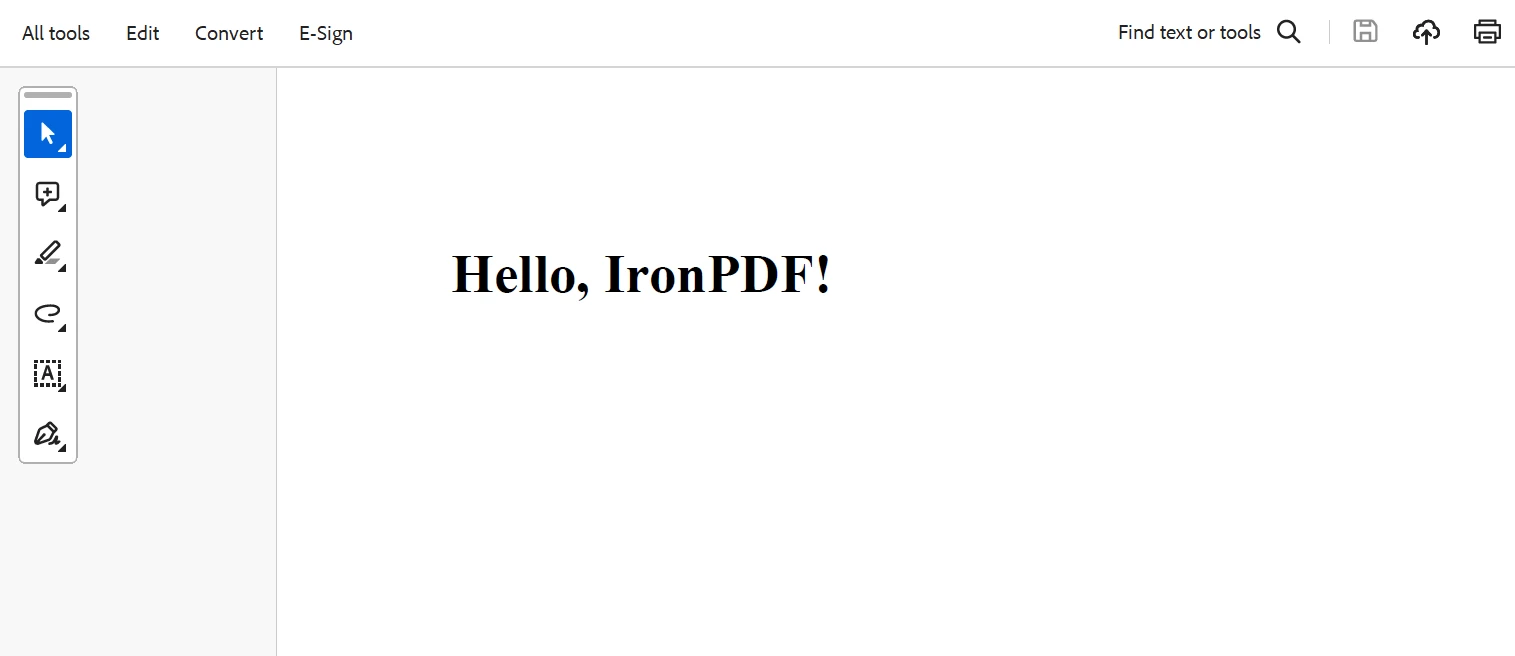
最后,服务器启动,并在指定端口上等待接收请求。 通过这种配置,使用 Body Parser 的请求处理和 IronPDF 的动态 PDF 生成可以轻松集成到 Node.js 应用程序中,从而实现更有效的数据处理和文档生成工作流。
结论
总而言之,IronPDF和 Node.js 中的 Body Parser 的组合提供了一种稳定的方式来管理 HTTP 请求正文数据并创建动态 PDF 文档,供在线应用程序使用。 开发人员可以使用 Body Parser 更轻松地访问和修改传入数据,该工具可简化解析不同类型请求体的过程。
另一方面,IronPDF 具有强大的功能,可以根据 HTML 文本制作具有高级功能、格式和样式的高质量 PDF 文档。 通过结合这些技术,开发人员可以根据应用数据或用户输入更快地生成定制的 PDF 文档。 在此集成的帮助下,Node.js 应用程序现在可以更有效地处理用户生成的内容,并输出看起来很专业的 PDF。
通过将 IronPDF 和 Iron Software 产品集成到您的开发堆栈中,我们可以保证为客户和最终用户提供功能丰富的高端软件解决方案。 此外,这将有助于项目和流程的优化。 Iron Software 的定价始于$799,由于其详尽的文档、活跃的社区和频繁的升级,他们是现代软件开发项目的可靠合作伙伴。