IronPDF vs ChatGPT - Extracting Text from PDF Documents
What is ChatGPT?
ChatGPT is a large language model-based chatbot released by OpenAI in 2022. It’s notable for enabling users to create and shape a dialogue into a desired structure, style, level of detail, and language spoken. Every discussion point takes into account a context that considers prior prompts and responses, or 'prompt engineering', using the OpenAI API key.
The foundation of ChatGPT is made up of transformer models which are part of OpenAI's exclusive generative pre-trained transformer series. These models are then optimized for conversational applications by combining supervised and reinforcement learning methods. Originally published as a free research preview, ChatGPT AI language model is now offered on a freemium basis by OpenAI due to its popularity. The more sophisticated GPT-4-based version and priority access to updated features are made available to paid customers under the brand name 'ChatGPT Plus,' while users can access its free tier using GPT-3.5.
Can ChatGPT Read PDF Files?
Well, yes and no. With the paid-for version, asking ChatGPT to extract text from a PDF document is as simple as uploading the file to the chatbox and asking it to extract text from or summarize the PDF contents.
However, it’s not without its drawbacks. ChatGPT will give you the information in plain text, meaning that it’s a manual process to create a new PDF document using that information. It’s possible to ask ChatGPT to create a new PDF file from the extracted text, but it’s prone to formatting issues and malfunctioning download links. Also, customization is limited with ChatGPT, frequently having issues with requests to add headers and footers to your documents, as an example.
As of writing, the free tier of ChatGPT doesn’t support file attachments, meaning it’s impossible to ask it to read PDFs.
What is IronPDF?
IronPDF was developed to make it easy to create, browse, and edit PDF files in .NET frameworks. It includes a robust API for producing, editing, and altering PDF files, in addition to serving as a powerful PDF converter. Xamarin, Blazor, Unity, HoloLens applications, Windows Forms, HTML, ASPX, Razor, .NET Core, ASP, and WPF are just some of the extensions that are compatible with IronPDF.
IronPDF makes use of the Chrome engine to convert HTML to PDF. It supports both conventional Windows programs and online ASP.NET apps using Microsoft.NET and .NET Core. It allows you to customize your PDFs with a variety of functions, supporting HTML5, JavaScript, CSS, and images.
By using the IronPDF library, developers may read and edit PDF files without using Acrobat Reader. Additionally, they can add text and graphics, bookmarks, watermarks, headers, and footers as well as split and transfer text properties, merge pages, and extract images from new or existing PDF documents.
Additionally, PDF documents can be produced using CSS and CSS media files. IronPDF allows you to generate, upload, and edit both new office documents such as Microsoft Word and outdated PDF forms.
Extract Text from a PDF using IronPDF
IronPDF allows you to extract text from a PDF and convert it into a variety of formats. It can handle single or multiple PDF documents, as well as allowing you to extract text from an entire document or selected pages - giving you full control over your PDF content. Here’s how to get started:
Create Your Project in Visual Studio
First of all, open Visual Studio and go to File -> New Project -> Console Application. Enter your project name, choose the location you want to save it to, and hit the Next button. Select the latest .NET Framework and then Create. Once your project is up and running, it’s time to add our library.
Install the IronPDF Library
IronPDF is easy to use but it’s even easier to install. There are a couple of ways you can do it:
Method 1: NuGet Package Manager Console
In Visual Studio, in Solution Explorer, right-click References, and then click Manage NuGet Packages. Hit browse and search ‘IronPDF,’ and install the latest version. If you see this, it’s working:
You can also go to Tools -> NuGet Package Manager -> Packet Manager Console, and enter the following line in the Package Manager Tab:
Install-Package IronPdf
Finally, you can get IronPDF directly from NuGet’s official website with IronPDF download instructions. Select the Download Package option from the menu on the right of the page, double-click your download to install it automatically, and reload the Solution to start using it in your project.
Didn’t work? You can find platform-specific help on our advanced NuGet installation methods.
Method 2: Using a DLL file
You can also get the IronPDF DLL file straight from us and add it to Visual Studio manually. For full instructions and links to the Windows, MacOS, and Linux DLL packages, check out our dedicated IronPDF installation guide.
Add the IronPDF Namespace
Always remember to kick off your code with the IronPDF namespace, like this:
using IronPdf;using IronPdf;Imports IronPdfExtract Text from Entire PDF Document
Extracting text from PDF documents is as simple as two lines of code. In this code example, we convert PDF content into a text-based format:
// Load the PDF document from a file into a PdfDocument object
var pdfDocument = IronPdf.PdfDocument.FromFile("Demo.pdf");
// Extract all text from the entire PDF and store it in a string
string AllText = pdfDocument.ExtractAllText();// Load the PDF document from a file into a PdfDocument object
var pdfDocument = IronPdf.PdfDocument.FromFile("Demo.pdf");
// Extract all text from the entire PDF and store it in a string
string AllText = pdfDocument.ExtractAllText();' Load the PDF document from a file into a PdfDocument object
Dim pdfDocument = IronPdf.PdfDocument.FromFile("Demo.pdf")
' Extract all text from the entire PDF and store it in a string
Dim AllText As String = pdfDocument.ExtractAllText()Let’s go through it - the FromFile() function loads the PDF file from your computer and turns it into a PdfDocument object. From there, the ExtractAllText() function of the PdfDocument class object retrieves all the text from the whole PDF file and stores it in a processable string.
Below, you can see the PDF and the text output in the console:
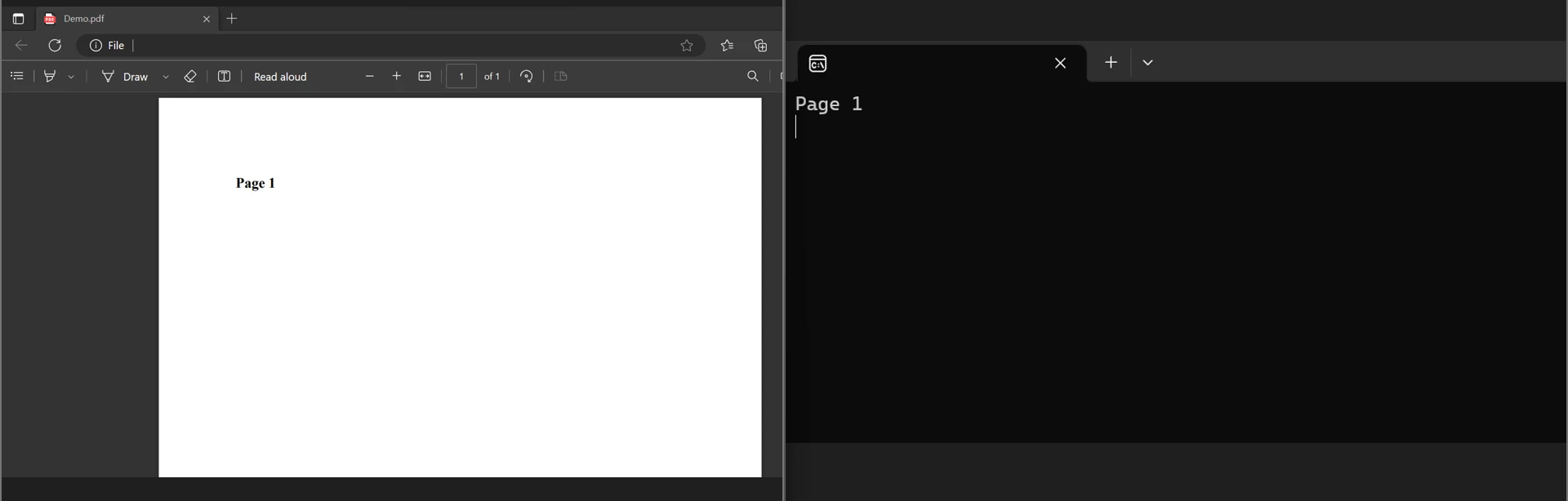
Extract Text from Individual Pages in a PDF Document
using IronPdf;
// Load the PDF document from a file
PdfDocument PDF = PdfDocument.FromFile("result.pdf");
// Loop through each page of the PDF document
for (var index = 0; index < PDF.PageCount; index++)
{
// Page numbers are typically 1-based, so we add 1 to the index
int PageNumber = index + 1;
// Extract text from the current page
string Text = PDF.ExtractTextFromPage(index);
}using IronPdf;
// Load the PDF document from a file
PdfDocument PDF = PdfDocument.FromFile("result.pdf");
// Loop through each page of the PDF document
for (var index = 0; index < PDF.PageCount; index++)
{
// Page numbers are typically 1-based, so we add 1 to the index
int PageNumber = index + 1;
// Extract text from the current page
string Text = PDF.ExtractTextFromPage(index);
}Imports IronPdf
' Load the PDF document from a file
Private PDF As PdfDocument = PdfDocument.FromFile("result.pdf")
' Loop through each page of the PDF document
For index = 0 To PDF.PageCount - 1
' Page numbers are typically 1-based, so we add 1 to the index
Dim PageNumber As Integer = index + 1
' Extract text from the current page
Dim Text As String = PDF.ExtractTextFromPage(index)
Next indexSimilar to the previous code, here the entire PDF file is loaded before being converted into a PDF object. PageCount returns the total number of pages in the file, the ExtractTextFromPage() method extracts the text, while the for loop handles the page variety as a parameter. From there, our text is stored in the string variable. In order to extract information from the PDF page-by-page, we utilize the for loop.
For more information on how to extract embedded text and images from PDFs, check out this detailed guide on text and image extraction from PDFs.
IronPDF vs ChatGPT - Which is Better?
There are many available tools that allow you to extract content from a PDF, including ChatGPT. However, IronPDF is built with customization and developer control in mind, making it an industry-leading PDF reader. And PDF reading is just the start - with HTML to PDF conversion, PDF formatting tools, built-in security and compliance features, and more, IronPDF is the number one tool for all of your PDF document needs.
IronPDF also boasts wide-ranging compatibility. Built for the .NET ecosystem, it supports .NET Framework, .NET Standard, and .NET Core 3.1 through 8, and is constantly updated to stay on the cutting edge.
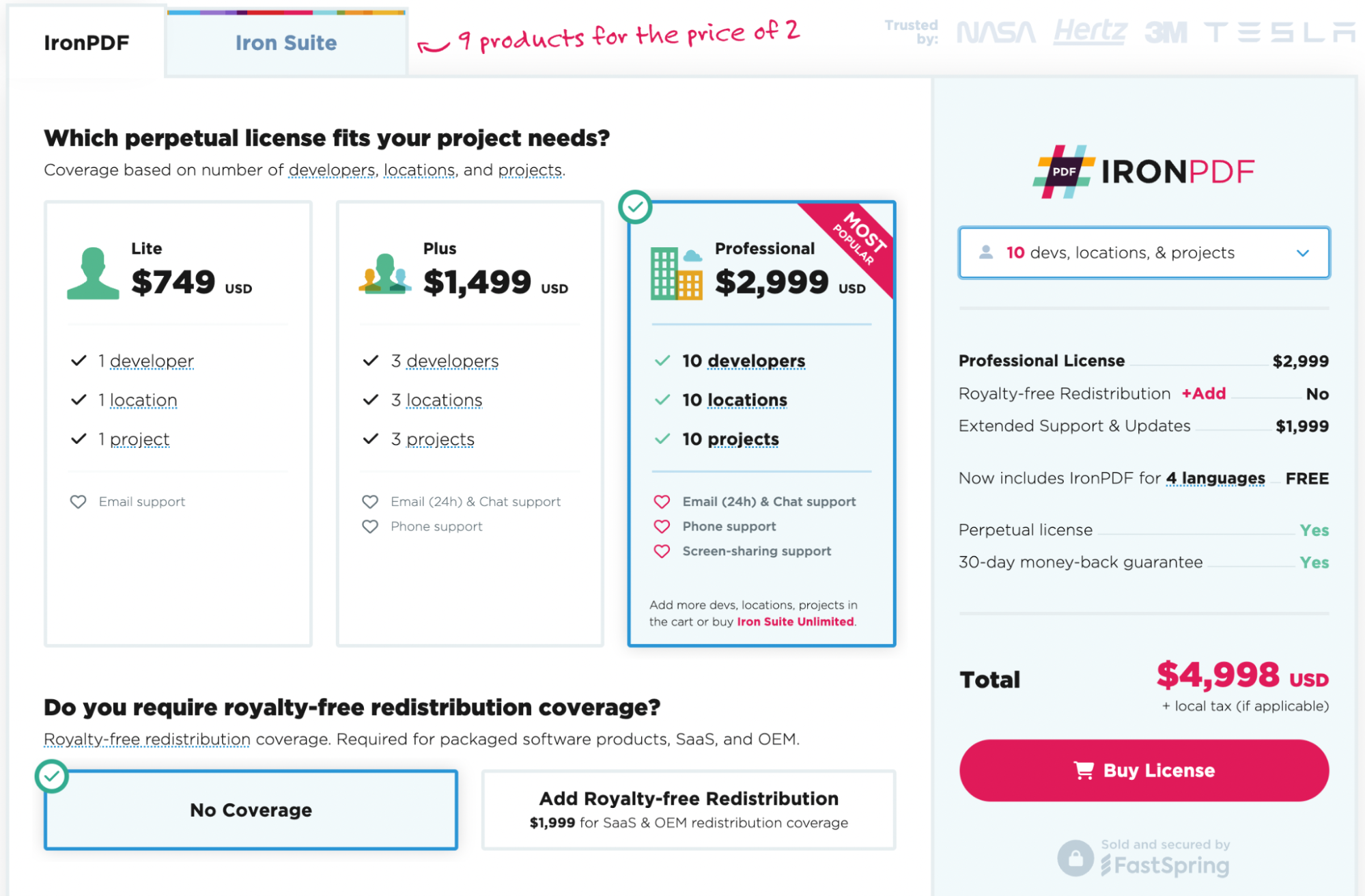
Ready to get your hands on IronPDF? You can start with our 30-day free trial and explore IronPDF features. It’s also completely free to use for development purposes so you can really get to see what it’s made of. And if you like what you see, IronPDF starts as low as $999 for full access to IronPDF tools. For even bigger savings, check out the Iron Suite package offering 9 tools for the price of two. Happy coding!