
使用 Python 进行分布式计算
分布式 Python
在快速变化的技术领域,对可扩展和有效的计算解决方案的需求比以往任何时候都更大。 对于涉及大量分布式数据处理、并发用户请求和计算密集型任务的工作,分布式计算越来越有必要。 为了使开发人员能够充分利用分布式 Python,我们将在本文中探讨其应用、原则和工具。
在 Web 开发领域,动态生成和修改 PDF 文档是一项常见需求。 能够以编程方式创建 PDF 有助于即时报告、发票和证书等的创建。
Python 的广泛生态系统和多功能性使其能够处理大量 PDF 库。 IronPDF 是一个强大的解决方案,帮助开发者通过简化创建PDF的过程,以及实现任务并行和分布式计算,充分利用他们的基础设施。
理解分布式 Python
从根本上说,分布式 Python 是将计算工作分成更小的块,并在多个节点或处理单元之间进行划分的过程。 这些节点可以是连接到网络的独立设备、系统中的独立 CPU 核心、远程对象、远程函数、远程或函数调用执行,甚至单进程内的独立线程。 目标是通过并行化工作负载来提高性能、可扩展性和容错性。
Python 用户友好、适应性强且具有丰富的库生态系统,成为分布式计算工作负载的绝佳选择。 Python 为分布式计算提供了丰富的工具,适用于所有规模和用途,从强大的框架如 Celery, Dask 和 Apache Spark,到内置模块如 multiprocessing 和 threading。
在深入细节之前,让我们先来讨论分布式 Python 建立的基本思想和原则:
并行与并发
并行指的是同时执行多个任务,而并发则涉及处理同时推进进程但不一定是同时的多任务。 分布式 Python 涵盖了并行和并发,具体取决于任务内容和系统的设计。
任务分配
并行和分布式计算的一个关键组成部分是将工作分配到多个节点或处理单元中。 无论计算程序中的函数执行是如何并行化的,有效的工作分配对于优化整体性能、效率和资源使用至关重要。
通信与协调
在分布式系统中,节点之间的有效通信和协调对于促进远程函数执行、复杂工作流、数据交换和计算同步的编排至关重要。
分布式 Python 程序受益于例如消息队列、分布式数据结构和远程过程调用(RPC)等技术,从而实现远程和实际函数执行之间的顺畅协调和通信。
可靠性与错误防范
系统通过在不同机器上添加节点或处理单元来适应增长的工作负载的能力称为可扩展性。 相反,容错性指的是设计能够承受例如机器故障、网络分段和节点崩溃等故障并仍然可靠运行的系统。
分布式 Python 框架通常包括容错和自动扩展功能,以确保分布式应用在多台机器上的稳定性和弹性。
分布式 Python 的应用
数据处理与分析: 可以使用像 Apache Spark 和 Dask 这样的分布式Python框架并行处理大型数据集,使得分布式Python应用程序可进行批处理、实时流处理和大规模机器学习等活动。
使用微服务的Web开发: 可以结合分布式任务队列如 Celery 使用Python web框架如 Flask 和 Django 来构建可扩展的web应用和微服务架构。 Web 应用程序可能容易集成的功能包括分布式缓存、异步请求处理和后台作业处理。
科学计算与模拟: 得益于 Python 丰富的科学库和分布式计算框架的生态系统,高性能计算(HPC)和跨设备集群的并行模拟成为可能。 应用包括金融风险分析、气候建模、机器学习应用、物理学和计算生物学模拟。
边缘计算和物联网(IoT): 随着 IoT 设备和边缘计算设计的普及,分布式 Python 在处理传感器数据、协调边缘计算进程、一起构建分布式应用程序以及实践分布式机器学习模型以便于现代边缘应用等方面变得尤为重要。
分布式 Python 的创建与使用
使用 Dask-ML 进行分布式机器学习
一个叫做 Dask-ML 的强大库扩展了并行计算框架 Dask ,用于涉及机器学习的作业。 在集群的多核或处理器上将任务分配,可以让 Python 开发人员有效地以分布式方式在巨大的数据集中训练和应用机器学习模型。
import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")使用 Ray 的并行函数调用
借助强大的分布式计算框架 Ray ,您可以在集群的多个内核或计算机上并发执行Python函数或任务。 通过利用 @ray.remote 装饰器,Ray 使您能够将函数指定为远程函数。 之后,这些远程任务或操作可以在集群的 Ray 工作者上异步执行。
import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()开始
什么是 IronPDF?
借助知名的 IronPDF for .NET 包,我们可以在 .NET 程序中创建、修改和呈现 PDF 文档。 PDF 处理有许多不同的方法:从 HTML 内容、照片或原始数据创建新的 PDF 文档到提取现有文档中的文本和图像、将 HTML 页面转换为 PDF、向已有文档中添加文字、图像和图形。
IronPDF 简单易用是它的主要优势之一。 开发人员可以轻松在他们的 .NET 应用程序中开始生成 PDF,依赖于其用户友好的 API 和详细的文档。 IronPDF 的速度和效率是使开发者能够快速生成高质量PDF文档的另一个特点。
IronPDF 的一些优势:
- 从原始数据、图像和 HTML 创建 PDF。
- 从 PDF 文件中提取图像和文本。
- 在PDF文件中添加页眉、页脚和水印。
- PDF 文件具有密码和加密保护功能。
- 具有填充和电子签名文档的能力。
使用 IronPDF 进行分布式 PDF 生成
分布式Python框架如 Dask 和 Ray 使得能够在集群的多个内核或计算机之间分配任务。 这使得复杂任务如并行 PDF 生成可以在集群中执行,利用其中的多个核心,从而大大减少创建大量 PDF 所需的时间。
首先使用 pip 安装 IronPDF 和 ray 库:
pip install ironpdf
pip install celerypip install ironpdf
pip install celery这是一些概念性的Python代码,展示了使用 IronPDF 和 Python 进行分布式 PDF 生成的两种方法:
具有中央工作者的任务队列
中央工作者 (worker.py):
from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])客户脚本 (client.py):
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()Celery 是我们使用的任务队列系统。 作业与包含HTML内容的数据一起发送到中央工作者(worker.py)。 该函数使用 IronPDF 创建PDF并保存。
客户端脚本(client.py)将包含示例数据的任务发送到队列。 这个脚本可以更改以从不同的计算机发送其他任务。
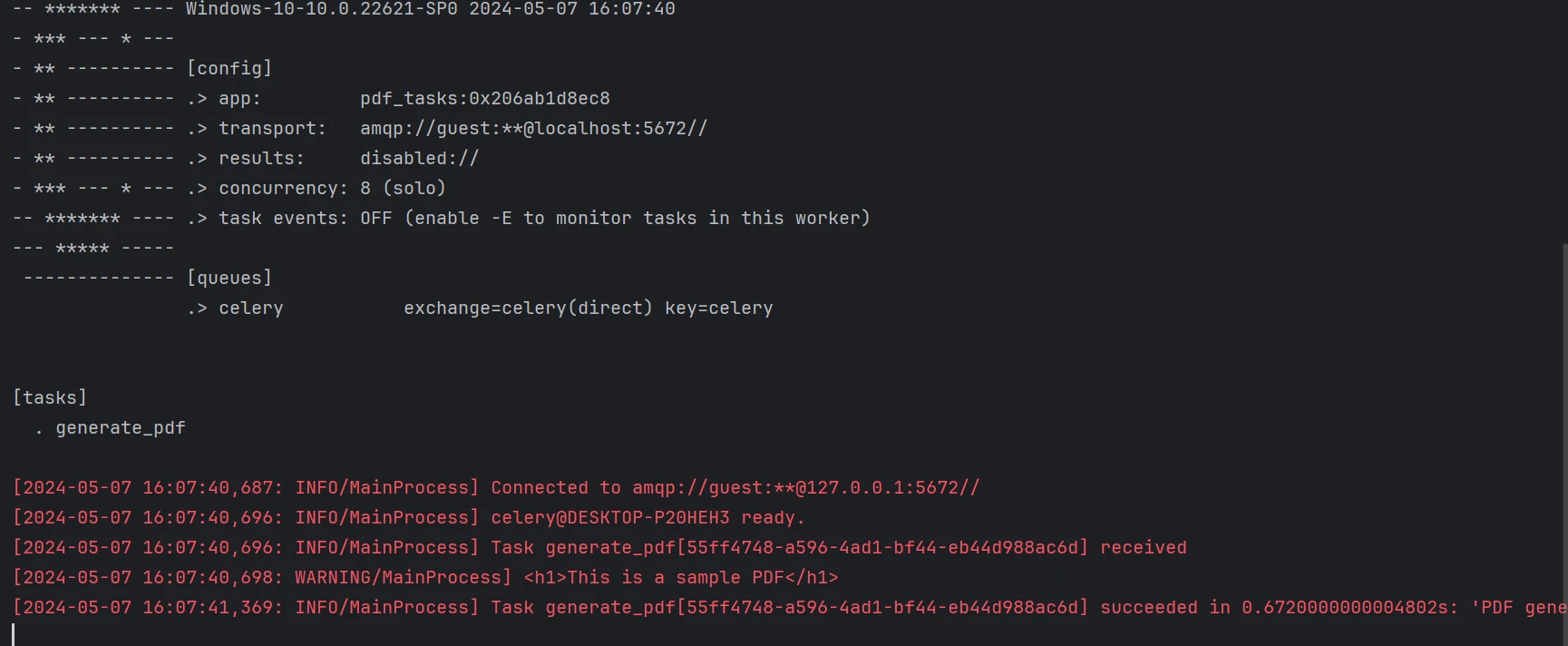
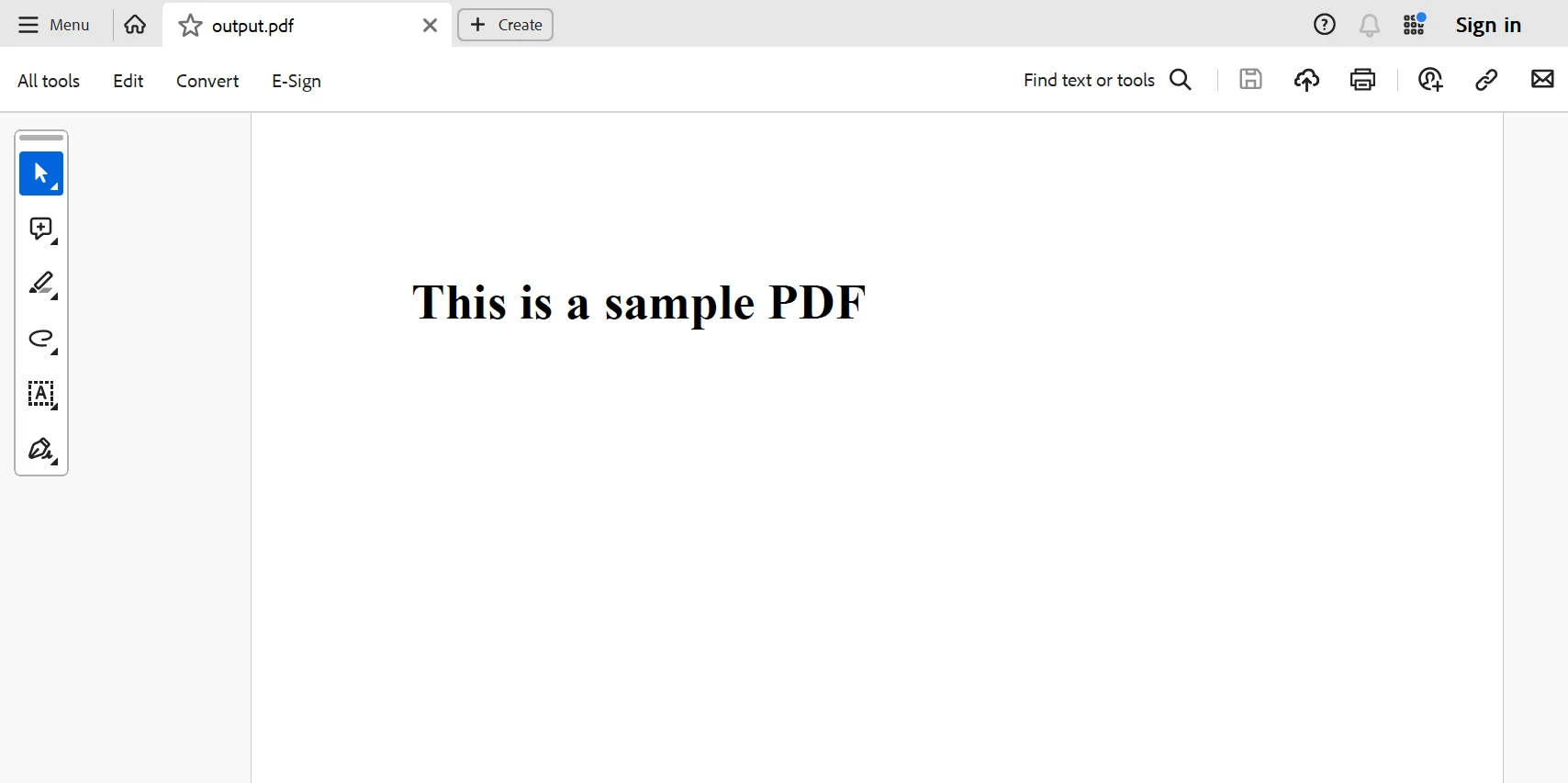
下面是来自上述代码的生成 PDF。
结论
处理大规模PDF创建活动的 IronPDF 用户可以通过利用分布式Python和像 Ray 或 Dask 这样的库来释放巨大潜力。 与在单台机器上执行代码相比,通过将相同的代码工作负载分散到多个核心并在多台机器上使用,可以获得显著的速度提升。
IronPDF 可以从一个在单一系统上创建PDF的强大工具提升为一个有效管理大数据集的可靠解决方案,使用分布式Python编程语言。 为了在您的下一个大规模PDF创建项目中充分利用 IronPDF,请研究所提供的Python库并尝试这些方法!
IronPDF 以合理的价格作为一个软件包购买,并附带终生许可证。 这个软件包性价比很高,对于许多系统,只需 $799 就可以购买。 它为许可持有人提供24/7的在线工程支持。 有关收费的更多信息,请访问网站。要了解更多 Iron Software 生产的产品,请访问此页面。
















