

如何在 Node.js 中读取 PDF 文件
在不断发展的网络开发世界中,Node.js已成为一个强大的平台,允许开发人员构建可扩展且高效的应用程序。 Node.js的一个迷人之处在于它能够与各种库和模块无缝协作,从而扩展其功能。 在本文中,我们将深入探讨Node.js的PDF阅读器功能,探索IronPDF库及其在处理PDF文件时的应用。
什么是Node.js PDF阅读器?
Node.js PDF阅读器是一种专门设计的工具,用于在Node.js环境中便捷地读取和操作PDF(可移植文档格式)文件。 PDF文件因其在不同平台间格式一致性而被广泛用于文档分享。 将PDF读取功能整合到Node.js应用中,提供了从提取信息到生成动态报告的众多可能性。
如何使用Node.js PDF阅读器读取PDF?
- 安装Node.js PDF阅读器库。
- 导入所需的依赖项。
- 使用
PdfDocument.open方法打开PDF文件。 - 使用
extractText方法从PDF文件中提取文本。 - 使用
console.log方法在控制台上显示提取的文本。
2. IronPDF for Node.js介绍
IronPDF是Node.js生态系统中用于处理PDF文件的全面库。 它提供了一系列功能,使其成为需要以编程方式操作PDF文档的开发人员的首选。 由Iron Software团队开发的IronPDF,以其简单性和易于集成到Node.js项目中而著称。
2.1. IronPDF的关键功能
- PDF生成: IronPDF允许开发人员从头创建PDF文档,提供对内容、格式和布局的全面控制。
- PDF解析: 库可以从现有的PDF文件中提取文本、图像和其他元素,使开发人员能够处理这些文档中存储的数据。
- PDF修改: IronPDF支持修改现有的PDF文件,可以动态地添加、删除或更新内容。
- PDF渲染: 借助IronPDF,开发人员可以将PDF文件渲染成各种格式,包括从图像或从HTML,扩展在Web应用中显示PDF内容的可能性。
- 跨平台兼容性: IronPDF设计为能在不同操作系统无缝工作,确保无论部署环境如何,其行为始终一致。
2.2. 安装IronPDF
在深入了解IronPDF的功能之前,您需要在Node.js项目中安装该库。 安装过程很简单,可以使用NPM包管理器来完成。 打开您的终端并运行以下命令:
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdf这个命令安装了IronPDF库,并使其可用于您的Node.js应用程序。
要安装使用IronPDF库所必需的IronPDF引擎,请在控制台中运行以下命令:
npm install @ironsoftware/ironpdf-engine-windows-x64npm install @ironsoftware/ironpdf-engine-windows-x643. 使用Node.js和IronPDF读取PDF文件
使用Node.js和IronPDF读取PDF文件涉及一系列简单步骤,提供的代码示例演示了实现这一目标的简洁而强大的方法。 该代码利用@ironsoftware/ironpdf包中打开并提取PDF文件中的文本。让我们逐步解析代码:
导入
PdfDocument:import { PdfDocument } from "@ironsoftware/ironpdf";import { PdfDocument } from "@ironsoftware/ironpdf";JAVASCRIPT代码首先从IronPDF库中导入
PdfDocument类。 该类提供了用于处理PDF文档的方法,例如打开、提取文本和执行各种操作。打开PDF文件:
const pdf = await PdfDocument.open("output.pdf");const pdf = await PdfDocument.open("output.pdf");JAVASCRIPTPdfDocument.open方法用于打开一个PDF文件。在此示例中,指定的文件为"output.pdf"。 使用open方法返回一个Promise。这确保代码在PDF完全加载后再继续进行下一步。从PDF提取文本:
const text = await pdf.extractText();const text = await pdf.extractText();JAVASCRIPT一旦PDF打开后,在
extractText方法。 此方法异步提取PDF文档中的文本内容。 结果存储在text变量中。记录提取的文本:
console.log(text);console.log(text);JAVASCRIPT最后,提取的文本使用
console.log记录到控制台。 这一步对开发人员至关重要,以验证文本提取过程是否成功,并检查从示例PDF中提取的内容。async函数包装器:(async () => { // Code goes here })();(async () => { // Code goes here })();JAVASCRIPT整个代码通过使用
async关键字的立即调用函数表达式(IIFE)被包装在一个异步函数中。 这允许在函数内部使用await,从而实现异步操作,如加载PDF和提取文本。
总而言之,这段代码展示了一个简洁而有效的使用Node.js和IronPDF读取PDF文件的方法。 通过利用IronPDF库的功能,开发人员可以轻松打开PDF文档,提取文本内容,并将这些功能集成到其Node.js应用中。
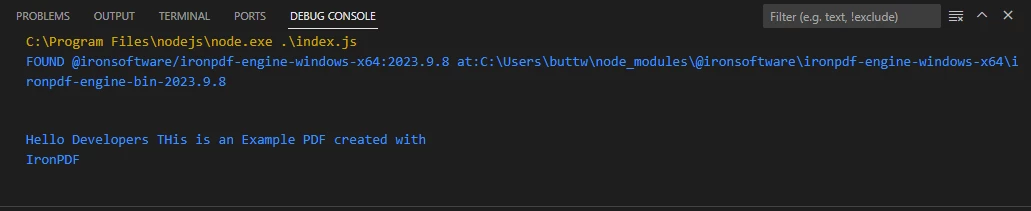 从示例PDF文件中提取的文本
从示例PDF文件中提取的文本
3.1. 读取受密码保护的PDF文件
读取受密码保护的PDF文件需要解决保护文档内容的额外安全层。 在这种情况下,至关重要的是使用支持密码认证的PDF阅读库,如IronPDF。
该过程包括在文件打开阶段提供正确的密码,使得可以解密PDF中的内容。 这确保只有授权用户可以访问和提取受密码保护的PDF文件的信息,提高了这些文档中敏感数据的安全性。
const pdf = await PdfDocument.open("encrypted.pdf", "password");const pdf = await PdfDocument.open("encrypted.pdf", "password");使用上述代码,用户可以读取受密码保护的PDF文件内容。
3.2. 读取PDF文件元数据
IronPDF for Node.js提供读取PDF文件元数据的功能。 下面的代码将演示如何从PDF文件中读取元数据。
import { PdfDocument } from "@ironsoftware/ironpdf";
(async () => {
// Step 1. Import a PDF
const pdf = await PdfDocument.open("output.pdf");
const metadata = await pdf.getMetadata();
console.log("\n");
console.log(metadata);
})();import { PdfDocument } from "@ironsoftware/ironpdf";
(async () => {
// Step 1. Import a PDF
const pdf = await PdfDocument.open("output.pdf");
const metadata = await pdf.getMetadata();
console.log("\n");
console.log(metadata);
})();输出
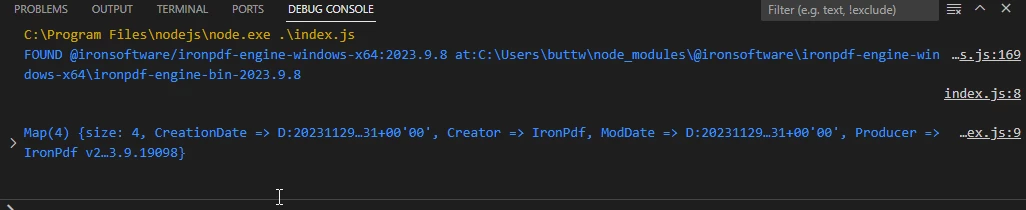 从示例PDF文件中提取的元数据
从示例PDF文件中提取的元数据
4. 结论
总之,Node.js PDF阅读器,特别是在利用IronPDF库时,为与PDF文件打交道的开发人员打开了一个可能性的世界。 无论是提取文本、图像,还是动态修改现有文档,IronPDF都为在Node.js环境中处理PDF提供了一套多功能的工具。 它还支持表格数据,PDF阅读模块提取文本条目。
要开始使用Node.js PDF阅读器和IronPDF,请按照本文中概述的步骤操作。 探索 文档,了解更多深入信息和高级使用案例。 拥有合适的工具和知识,您可以通过无缝集成PDF读取功能来增强您的Node.js应用程序。
为什么使用IronPDF for Node.js?
- 免费试用: IronPDF for Node.js提供免费试用IronPDF for Node.js,允许开发人员在做出承诺前探索其功能。 这个试用期使用户能够在无经济承诺的情况下评估该库对其特定PDF相关任务的适用性。 2.功能丰富: IronPDF for Node.js 功能丰富,为在 Node.js 中处理 PDF 文件提供了一套全面的功能。 从PDF生成到文本提取和文档修改,该库提供了一个强大的工具包,使其适用于广泛的应用。
- 代码示例和文档/支持: IronPDF提供了广泛的文档和支持,使开发人员易于集成和使用其功能。 该库附带详细的Node.js PDF 转换示例,便于开发人员顺利学习,并确保他们拥有成功实施所需的资源。
常见问题解答
如何在Node.js中读取PDF文件?
要在Node.js中读取PDF文件,可以通过npm安装IronPDF。导入必要的依赖项并使用PdfDocument.open方法加载PDF。使用extractText方法提取文本内容,并将结果输出到控制台。
在Node.js中使用PDF库的好处是什么?
在Node.js中使用像IronPDF这样的PDF库提供了PDF生成、解析和修改等好处。它通过提供强大的PDF处理能力,包括跨平台兼容性和无缝集成,增强了Node.js应用程序。
如何在 Node.js 项目中安装 IronPDF?
要在Node.js项目中安装IronPDF,使用npm命令:npm install @Iron Software/ironpdf。另外,安装IronPDF引擎,使用npm install @Iron Software/ironpdf-engine-windows-x64确保完整功能。
我可以在Node.js中读取受密码保护的PDF吗?
是的,IronPDF允许您在Node.js中读取受密码保护的PDF。在PDF打开过程中提供正确的密码以解密和访问内容。
如何使用Node.js从PDF中提取元数据?
在Node.js中使用IronPDF,可以通过PdfDocument.open方法打开文档,并使用getMetadata方法检索元数据详细信息,从而从PDF中提取元数据。
是什么让IronPDF在Node.js PDF操作中成为受欢迎的选择?
IronPDF在Node.js开发人员中很受欢迎,因为其丰富的功能、广泛的文档以及支持。它提供了免费试用,使其可用于测试和集成到各种应用程序中。
IronPDF如何在Node.js项目中确保跨平台兼容性?
IronPDF被设计为在不同操作系统上保持一致的性能,确保您的Node.js项目无论在何种部署平台上都能可靠地运行。
我在哪里可以找到更多关于在Node.js中使用IronPDF的资源?
欲了解更多关于在Node.js中使用IronPDF的资源和示例,请访问Iron Software官方网站。浏览其文档和教程,以获得有关PDF操作的全面指导。















