
如何在 Python 中拆分 PDF 文件
在数字文档管理领域,高效地操作和组织 PDF 文件的能力对于许多开发人员和专业人士来说是一项至关重要的技能。 Python 是一种功能强大且用途广泛的编程语言,它提供了各种各样的库和工具来完成这项任务。 其中一项任务是分割大型 PDF 文件,这对于提取特定页面、创建较小的文档或自动化文档工作流程等任务至关重要。
在本文中,我们将探索一个 Python 库,该库使我们能够轻松地分割 PDF 文件,为任何希望在 PDF 处理工作中利用 Python 的潜力的人提供全面的指南。 无论您是经验丰富的开发人员还是 Python 新手,本文都将为您提供有效且高效地分割 PDF 文件所需的知识和工具。 本文将使用的 Python 库和示例是IronPDF for Python 。 它是操作 PDF 文件最简便且功能强大的软件之一。
如何在 Python 中分割 PDF 文件
- 安装用于分割 PDF 文件的 Python 库。
- 使用RenderHtmlAsPdf方法生成 PDF 文件。
- 使用 Python 中的Split方法分割生成的 PDF 文件。
- 使用SaveAs方法保存新生成的 PDF 文档。
- 使用 split 方法拆分现有的 PDF 文件。
1. IronPDF for Python
IronPDF 是一个尖端的库,它将 PDF 生成和操作的强大功能引入到 Python 编程领域。 在当今数字时代,创建和处理 PDF 文档是无数应用程序和工作流程中不可或缺的部分,从生成报告到管理发票和交付内容。 IronPDF 弥合了 Python 和 PDF 之间的差距,为开发人员提供了一个功能丰富且用途广泛的解决方案,可以无缝地以编程方式创建、编辑和操作 PDF 文件。
在本文中,我们将深入探讨 IronPDF 的功能,探索它如何简化 Python 中与 PDF 相关的任务,并为开发人员提供所需的工具,以便在他们的应用程序中充分利用 PDF 文档的潜力。 无论您是构建 Web 应用程序、生成报告还是自动化文档工作流程,IronPDF for Python 都是一个强大的助手,可以简化您的开发流程、节省时间并增强项目的功能。
2. 创建一个新的 Python 项目
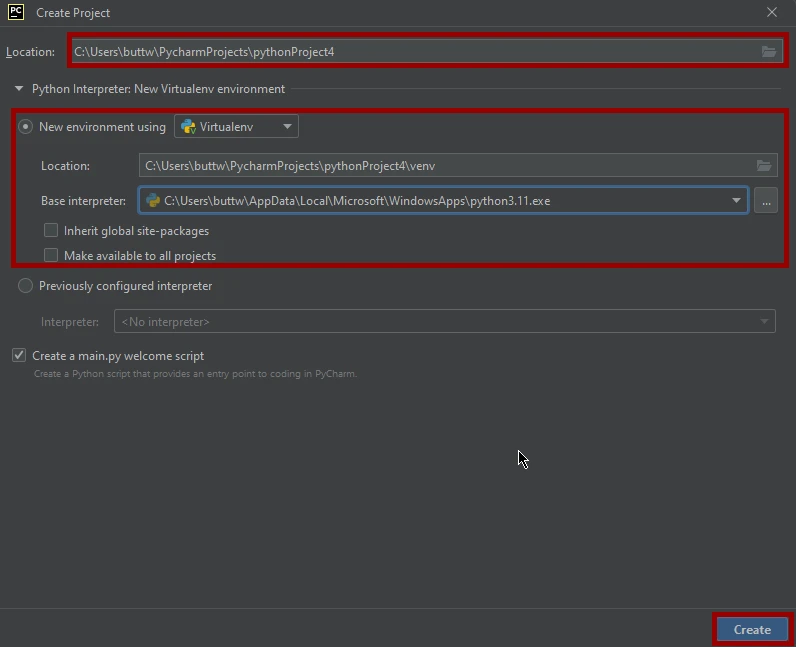
在PyCharm中创建一个新的 Python 项目是一个简单的过程,可以让你有效地组织 Python 脚本并管理依赖项。 以下是如何在 PyCharm 中创建新 Python 项目的分步指南:
1.打开 PyCharm:如果 PyCharm 尚未打开,请启动它。 你应该会看到 PyCharm 的欢迎界面。 2.创建新项目:点击顶部菜单中的"文件",然后选择"新建项目..."。 您还可以使用键盘快捷键"Ctrl + Shift + N"(Windows/Linux)或"Cmd + Shift + N"(macOS)打开"新建项目"对话框。
3. 安装适用于 Python 的 IronPDF
IronPDF for Python 的先决条件
IronPDF for Python依赖于 .NET 6.0 框架作为其底层技术。 因此,为了在Python中使用IronPDF,有必要在您的计算机上安装.NET 6.0 SDK。
安装
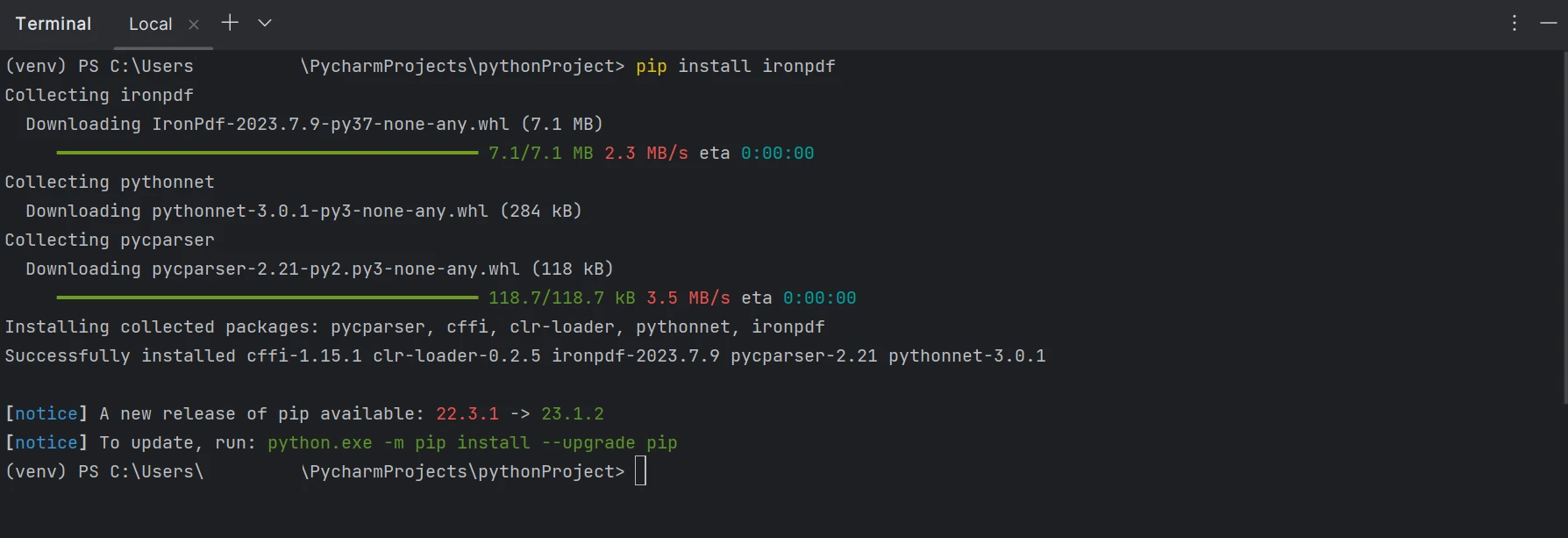
使用系统终端或 PyCharm 的内置命令行终端可以轻松安装IronPDF 。 只需运行以下命令,IronPDF 将在几秒钟内安装完成。
pip install ironpdf
ironpdf 包的安装在下面的截图中显示。
4. 使用 IronPDF for Python 分割 PDF 文档
在本文中,我们将深入探讨使用 IronPDF for Python 分割 PDF 的世界,探索其特性和功能,并演示它如何简化提取和管理 PDF 内容这一通常很复杂的任务,同时增强您使用 Python 进行的文档处理工作。
下面的代码片段将向您展示如何仅用几行代码轻松分割 PDF 文件。
from ironpdf import ChromePdfRenderer
# Define HTML content with page breaks
html = """<p> Hello Iron </p>
<p> This is the 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is the 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is the 3rd Page</p>"""
# Render the HTML into a PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# Copy and save the first page
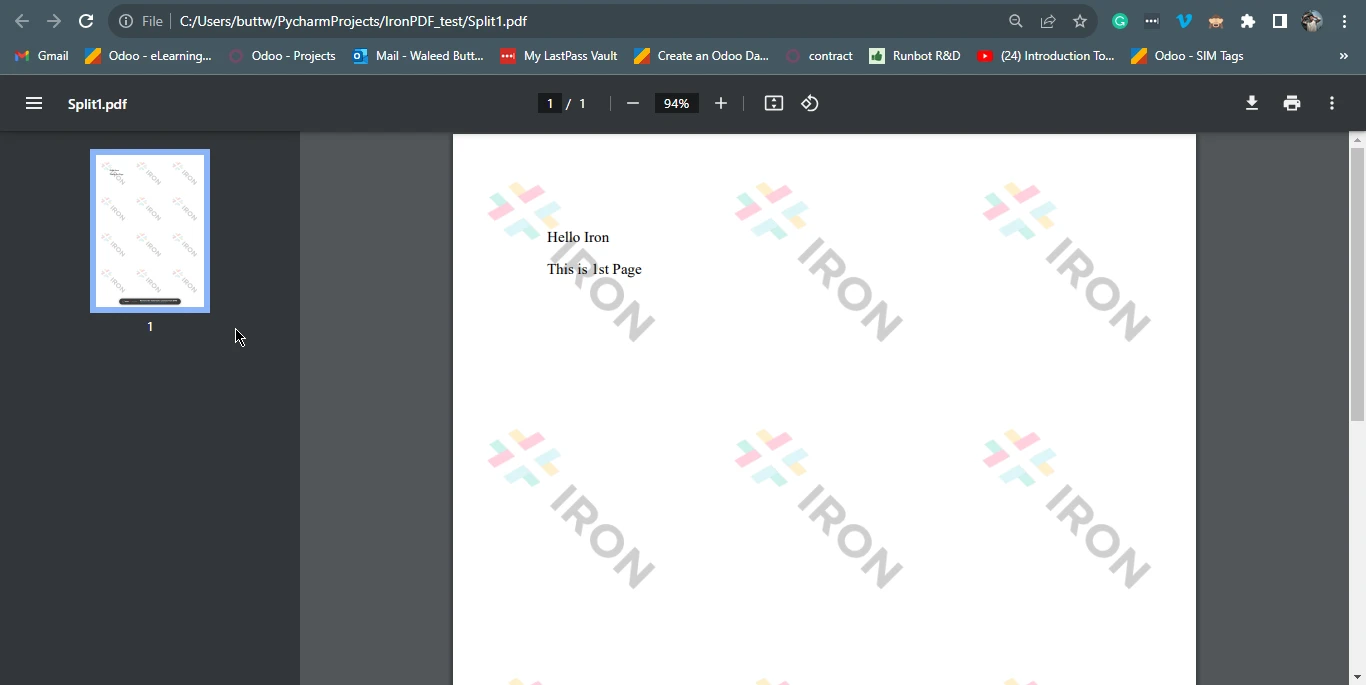
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# Copy and save the second and third pages as a single document
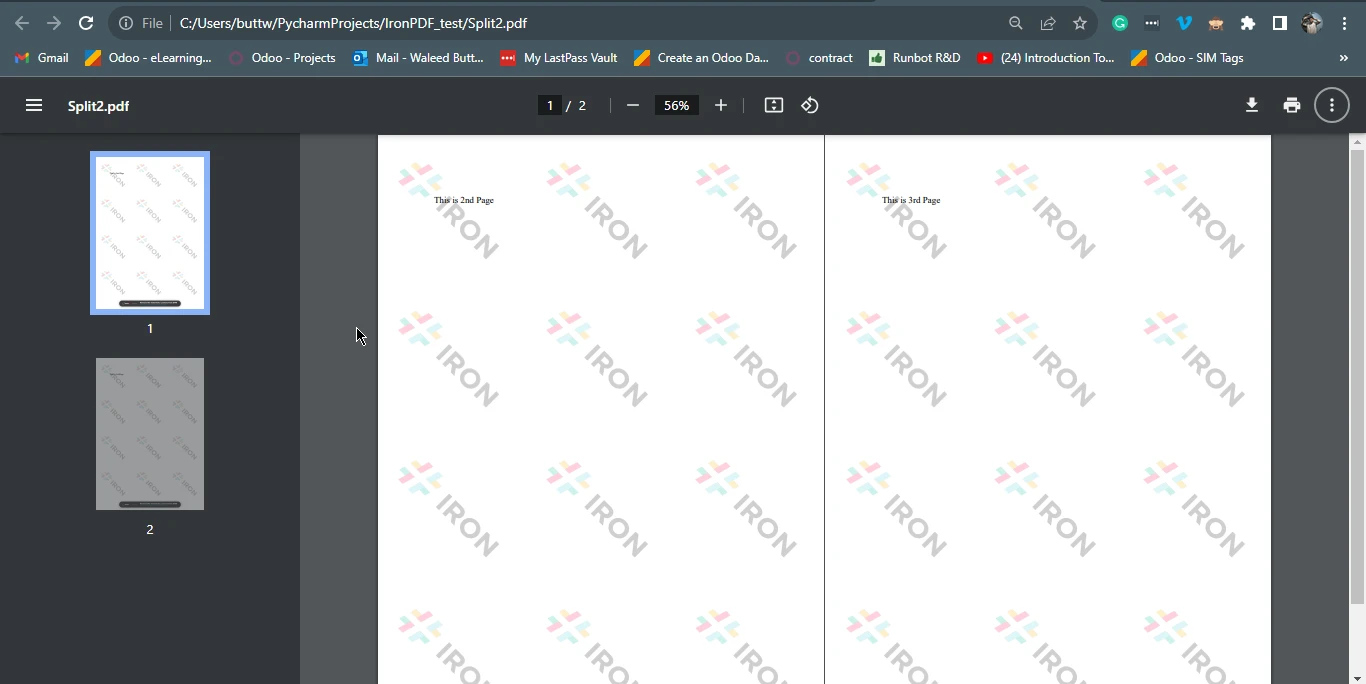
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")from ironpdf import ChromePdfRenderer
# Define HTML content with page breaks
html = """<p> Hello Iron </p>
<p> This is the 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is the 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is the 3rd Page</p>"""
# Render the HTML into a PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# Copy and save the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# Copy and save the second and third pages as a single document
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")这段 Python 脚本利用 IronPDF 将 HTML 文档拆分成多个 PDF 文件。 它首先定义一个包含多个段落的HTML内容字符串,其中通过 <div style='page-break-after: always;'></div> 元素指示分页符。 接下来,它使用IronPDF的 ChromePdfRenderer 来将HTML渲染为一个新的PDF文件。
然后,它根据原文件的页索引(从0开始),将第一页复制到一个名为"Split1.pdf"的独立文档中,使用函数 pdf.CopyPage(0)。 最后,它使用函数 pdf.CopyPages(1, 2) 创建另一个PDF,包含第二和第三页,并保存为名为"Split2.pdf"的新文件。 这段代码展示了 IronPDF 如何方便地将 PDF 内容提取并拆分成多个 PDF 文件,使其成为 Python 应用程序中处理 PDF 文档的宝贵工具。
4.1 输出 PDF 文件
您还可以将现有的 PDF 文件拆分成多个页面,并以新的 PDF 文档格式保存。 要将现有 PDF 文件拆分为多个 PDF 文件,请按照以下代码示例操作:
from ironpdf import PdfDocument
# Open the existing PDF document
pdf = PdfDocument("document.pdf")
# Copy and save the first page as a separate file
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# Copy additional pages and save them as a separate document
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")from ironpdf import PdfDocument
# Open the existing PDF document
pdf = PdfDocument("document.pdf")
# Copy and save the first page as a separate file
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# Copy additional pages and save them as a separate document
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")上述代码使用 PdfDocument 方法打开一个现有PDF,通过提供原始文件名,将其拆分为两个独立的PDF文件。
5. 结论
本文展示了 Python 的多功能性和强大的 IronPDF 库,为希望高效分割和操作 PDF 文件的新手和经验丰富的开发人员提供了全面的指南。 IronPDF 弥合了 Python 和 PDF 之间的差距,为各种应用程序和工作流程提供功能丰富的解决方案,从生成报告到自动化文档处理。
这篇文章不仅指导读者如何设置 Python 项目和安装 IronPDF,还提供了清晰的代码示例,用于分割 PDF 文件,无论是从 HTML 内容还是现有文件。 通过利用 IronPDF 的功能,开发人员可以增强文档处理任务,简化工作流程,并充分发挥 Python 应用程序中处理 PDF 文件和文档的潜力,使其成为文档管理和操作的宝贵工具。
有关使用 IronPDF 库将 HTML 转换为 PDF 的更多信息,请访问以下教程页面。 这里提供了分割 PDF 文件的代码示例。
IronPDF for Python提供免费试用许可证,供商业用途测试其全部功能。 之后,它还需要获得商业用途的许可。 如需了解更多信息,您可以访问 IronPDF 的许可页面。
常见问题解答
我可以如何使用 Python 拆分 PDF 文件?
您可以使用 IronPDF 在 Python 中拆分 PDF 文件,通过使用 CopyPage 和 CopyPages 方法,您可以提取 PDF 中的特定页面并将它们保存为单独的文档。
安装 IronPDF for Python 需要哪些步骤?
要安装 IronPDF for Python,使用命令 pip install ironpdf。确保您的计算机上安装了 .NET 6.0 SDK,因为这是使用 IronPDF 的先决条件。
IronPDF可以在Python中将HTML转换为PDF吗?
是的,IronPDF 可以在 Python 中使用 RenderHtmlAsPdf 方法将 HTML 转换为 PDF,无缝地将 HTML 网页内容转换为 PDF 格式。
拆分 PDF 文件有什么好处?
拆分 PDF 文件有助于提取特定页面、创建更小、更易于管理的文档,并自动化文档工作流程。这项能力对于高效的数字文档管理至关重要。
如何使用 IronPDF 自动化文档工作流程?
IronPDF 支持通过提供工具来编程地拆分、合并和操作 Python 应用程序中的 PDF 文档,从而简化流程并提高效率。
Python 中是否有 IronPDF 的试用版可用?
是的,IronPDF 提供商业用途的免费试用许可证,允许您在承诺购买商业许可证以继续使用之前测试其功能。
如何在 PyCharm 中创建一个新的 Python 项目以进行 PDF 操作?
要在 PyCharm 中创建一个新的 Python 项目,导航到 'File' > 'New Project',设置所需的项目位置和解释器,然后点击 'Create'。这样设置可以让您开始集成类似 IronPDF 的库。
为什么 PDF 操作对开发者很重要?
PDF 操作对于开发人员至关重要,因为它可以实现 PDF 文件的高效组织、提取和管理,支持数字文档管理中的各种工作流程和应用程序。
















