
如何在 Python 中读取 PDF 文件
PDF,或可移植文档格式文件,已成为共享文档的通用标准。 由于它们能够保留文档的布局和格式,因此被广泛使用。 然而,使用像 Python 这样的编程语言操作 PDF 文件可能会有些挑战。 本文介绍了 IronPDF,一个 Python PDF 库,允许我们对 PDF 文档执行各种操作。
IronPDF for Python PDF 库
IronPDF 是一个高级 Python PDF 库,可简化 PDF 文件格式的操作。 它提供了一个易于使用的 API,用于各种 PDF 操作。 您可以读取和写入 PDF 文件,将 PDF 文件转换为不同格式,合并多个 PDF 文件等。 它还可以处理页面对象,从 PDF 文件的所有页面中提取文本,旋转 PDF 页面,以及其他功能。
如何在 Python 中读取 PDF 文件
- 使用 Pip 安装 Python PDF 库。
- 在 Python 脚本中导入 Python PDF 库。
- 应用 PDFReader Python 库的许可证密钥。
- 提供文档路径以加载任何 PDF 文档。
- 在 Python 控制台上读取 PDF 内容。
使用 IronPDF 读取 PDF 文件
使用 IronPDF 读取 PDF 文件涉及几个步骤。 这里是一个简单的指南来帮助您入门:
步骤 1 在 Visual Studio 中创建虚拟环境
使用 Python 时,创建一个称为虚拟环境的独立环境至关重要。 该环境允许您管理特定于您正在进行的项目的依赖项,而不会干扰其他项目。 在集成开发环境 (IDE) 中创建虚拟环境变得更加简单,如 Visual Studio Code。 为此,请按照以下步骤操作:
- 在 Visual Studio Code 中打开文件夹。 按 Ctrl+Shift+P 打开命令面板。 在命令面板中,搜索"Python: Create Environment"。

- 选择第一个选项,然后选择"Venv"作为环境类型。

- 之后,选择 Python 解释器,它将开始创建虚拟环境。

现在,您的隔离工作区已准备好用于 Python 脚本,确保项目依赖项限制在此环境内。
![]()
步骤 2 安装 IronPDF for Python 库
虚拟环境设置好之后,您就可以安装 IronPDF for Python 库。 您可以使用 Python 包管理器 'pip' 安装它:
pip install ironpdfpip install ironpdf步骤 3 安装 .NET 6.0
IronPDF for Python 需要安装 .NET 6.0 SDK。
请从 微软 .NET 网站下载并安装 .NET 6.0 SDK。
步骤 4 导入 IronPDF
成功安装 IronPDF 后,下一步就是将其导入到您的 Python 脚本中。 导入库会使其所有的功能和方法在您的脚本中可用。 您可以使用以下代码导入 IronPDF:
from ironpdf import *from ironpdf import *这行代码将 IronPDF 库中的所有模块、函数和类导入到您的脚本中。
步骤 5 应用许可证密钥
要完全解锁 IronPDF 库的功能,您需要应用一个许可证密钥。 应用许可证密钥就像将密钥分配给License属性一样简单。 以下是如何操作的:
License.LicenseKey = "License-Key-Here"License.LicenseKey = "License-Key-Here"用您的实际IronPDF许可证密钥替换"License-Key-Here"。 有了许可证密钥,您现在可以在 Python 脚本中充分利用 IronPDF 库的全部潜力。
步骤 6 设置日志路径
接下来,为 IronPDF 操作设置日志记录。 通过设置自定义日志路径,您可以存储库生成的运行时日志,帮助您调试和诊断执行期间可能发生的问题。 这是如何设置的:
# Enable debugging mode for detailed logs
Logger.EnableDebugging = True
# Set the path for the log file
Logger.LogFilePath = "Custom.log"
# Set logging mode to capture all log types
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging mode for detailed logs
Logger.EnableDebugging = True
# Set the path for the log file
Logger.LogFilePath = "Custom.log"
# Set logging mode to capture all log types
Logger.LoggingMode = Logger.LoggingModes.All在这个代码片段中,Logger.LoggingMode = Logger.LoggingModes.All确保记录所有类型的日志信息。
步骤7 加载PDF文档
使用 IronPDF 加载 PDF 文档就像调用一个方法一样简单。 PdfDocument.FromFile方法将PDF文档从给定路径加载到PDF文件对象中。 您只需要以字符串形式提供 PDF 文件的路径:
pdf = PdfDocument.FromFile("PDF B.pdf")pdf = PdfDocument.FromFile("PDF B.pdf")在这个代码中,PdfDocument对象。
步骤 8 读取 PDF 文件内容
IronPDF提供了一个名为ExtractAllText()的方法,有助于从PDF文档中提取文本内容。 当您需要读取和分析 PDF 文件的内容时,这尤其方便:
all_text = pdf.ExtractAllText() # Extracts all text from the PDF document
print(all_text) # Prints the extracted text to the consoleall_text = pdf.ExtractAllText() # Extracts all text from the PDF document
print(all_text) # Prints the extracted text to the console在这个例子中,pdf对象中的所有PDF文件文本。 您可以在控制台上读取 PDF 内容。
步骤 9 加载第二个 PDF 文件
像加载第一个 PDF 文档一样,您也可以加载第二个 PDF 文档。 此功能在您想要操作多个 PDF 文件时非常有用:
pdf_2 = PdfDocument.FromFile("PDF A.pdf")pdf_2 = PdfDocument.FromFile("PDF A.pdf")在这个代码中,PdfDocument对象。
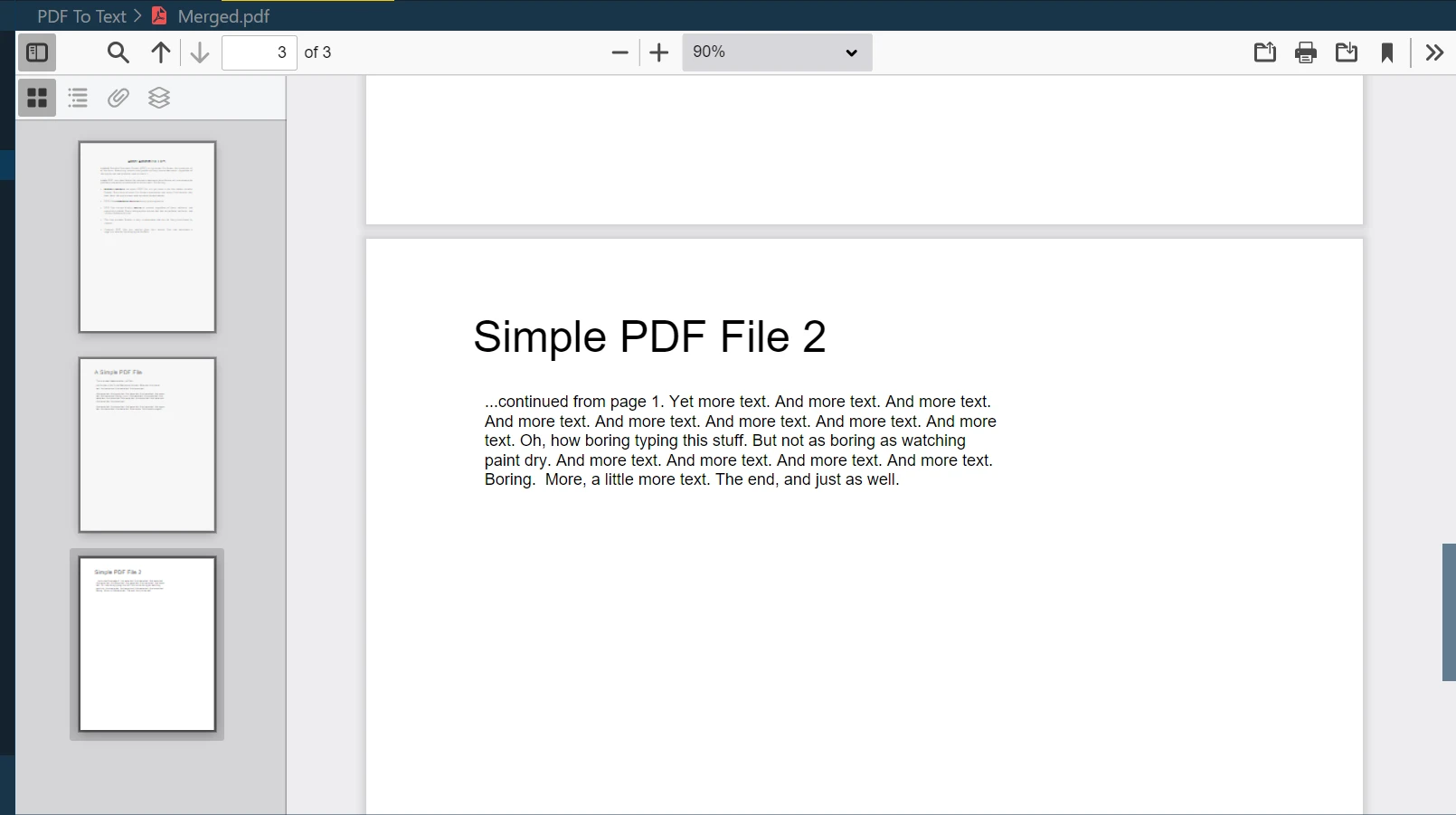
步骤 10 合并两个文件
IronPDF的强大功能之一是合并多个PDF文件为一个新的PDF文件。您可以使用PdfDocument.Merge方法轻松组合两个或多个PDF文档:
merged = PdfDocument.Merge(pdf, pdf_2) # Merges pdf and pdf_2 documents
merged.SaveAs("Merged.pdf") # Saves the merged document as 'Merged.pdf'merged = PdfDocument.Merge(pdf, pdf_2) # Merges pdf and pdf_2 documents
merged.SaveAs("Merged.pdf") # Saves the merged document as 'Merged.pdf'在这个例子中,pdf_2合并后的结果。 SaveAs方法随后将此合并的文档保存为"Merged.pdf"。
步骤 11 拆分第一个 PDF
IronPDF 还允许您 拆分一个 PDF 文档 并将特定页面提取到新的 PDF 文件中。 这是通过使用CopyPage方法完成的:
page1doc = pdf.CopyPage(0) # Copies the first page of the pdf document
page1doc.SaveAs("Split1.pdf") # Saves the copied page as a new document 'Split1.pdf'page1doc = pdf.CopyPage(0) # Copies the first page of the pdf document
page1doc.SaveAs("Split1.pdf") # Saves the copied page as a new document 'Split1.pdf'这里,pdf文档的第一页。 然后将该页面保存为名为 "Split1.pdf" 的输出 PDF。

步骤 12 应用水印
水印是 IronPDF 提供的另一个令人印象深刻的功能。 您可以使用所需的文本或图像为 PDF 文档加水印。 pdf对象表示的PDF添加水印。
pdf.ApplyWatermark("<h2 style='color:red'>SAMPLE</h2>", 30, VerticalAlignment.Middle, HorizontalAlignment.Center)
pdf.SaveAs("Watermarked.pdf")pdf.ApplyWatermark("<h2 style='color:red'>SAMPLE</h2>", 30, VerticalAlignment.Middle, HorizontalAlignment.Center)
pdf.SaveAs("Watermarked.pdf")在这个代码片段中,ApplyWatermark将文字"SAMPLE"的红色水印应用于PDF的中间中心。 然后,SaveAs将水印文档保存为"Watermarked.pdf"。
然后,SaveAs 将带水印的文档保存为 "Watermarked.pdf"。
- IronPDF 是一个功能多样的 Python 库,兼容广泛的 Python 版本。 5. 它支持从 Python 3.6 及以上的所有现代 Python 版本。 6. IronPDF 不受限于单一操作系统。 7. 它是平台独立的,因此可以在多种操作系统上使用。 8. 无论是 Windows、Mac 还是 Linux,IronPDF 在这些平台上都能无缝工作。 9. 这种跨平台兼容性是一个巨大的优势,使 IronPDF 成为开发者毫无顾虑选择的工具,无论他们的操作系统偏好如何。
结论
- 总之,IronPDF 是一个出色的 Python 库,简化了处理 PDF 文档的过程。 11. 无论您是否需要合并多个 PDF、提取文本、拆分 PDF 文件或应用水印,IronPDF 都能满足您的需求。 12. 它与多个平台的兼容性和易用性使其成为任何与 PDF 文档打交道的开发者的宝贵工具。
IronPDF 提供免费试用。 它对多个平台的兼容性和易用性使其成为任何开发者处理 PDF 文档的宝贵工具。 一旦您测试完毕,可以从$799开始购买许可证。
















