
如何在 Python 中查看 PDF 文件
本文将探讨如何使用 IronPDF 库在 Python 中查看 PDF 文件。
IronPDF - Python 库
IronPDF是一个功能强大的 Python 库,它使开发人员能够以编程方式处理 PDF 文件。 IronPDF 是一款功能强大的工具,可以轻松生成、处理和提取 PDF 文档中的数据,是处理各种 PDF 相关任务的理想选择。 无论您是需要从头开始创建 PDF、修改现有 PDF 还是从 PDF 中提取内容,IronPDF 都提供了一套全面的功能来简化您的工作流程。
IronPDF for Python 库的一些特性包括:
- 使用 HTML 或 URL 从头开始创建新的 PDF 文件
- 编辑现有 PDF 文件
- 旋转 PDF 页面
- 从 PDF 文件中提取文本、元数据和图像
- 将 PDF 文件转换为其他格式
- 使用密码和限制保护 PDF 文件 -拆分和合并PDF文件
注意: IronPDF 生成的 PDF 数据文件带有水印。要去除水印,您需要购买 IronPDF 的许可。 如果您想使用 IronPDF 的授权版本,请访问IronPDF 网站获取许可证密钥。
前提条件
在 Python 中使用 IronPDF 之前,需要满足一些先决条件:
- Python 安装:确保您的系统上已安装 Python。 IronPDF 与 Python 3.x 版本兼容,因此请确保您已安装兼容的 Python 版本。
IronPDF库:安装IronPDF库以使用其功能。 您可以使用 Python 包管理器 ( pip ) 安装它,只需在命令行界面中执行以下命令:
pip install ironpdfpip install ironpdfSHELLTkinter 库: Tkinter 是 Python 的标准 GUI 工具包。 它用于为提供的代码片段中的 PDF 查看器创建图形用户界面。 Tkinter 通常随 Python 预装,但如果遇到任何问题,您可以使用包管理器安装它:
pip install tkinterpip install tkinterSHELLPillow 库: Pillow 库是 Python Imaging Library (PIL) 的一个分支,提供了额外的图像处理功能。 这段代码片段用于加载和显示从 PDF 中提取的图像。 使用软件包管理器安装 Pillow:
pip install pillowpip install pillowSHELL
5.集成开发环境 (IDE):使用 IDE 处理 Python 项目可以极大地提升您的开发体验。 它提供了代码补全、调试和更简化的工作流程等功能。 PyCharm 是 Python 开发中一款流行的 IDE。 您可以从 JetBrains 网站 ( https://www.jetbrains.com/pycharm/ ) 下载并安装 PyCharm。 6.文本编辑器:或者,如果您更喜欢使用轻量级的文本编辑器,您可以选择任何文本编辑器,例如 Visual Studio Code、Sublime Text 或 Atom。 这些编辑器为 Python 开发提供了语法高亮和其他实用功能。 您也可以使用 Python 自带的 IDE 应用程序来创建 Python 脚本。
使用 PyCharm 创建 PDF 查看器项目
安装 PyCharm IDE 后,按照以下步骤创建一个 PyCharm Python 项目:
1.启动 PyCharm:从系统应用程序启动器或桌面快捷方式打开 PyCharm。 2.创建新项目:点击"创建新项目"或打开一个现有的 Python 项目。
PyCharm IDE
3.配置项目设置:为您的项目提供一个名称,并选择创建项目目录的位置。 为您的项目选择 Python 解释器。 然后点击"创建"。
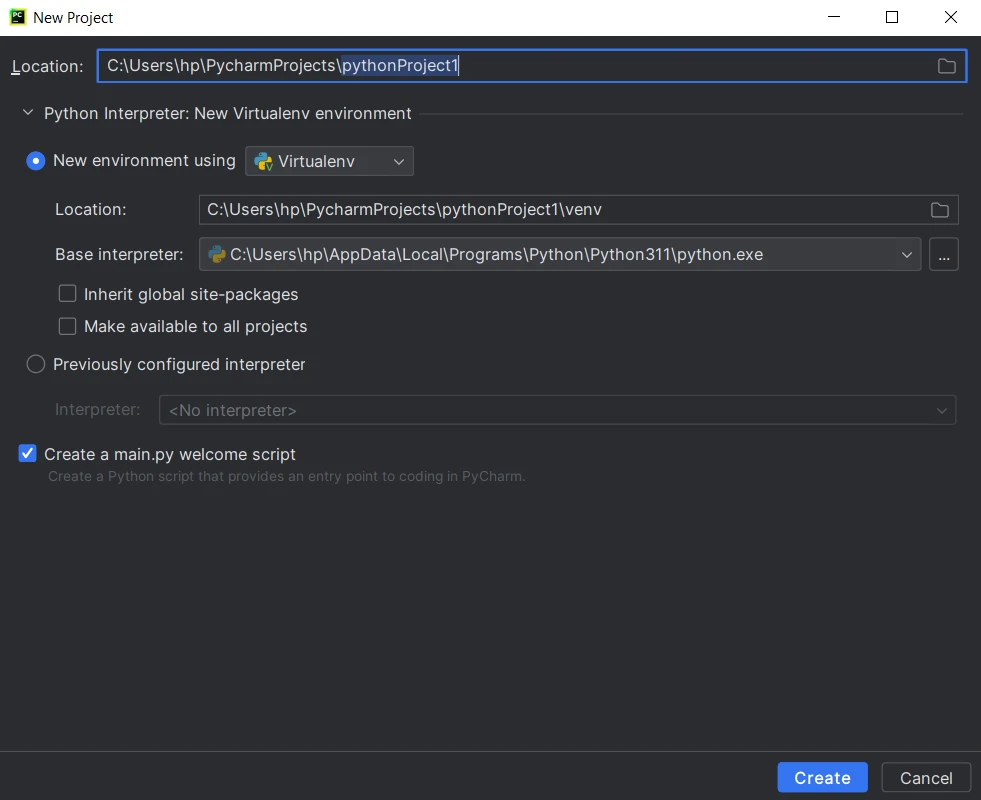
**创建一个新的 Python 项目**4.创建源文件: PyCharm 将创建项目结构,包括一个主 Python 文件和一个用于存放其他源文件的目录。 开始编写代码,然后单击运行按钮或按 Shift+F10 执行脚本。
使用 IronPDF 在 Python 中查看 PDF 文件的步骤
导入所需的库
首先,导入必要的库。 在这种情况下,需要使用PIL库。 tkinter用于创建图形用户界面(GUI),PIL用于图像处理。
import os
import shutil
import ironpdf
from tkinter import *
from PIL import Image, ImageTkimport os
import shutil
import ironpdf
from tkinter import *
from PIL import Image, ImageTk将 PDF 文档转换为图像
接下来,定义一个名为convert_pdf_to_images的函数。 该函数以 PDF 文件的路径作为输入。 函数内部使用 IronPDF 库从文件中加载 PDF 文档。然后,指定一个文件夹路径来存储提取的图像文件。 IronPDF的pdf.RasterizeToImageFiles方法用于将每个PDF页面转换为图像文件并保存到指定的文件夹中。 使用列表来存储图像路径。 完整的代码示例如下:
def convert_pdf_to_images(pdf_file):
"""Convert each page of a PDF file to an image."""
pdf = ironpdf.PdfDocument.FromFile(pdf_file)
# Extract all pages to a folder as image files
folder_path = "images"
pdf.RasterizeToImageFiles(os.path.join(folder_path, "*.png"))
# List to store the image paths
image_paths = []
# Get the list of image files in the folder
for filename in os.listdir(folder_path):
if filename.lower().endswith((".png", ".jpg", ".jpeg", ".gif")):
image_paths.append(os.path.join(folder_path, filename))
return image_pathsdef convert_pdf_to_images(pdf_file):
"""Convert each page of a PDF file to an image."""
pdf = ironpdf.PdfDocument.FromFile(pdf_file)
# Extract all pages to a folder as image files
folder_path = "images"
pdf.RasterizeToImageFiles(os.path.join(folder_path, "*.png"))
# List to store the image paths
image_paths = []
# Get the list of image files in the folder
for filename in os.listdir(folder_path):
if filename.lower().endswith((".png", ".jpg", ".jpeg", ".gif")):
image_paths.append(os.path.join(folder_path, filename))
return image_paths要从 PDF 文档中提取文本,请访问此 代码示例页面。
把手窗户关闭
要在应用程序窗口关闭时清理提取的图像文件,请定义一个on_closing函数。 在此函数内,使用images文件夹。 接下来,将此函数设置为窗口关闭时要执行的协议。 以下代码有助于实现该任务:
def on_closing():
"""Handle the window closing event by cleaning up the images."""
# Delete the images in the 'images' folder
shutil.rmtree("images")
window.destroy()
window.protocol("WM_DELETE_WINDOW", on_closing)def on_closing():
"""Handle the window closing event by cleaning up the images."""
# Delete the images in the 'images' folder
shutil.rmtree("images")
window.destroy()
window.protocol("WM_DELETE_WINDOW", on_closing)创建图形用户界面窗口
现在,让我们使用on_closing()函数设为窗口关闭的处理协议。
window = Tk()
window.title("Image Viewer")
window.protocol("WM_DELETE_WINDOW", on_closing)window = Tk()
window.title("Image Viewer")
window.protocol("WM_DELETE_WINDOW", on_closing)创建可滚动画布
要显示图像并启用滚动,创建一个Canvas小部件。 pack(side=LEFT, fill=BOTH, expand=True)在两个方向上扩展。 另外,创建一个Scrollbar小部件,并将其配置为控制所有页面和画布的垂直滚动。
canvas = Canvas(window)
canvas.pack(side=LEFT, fill=BOTH, expand=True)
scrollbar = Scrollbar(window, command=canvas.yview)
scrollbar.pack(side=RIGHT, fill=Y)
canvas.configure(yscrollcommand=scrollbar.set)
# Update the scrollregion to encompass the entire canvas
canvas.bind("<Configure>", lambda e: canvas.configure(
scrollregion=canvas.bbox("all")))
# Configure the vertical scrolling using mouse wheel
canvas.bind_all("<MouseWheel>", lambda e: canvas.yview_scroll(
int(-1*(e.delta/120)), "units"))canvas = Canvas(window)
canvas.pack(side=LEFT, fill=BOTH, expand=True)
scrollbar = Scrollbar(window, command=canvas.yview)
scrollbar.pack(side=RIGHT, fill=Y)
canvas.configure(yscrollcommand=scrollbar.set)
# Update the scrollregion to encompass the entire canvas
canvas.bind("<Configure>", lambda e: canvas.configure(
scrollregion=canvas.bbox("all")))
# Configure the vertical scrolling using mouse wheel
canvas.bind_all("<MouseWheel>", lambda e: canvas.yview_scroll(
int(-1*(e.delta/120)), "units"))创建图像框架
接下来,在画布内创建一个create_window()将框架放置在画布内。 anchor='nw'参数确保框架从画布的左上角开始。
frame = Frame(canvas)
canvas.create_window((0, 0), window=frame, anchor="nw")frame = Frame(canvas)
canvas.create_window((0, 0), window=frame, anchor="nw")将 PDF 文件转换为图像并显示
下一步是调用convert_pdf_to_images()函数,并传入输入PDF文件的文件路径名。此函数将PDF页面提取为图像并返回图像路径列表。 通过遍历图像路径并使用PIL库的PhotoImage对象。 然后创建一个Label小部件来显示图像。
images = convert_pdf_to_images("input.pdf")
# Load and display the images in the Frame
for image_path in images:
image = Image.open(image_path)
photo = ImageTk.PhotoImage(image)
label = Label(frame, image=photo)
label.image = photo # Store a reference to prevent garbage collection
label.pack(pady=10)images = convert_pdf_to_images("input.pdf")
# Load and display the images in the Frame
for image_path in images:
image = Image.open(image_path)
photo = ImageTk.PhotoImage(image)
label = Label(frame, image=photo)
label.image = photo # Store a reference to prevent garbage collection
label.pack(pady=10)输入文件
运行 GUI 主循环
最后,让我们使用window.mainloop()运行主事件循环。 这样可以确保图形用户界面窗口保持打开和响应状态,直到用户将其关闭。
window.mainloop()window.mainloop()用户界面输出
结论
本教程探讨了如何使用IronPDF库在 Python 中查看 PDF 文档。 它涵盖了打开 PDF 文件并将其转换为一系列图像文件所需的步骤,然后在可滚动画布中显示这些图像,以及在应用程序关闭时处理提取图像的清理工作。
有关 IronPDF for Python 库的更多详细信息,请参阅文档。
下载并安装IronPDF for Python库,还可以获得免费试用版,以测试其在商业开发中的完整功能。
常见问题解答
如何在 Python 中查看 PDF 文件?
您可以使用 IronPDF 库在 Python 中查看 PDF 文件。 它允许您将 PDF 页转换为图像,然后可以使用 Tkinter 在 GUI 应用程序中显示这些图像。
在 Python 中创建 PDF 查看器的必要步骤是什么?
要在 Python 中创建 PDF 查看器,您需要安装 IronPDF,使用 Tkinter 进行 GUI 创建,并使用 Pillow 进行图像处理。 使用 IronPDF 将 PDF 页转换为图像,并在使用 Tkinter 创建的可滚动画布中显示它们。
如何为 Python 项目安装 IronPDF?
您可以通过在终端或命令提示符中运行命令 pip install ironpdf 来安装 IronPDF。
构建 Python 中的 PDF 查看应用程序需要哪些库?
您将需要 IronPDF 进行 PDF 处理,Tkinter 用于 GUI,Pillow 用于图像处理。
我可以使用 Python 从 PDF 中提取图像吗?
是的,IronPDF 允许您从 PDF 中提取图像,然后可以使用 Pillow 库进行处理或显示。
如何在 Python 中将 PDF 页转换为图像?
您可以使用 IronPDF 的功能将 PDF 页转换为图像格式,然后可以在 Python 应用程序中操作或显示。
如何处理 Python PDF 查看应用程序中的窗口关闭?
在 PDF 查看应用程序中,您可以通过清理提取的图像和确保所有资源正确释放来处理窗口关闭,通常使用 Tkinter 的事件处理函数。
如何在 Python 中保护 PDF 文件?
IronPDF 提供了通过向 PDF 文件添加密码和使用限制来增强 PDF 安全性的选项。
在 PDF 查看应用程序中使用 Tkinter 的优势是什么?
Tkinter 允许您为 PDF 查看器创建用户友好的图形界面,启用可滚动视图以浏览 PDF 页。
在 PDF 项目中使用 Pillow 的目的是什么?
Pillow 用于 PDF 项目中的图像处理,例如加载和显示从 PDF 文件中提取的图像(使用 IronPDF)。
















