
如何在 Python 中从 PDF 提取文本
本文将演示如何使用 Python 中的 IronPDF 从 PDF 文件中提取所有文本,并为您提供高效完成此任务所需的知识和 Python 代码片段。
- 下载从 PDF 中提取文本的 Python 模块。
- 使用 `FromFile` 方法导入 PDF 文件
- 使用 `ExtractText` 方法从导入的 PDF 中提取文本
- 使用 `ExtractTextFromPage` 方法从特定页面提取文本
- 将提取的文本输出到控制台或文本文件
IronPDF - Python 库
IronPDF for Python是一个功能强大的 Python PDF 库,允许开发人员从 PDF 文档中提取文本。 使用 IronPDF,您可以自动从 PDF 文件中提取文本内容的数据,从而更轻松地处理和分析 PDF 文档中包含的信息。
IronPDF 为 Python 程序员提供了使用 Python 操作 PDF 文件、从 PDF 文件中提取数据以及与 PDF 文件交互的功能,从而更容易实现各种与 PDF 相关的任务的自动化。 无论您需要生成 PDF、修改现有 PDF、从内容中提取数据,还是执行其他 PDF 操作,IronPDF 都能凭借其直观的 API 和强大的功能简化流程。
主要功能
IronPDF for Python 库的一些特性包括:
前提条件
在使用 IronPDF 进行文本提取之前,请确保已满足以下先决条件:
- Python 安装:请确保您的系统上已安装 Python。 IronPDF 与 Python 3.x 版本兼容,因此请确保您已安装兼容的 Python 版本。
IronPDF库:使用
pip(Python包管理器)安装IronPDF库。 打开命令行界面并执行以下命令:pip install ironpdfpip install ironpdfSHELL注意:必须将 Python 添加到 PATH 环境变量中才能使用 pip 命令。
3.集成开发环境 (IDE):虽然并非绝对必要,但使用 IDE 可以极大地提升您的开发体验。 它提供了代码补全、调试和更简化的工作流程等功能。 PyCharm 是 Python 开发中一款流行的 IDE。 您可以从 JetBrains 网站https://www.jetbrains.com/pycharm/下载并安装 PyCharm。 4.文本编辑器:或者,如果您更喜欢使用轻量级的文本编辑器,您可以选择任何文本编辑器,例如 Visual Studio Code、Sublime Text 或 Atom。 这些编辑器为 Python 开发提供了语法高亮和其他实用功能。 你也可以使用 Python 自带的 IDLE 应用。
使用 PyCharm 创建 Python 项目
安装 PyCharm IDE 后,按照以下步骤创建一个 PyCharm Python 项目:
1.启动 PyCharm:从系统应用程序启动器或桌面快捷方式打开 PyCharm。 2.创建新项目:点击"创建新项目"或打开一个现有的 Python 项目。
PyCharm IDE
3.配置项目设置:为您的项目提供一个名称,并选择创建项目目录的位置。 为您的项目选择 Python 解释器。 然后点击"创建"。
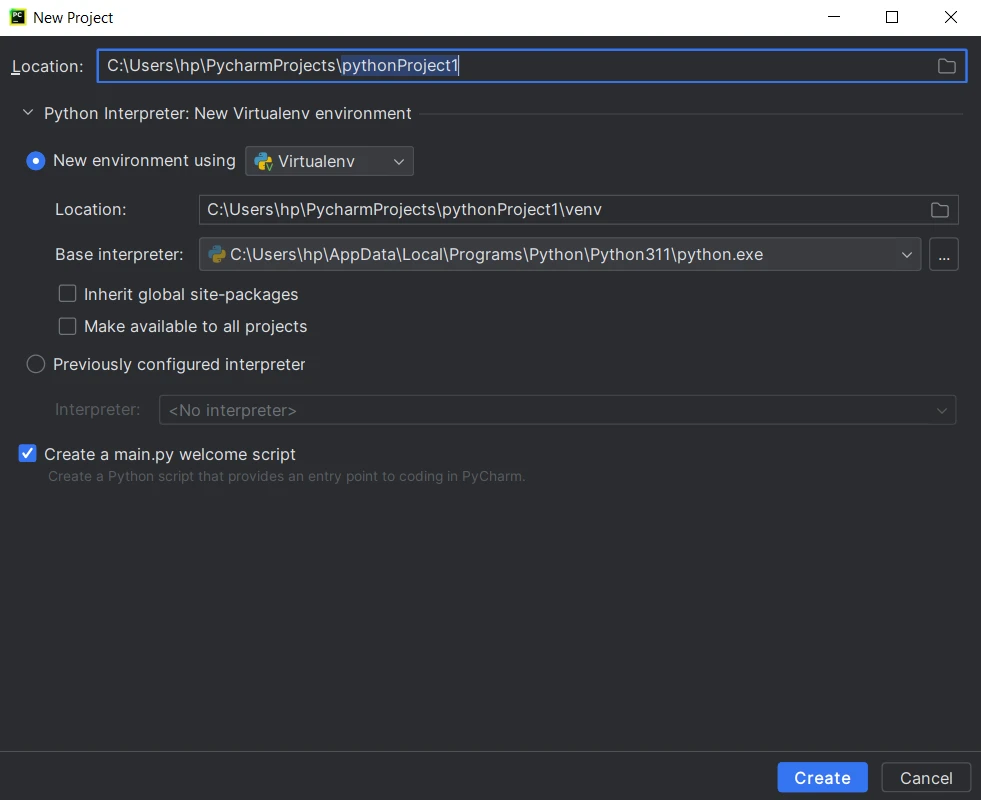
**在 PyCharm 中创建一个新的 Python 项目**4.创建源文件: PyCharm 将创建项目结构,包括一个主 Python 文件和一个用于存放其他源文件的目录。 开始编写代码,然后单击运行按钮或按 Shift+F10 执行脚本。
使用 IronPDF 在 Python 中从 PDF 中提取文本
现在让我们深入了解使用 Python 编程语言中的 IronPDF 从 PDF 文件中提取纯文本的步骤。
导入所需库
首先,在你的Python脚本中导入必要的库。 在这种情况下,代码示例需要导入IronPDF库,该库提供了处理 PDF 文件的功能。
import ironpdfimport ironpdf设置许可证密钥
要使用 IronPDF 从 PDF 文件中提取全文,您需要拥有 IronPDF 许可证。 使用以下命令应用许可证或试用密钥:
# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"注意:如果没有许可证密钥,IronPDF 只能从 PDF 文件中提取少量字符。您可以通过购买 IronPDF或注册免费试用版来获取许可证密钥。
加载 PDF 文档
接下来,使用IronPDF中的PdfDocument.FromFile()方法加载PDF文件。 请将 PDF 文件的路径作为参数传递给此方法。 这将把PDF文件加载到PdfDocument对象中。
pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")输入文件
要从输入的 PDF 文件中提取文本并将其打印到屏幕上,请使用以下文档:
 输入文件
输入文件
从 PDF 文件中提取文本
一旦PDF文档被加载,您可以使用ExtractText方法提取文本内容。 此方法将提取的文本作为字符串返回。
text = pdf.ExtractText()text = pdf.ExtractText()处理和利用提取的文本
现在您已经从 PDF 中提取了文本,可以根据您的需求对其进行处理和利用。 您可以执行诸如解析文本、分析文本、将文本存储在数据库中或将其用于进一步数据处理等任务。
# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted text# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted text输出
 从控制台提取的文本
从控制台提取的文本
从 PDF 文件中的特定页面提取文本
IronPDF还提供了一个方便的方法从PDF文件中的特定页面提取文本。本节将探讨如何使用IronPDF提供的ExtractTextFromPage方法从特定页面提取文本。
以下代码演示了如何从特定页面中提取文本:
# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)在上面的示例代码中,PdfDocument对象。 ExtractTextFromPage()方法用于从特定页面提取文本,页面索引作为参数传递。 在这种情况下,文本是从第二页或页码 2 中提取的,对应于页码索引 1。
 从第 2 页提取文本
从第 2 页提取文本
结论
本文探讨了如何使用 Python 中的 IronPDF 从 PDF 文件中提取文本。 它涵盖了必要的步骤,包括导入所需的库、加载 PDF 文档、提取文本内容以及处理提取的文本。
IronPDF 强大的文本提取功能,可以自动从 PDF 中提取和进一步处理文本,使您能够轻松处理和分析 PDF 文档中的文本信息。 它直观的 API 和强大的功能使其成为 Python 开发中各种 PDF 相关任务的理想选择。
IronPDF 可免费用于开发用途,但商业用途需要获得许可。 要在生产模式下进行测试,请获取免费试用版。 下载并安装最新版本的IronPDF for Python ,然后试用一下。
常见问题解答
如何使用Python从整个PDF文档中提取文本?
您可以通过使用IronPDF的PdfDocument.FromFile()方法来加载PDF,然后调用ExtractText()方法来检索文本内容,从整个PDF文档中提取文本。
在Python中从PDF的特定页面提取文本的过程是什么?
要从PDF的特定页面提取文本,请使用IronPDF的ExtractTextFromPage()方法,该方法允许您指定页面索引以从该特定页面检索文本。
如何安装Python的IronPDF库?
通过运行命令pip install ironpdf,使用pip包管理器安装Python的IronPDF库。
在Python中从PDF提取文本所需的先决条件是什么?
先决条件包括在系统上安装Python,通过pip安装IronPDF,并使用如PyCharm的IDE进行开发。
Python的IronPDF库是否有免费版本可用?
IronPDF免费用于开发目的,但商业用途需要许可证。提供免费试用以测试库的生产模式。
使用IronPDF从PDF中提取完整文本需要许可证吗?
是的,使用IronPDF从PDF中完全提取文本需要许可证密钥。没有许可证的情况下,提取仅限于几个字符。
IronPDF for Python 的一些关键特性是什么?
Python的IronPDF的关键功能包括创建和编辑PDF,提取文本、元数据和图像,将PDF转换为其他格式,以及添加诸如密码之类的安全功能。
Python的IronPDF能否帮助自动化PDF数据提取?
是的,IronPDF提供了FromFile和ExtractText等方法,这些方法有助于自动化PDF数据提取,帮助进行数据分析和处理。
推荐用于Python中使用IronPDF的IDE是哪个?
由于PyCharm具有代码补全、调试工具和简化的工作流程,因此推荐用于Python开发的IronPDF。
IronPDF如何提升我在处理PDF文档时的工作流程?
IronPDF通过提供直观的API来进行文本提取、PDF创建和编辑、格式转换和安全设置,从而简化各种PDF相关任务并提高工作流程。
















