
Pandas Python 数据科学指南
Pandas 是 Python 编程语言中一种流行的数据分析工具,以其易用性和处理表格数据的多功能性而著称。 本指南将带您了解使用 Pandas 的基本要点,重点介绍数据操作和分析的实用示例和高效技术。
理解 DataFrame:Pandas 的核心
1. 在 Pandas 中访问数据
Pandas 的主要结构是 DataFrame,这是一个强大的数据分析和操控工具。 首先,让我们探索如何访问 DataFrame 中的数据。
1.1 从 CSV 文件加载数据
例如,如果您有一个包含数据的 CSV 文件,可以将其加载到 DataFrame 中并开始进行操作。 以下代码演示了如何从 CSV 文件中加载数据:
import pandas as pd
# Load data from a CSV file into a DataFrame
df = pd.read_csv('your_file.csv')import pandas as pd
# Load data from a CSV file into a DataFrame
df = pd.read_csv('your_file.csv')1.2 访问列数据
加载数据后,有多种方式可以在 DataFrame 中访问数据。 您可以使用列名访问列数据。 例如,下面的代码访问名为 'data' 的列中的数据:
# Access data from a column named 'data'
column_data = df['data']# Access data from a column named 'data'
column_data = df['data']1.3 访问行数据
类似地,您还可以使用行索引或条件访问行数据:
# Accesses the first row of the DataFrame
row_data = df.loc[0]# Accesses the first row of the DataFrame
row_data = df.loc[0]2. 处理 DataFrames 中的空值
数据分析中的一个常见问题是处理空值。 Pandas 提供了可靠的方法来处理这些问题。 代码可以用指定的值填充空值,或者您可以删除包含空值的行或列。 以下是一个如何填充空值的代码示例:
# Fill null values in the DataFrame with 0
df.fillna(0, inplace=True)# Fill null values in the DataFrame with 0
df.fillna(0, inplace=True)3. 创建和操作列
DataFrames 可以灵活地创建新列。 无论是新的整数列还是从现有数据派生的列,过程都非常简单。 以下是向 DataFrame 添加新列的示例:
# Add a new column 'new_column' by multiplying an existing column by 10
df['new_column'] = df['existing_column'] * 10# Add a new column 'new_column' by multiplying an existing column by 10
df['new_column'] = df['existing_column'] * 10您还可以根据条件筛选数据。 例如,如果要创建一个新列,其数据来自名为 'column_named_data' 且大于某个值的列:
# Create a new column 'filtered_data' based on the condition
df['filtered_data'] = df[df['column_named_data'] > value]# Create a new column 'filtered_data' based on the condition
df['filtered_data'] = df[df['column_named_data'] > value]高级数据操作技术
1. 分组和聚合数据
Pandas 在分组和聚合数据方面表现出色。 以下代码使用 groupby 方法,按指定列分组数据并计算均值、求和等聚合函数:
# Group data by 'column_name' and calculate the mean
grouped_data = df.groupby('column_name').mean()# Group data by 'column_name' and calculate the mean
grouped_data = df.groupby('column_name').mean()2. 日期和时间数据
在许多数据集中,处理日期和时间是至关重要的。 如果您的 DataFrame 具有日期列,Pandas 简化了按日期过滤、按月或年聚合等任务。下面是一个基本示例:
# Convert 'date_column' to datetime format
df['date_column'] = pd.to_datetime(df['date_column'])# Convert 'date_column' to datetime format
df['date_column'] = pd.to_datetime(df['date_column'])3. 自定义数据操作
对于更复杂的数据操作需求,Pandas 允许您编写自定义函数并将其应用于 DataFrame。 这对于需要语言集成查询方法的场景特别有用。
def custom_function(row):
# Perform custom manipulation on each row
return modified_row
# Apply custom function to each row in the DataFrame
df = df.apply(custom_function, axis=1)def custom_function(row):
# Perform custom manipulation on each row
return modified_row
# Apply custom function to each row in the DataFrame
df = df.apply(custom_function, axis=1)可视化和显示数据
Pandas 与 Matplotlib 和 Seaborn 等库集成良好进行数据可视化。 以视觉格式显示数据可以像以下源代码中展示的那么简单:
import matplotlib.pyplot as plt
# Plot a bar chart for data visualization
df.plot(kind='bar')
plt.show()import matplotlib.pyplot as plt
# Plot a bar chart for data visualization
df.plot(kind='bar')
plt.show()结合 IronPDF 和 Pandas 在 Python 中提升数据分析
正如我们所讨论的,Pandas 是一个用于 Python 中数据操作和分析的强大工具。 凭借其能力,IronPDF 由 Iron Software 开发的库,提供额外的功能,可以提升数据分析工作流程,尤其是在处理 PDF 内容时。
IronPDF:概述
IronPDF 是一个多功能的 Python PDF 库,专门用于在 Python 项目中创建、编辑和提取 PDF 内容。 它被设计为可跨平台使用,包括 Windows、Mac、Linux 和云环境,适用于各种 Python 项目。 此库在处理 PDF 文件方面表现尤为出色,提供了无缝的体验和高效的处理,这对处理 PDF 数据的开发人员来说至关重要。
与 Pandas 的协同作用
将 IronPDF 与 Pandas 结合使用,可以为更高级的数据处理和报告提供可能性。 想象一下一个分析工作流程,您可以使用 Pandas 进行数据操作和分析,然后无缝地将结果和可视化内容转换成专业格式的 PDF 报告使用 IronPDF。 这种整合可以显著简化分享和展示数据分析结果的过程。
结论
总之,虽然 Pandas 为数据分析提供了基础,结合 IronPDF 为 Python 中的数据分析工作流增加了新的维度。 这种组合不仅提高了数据操作和分析过程的效率,还显著改善了数据的展示和分享方式,对于基于 Python 的数据分析师和科学家来说是一种非常宝贵的资产。
IronPDF 为有兴趣在购买前探索其功能的用户提供。
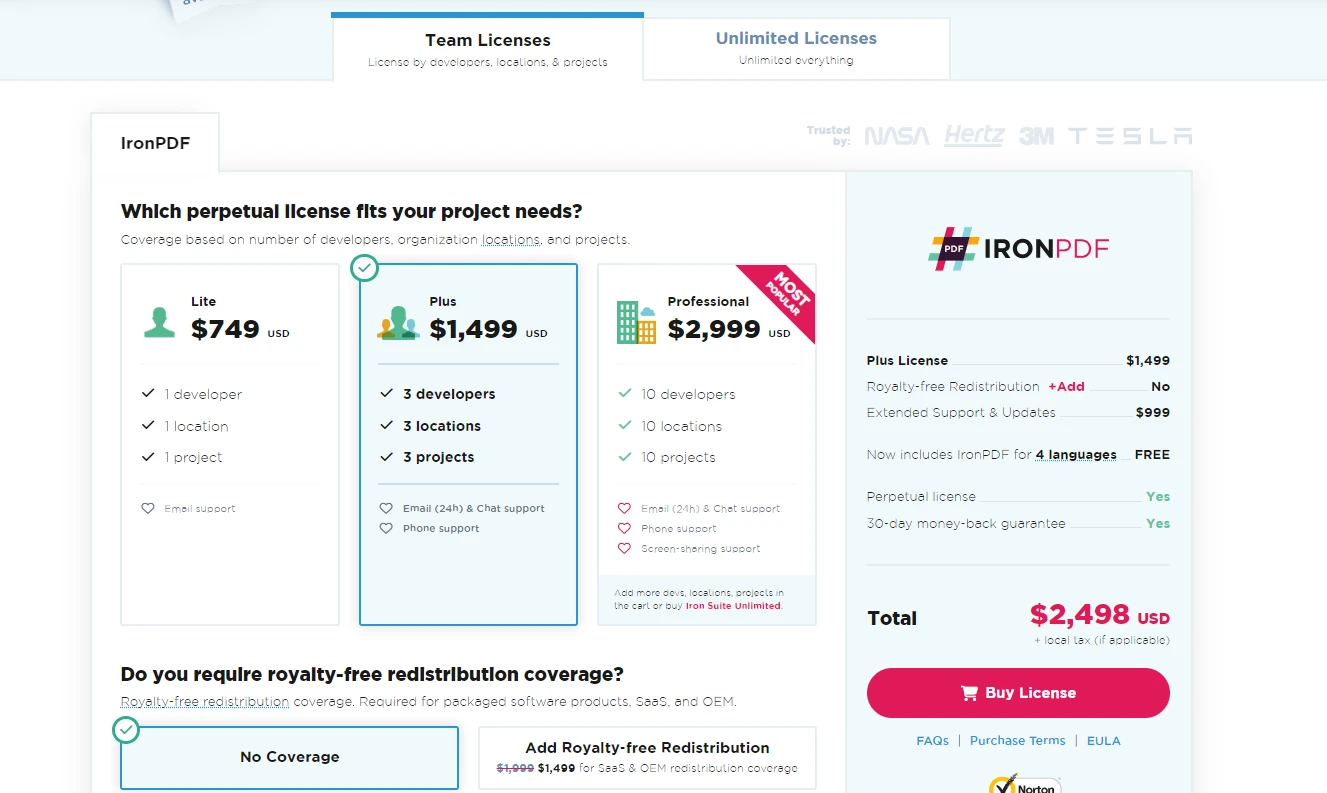
对于那些希望获得完整许可证的人,IronPDF 允许用户选择最适合其项目需求和预算的计划。
















