
如何在 Python 中解析 PDF 文件
1.0 介绍
现代库简化了 PDF 的创建。 在为 PDF 项目选择库时,请考虑其构建、读取和转换功能,以实现最佳集成和性能。 Python 提供了诸如 IronPDF 之类的工具,可以高效地解析现有的 PDF 文件。
2.0 IronPDF
Python 是一种编程语言,它使开发人员能够快速轻松地构建图形用户界面。 与其他语言相比,它为程序员提供了更大的灵活性。 因此,将 IronPDF 库与 Python 集成是一个简单的过程。
为了快速、安全地构建功能齐全的 GUI,开发人员可以利用几个预装工具,包括 PyQt、wxWidgets、Kivy 以及许多其他软件包和库。 值得注意的是,IronPDF 并不是一个纯粹的 Python PDF 库; 相反,它允许包含来自其他框架(如 .NET Core)的各种功能。
IronPDF 简化了 Python Web 设计和开发,这主要得益于 Django、Flask 和 Pyramid 等 Python Web 开发范式的流行。 包括 Reddit、Mozilla 和 Spotify 在内的知名网站和在线服务都使用了这些框架。 您可以在IronPDF for Python 网站上了解更多关于 IronPDF 中 Python 的信息。
2.1 IronPDF 的特点
- IronPDF 能够从各种来源生成 PDF 文件,包括 HTML、HTML5、ASPX 和 Razor/MVC View。 它提供了从 HTML 页面和图像创建 PDF 的功能。
- IronPDF 工具包提供了一系列工具,用于执行诸如创建交互式 PDF、填写和提交交互式表单、拆分和合并PDF 文件、从 PDF 文件中提取文本和图像、在 PDF 文件中搜索特定单词、将 PDF 页面栅格化为图像、将 PDF 转换为 HTML 等任务。 IronPDF 支持用户代理、代理、cookie、HTTP 标头和形状变量,从而可以验证 HTML 登录表单。
- 通过用户名和密码,可以访问 IronPDF 中的受保护文档。
- IronPDF 只需几行代码即可从字符串、流、URL 等各种来源生成 PDF 文件并进行打印。
3.0 安装 Python
3.1 环境搭建
请确保您的电脑上已安装Python。 访问官方Python网站,下载并安装适用于您操作系统的最新版本Python。 Python 安装完成后,设置一个虚拟环境来隔离项目的依赖项。 使用"venv"模块创建和管理虚拟环境,为您的转换项目提供一个干净、独立的工作空间。
3.2 PyCharm中的新项目
我们将使用 PyCharm(一款用于编写 Python 代码的 IDE)进行本次演示。
启动 PyCharm IDE 后,点击"新建项目"。
 PyCharm 欢迎界面
PyCharm 欢迎界面
选择"新建项目"后,将弹出一个新窗口,允许您指定项目的位置及其环境。 这个新窗口可以在下面的截图中看到。
 PyCharm中的新建项目界面
PyCharm中的新建项目界面
设置项目位置和环境路径后,单击"创建"按钮开始新项目。 这将打开一个新窗口,可以在其中开发程序。 本教程推荐使用 Python 3.9 版本。
 在 PyCharm 中打开的主文件
在 PyCharm 中打开的主文件
3.3 IronPDF 库要求
IronPDF 是一个 Python 库,主要依赖于 .NET 6.0。因此,要使用 Python 版 IronPDF,您的电脑必须安装 .NET 6.0 运行时环境。 在Linux和Mac用户可以使用这个Python模块之前,可能需要安装.NET。 您可以从.NET 网站获取所需的运行时环境。
3.4 IronPDF库设置
要创建、编辑和打开扩展名为".pdf"的文件,需要安装"ironpdf"软件包。 要在 PyCharm 中安装包,打开终端窗口并键入以下命令:
pip install ironpdfpip install ironpdf下面的截图显示了"ironpdf"软件包的设置。
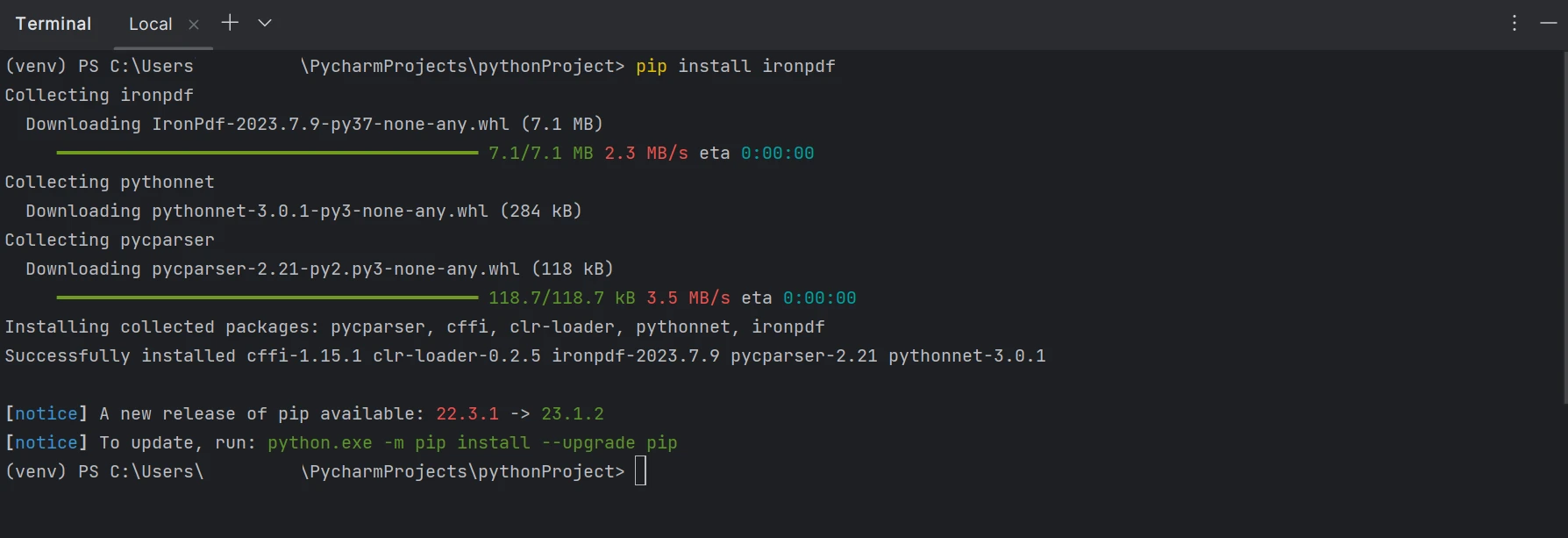 终端显示使用 pip 安装 IronPDF 的过程。
终端显示使用 pip 安装 IronPDF 的过程。
4.0 使用 IronPDF 解析 PDF
借助 IronPDF 库,可以从 PDF 文件中提取文本。 IronPDF 提供了多种文本提取技术。 第一种方法是将页面上的所有内容检索为一个字符串。 第二种方法是从第一页开始,一页一页地阅读内容。 以下代码片段演示了使用 IronPDF 检查当前 PDF 文件的模式。
从PDF文件中提取数据有两种方法:
- 从 PDF 中按页提取。
- 将整个 PDF 提取为文本。
下面这个PDF文件将用于本文。 它有两页。
 PDF 文件,每页顶部都有页码
PDF 文件,每页顶部都有页码
4.0.1 按页提取文本
下面提供的示例代码演示了如何使用页码从 PDF 文件中检索数据。
from ironpdf import PdfDocument
# Open a PDF file and create a PDF document object
pdfDocument = PdfDocument.FromFile("F:\\PDF\\1.pdf")
# Extract text from the first page (index 0)
AllText = pdfDocument.ExtractTextFromPage(0)
# Print the extracted text from the first page
print(AllText)from ironpdf import PdfDocument
# Open a PDF file and create a PDF document object
pdfDocument = PdfDocument.FromFile("F:\\PDF\\1.pdf")
# Extract text from the first page (index 0)
AllText = pdfDocument.ExtractTextFromPage(0)
# Print the extracted text from the first page
print(AllText)代码片段演示了使用FromFile函数读取PDF文件并创建PDF文档对象。 此对象允许访问 PDF 中的文本和图像。 要从特定页提取文本,可以使用ExtractTextFromPage方法,并将页码作为参数提供。 此方法将返回一个字符串,其中包含指定页面上的所有单词。 输出结果将显示如下。
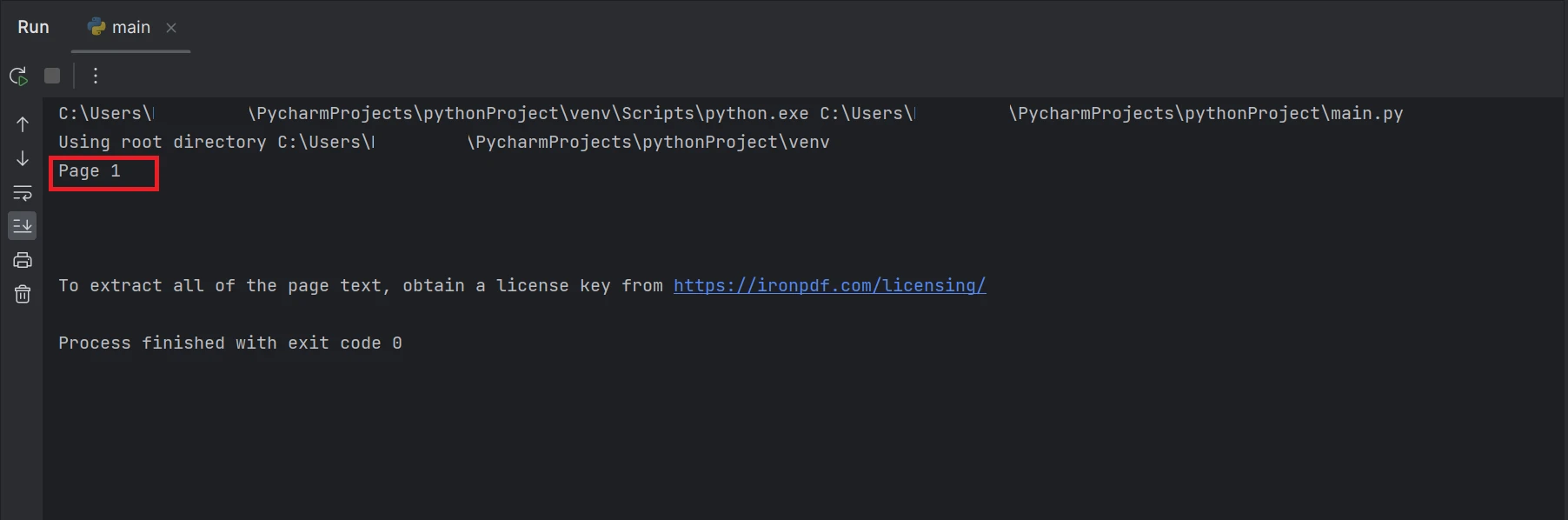 终端屏幕截图,显示文本输出"第 1 页"
终端屏幕截图,显示文本输出"第 1 页"
结果中突出显示的矩形框是从 PDF 文件第 1 页(索引为 0)提取的数据文本。
4.0.2 从所有页面提取
下面的代码示例展示了快速简便地将所有 PDF 内容作为字符串获取的第一种方法。
from ironpdf import PdfDocument
# Create a PDF file object from the file path
pdf = PdfDocument.FromFile('F:\\PDF\\1.pdf')
# Extract all text from the entire PDF
all_text = pdf.ExtractAllText()
# Print the extracted text from the entire PDF
print(all_text)from ironpdf import PdfDocument
# Create a PDF file object from the file path
pdf = PdfDocument.FromFile('F:\\PDF\\1.pdf')
# Extract all text from the entire PDF
all_text = pdf.ExtractAllText()
# Print the extracted text from the entire PDF
print(all_text)上述示例代码说明了如何从现有文件路径读取PDF并使用FromFile函数将其转换为PDF文件对象。 PDF的纯文本将被提取并通过对象的ExtractAllText函数转换为字符串,并在终端上打印出提取的文本。 结果将如下所示。
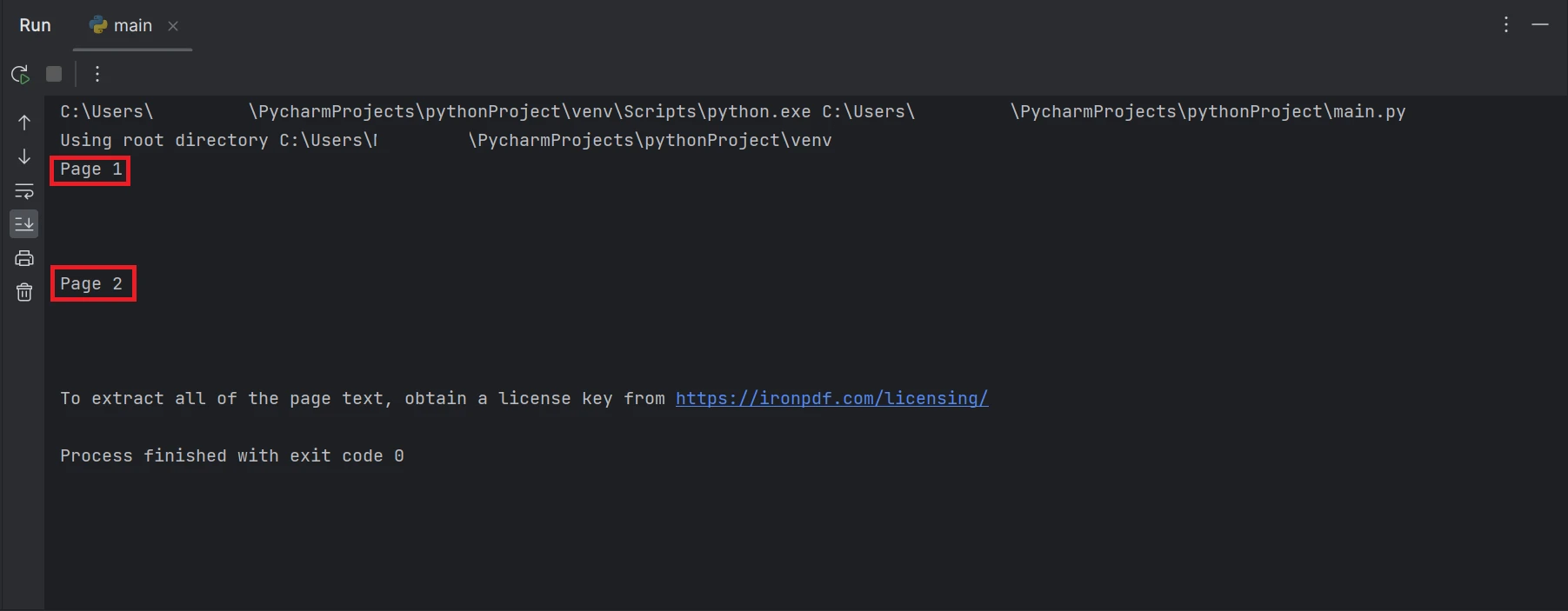 终端屏幕截图,显示文本输出"第 1 页"和"第 2 页"。
终端屏幕截图,显示文本输出"第 1 页"和"第 2 页"。
结果中高亮显示的矩形框包含了从 PDF 文件所有页面中提取的数据文本。
借助 IronPDF,我们可以使用 C# 创建 PDF 文件。 要了解更多关于 IronPDF 的信息,请访问IronPDF 网站。
5.0 结论
为了最大限度地降低风险并确保数据安全,IronPDF 库提供了强大的安全措施。 它与所有常用浏览器兼容,不局限于任何单一浏览器。 IronPDF 使程序员只需几行代码即可轻松创建和读取 PDF 文件。 为了满足开发人员的各种需求,IronPDF库提供多种许可选项,包括一个免费的开发者许可和其他可购买的开发许可。
$799 Lite软件包附带永久许可证、30天退款保证、一年的软件支持以及升级可能性。 除首次购买外,没有其他额外费用。 这些许可在生产、阶段和开发环境中使用。 IronPDF还提供一些具有时间和再分发限制的免费许可。 在免费试用期内,用户可以在无水印的情况下实际体验产品。 有关 IronPDF 试用版的费用和许可详情,请访问IronPDF 许可页面。
常见问题解答
如何使用 Python 解析 PDF 文档?
您可以在 Python 中使用 IronPDF 解析 PDF 文档。该库允许您创建 PDF 文档对象并使用如 ExtractTextFromPage 这样的方法从特定页面提取文本,或者使用 ExtractAllText 从整个文档提取文本。
在 Python 环境运行 IronPDF 的先决条件是什么?
要在 Python 环境中运行 IronPDF,您需要在系统中安装 .NET 6.0 运行时,因为 IronPDF 依赖于 .NET 的操作。
IronPDF 可以与流行的 Python Web 框架一起使用吗?
是的,IronPDF 可以无缝集成于流行的 Python Web 框架,如 Django、Flask 和 Pyramid,使其成为 Web 开发项目的多功能工具。
如何在 Python 虚拟环境中安装 IronPDF?
要在 Python 虚拟环境中安装 IronPDF,首先确保您安装了 Python 并创建了虚拟环境。使用命令 pip install ironpdf 在您的 IDE 的终端中安装该包。
IronPDF 为 Python 开发者提供哪些关键功能?
IronPDF 提供的功能包括从 HTML、图片、字符串和流生成 PDF,创建交互式 PDF,填写表单,拆分和合并 PDF,以及提取文本和图片。
IronPDF 是否兼容不同的操作系统?
是的,IronPDF 与不同的操作系统兼容。然而,Linux 和 Mac 用户需确保他们的系统上安装了 .NET 才能使用 Python 模块。
IronPDF有哪些许可选项?
IronPDF 提供多个许可选项,包括带限制的免费开发者许可和带有永久许可证及三十天退款保证的付费 Lite 包。这些选项根据您的开发需求提供灵活性。
如何在 PyCharm 中建立新的 IronPDF 项目?
要在 PyCharm 中建立新的 IronPDF 项目,打开 IDE,点击“新建项目”,并配置项目的路径和环境。使用 PyCharm 中的终端用 pip install ironpdf 安装 IronPDF。
IronPDF 如何确保 PDF 文档的安全性?
IronPDF 结合了强大的安全措施,确保 PDF 文档的安全和完整性,使其成为需要处理 PDF 的应用程序的可靠选择。
IronPDF 能用于从 PDF 中提取图片吗?
可以,IronPDF 可以通过访问文档对象并使用适当的方法提取图片数据从 PDF 中提取图片。
















