
Html Agility Pack C# (Cómo Funciona para Desarrolladores)
La necesidad de gestionar y manipular contenido de documentos de forma dinámica está muy extendida en el mundo del desarrollo de C#. Los desarrolladores suelen confiar en bibliotecas robustas para automatizar actividades como la creación de informes PDF y la extracción de datos de páginas web. Este artículo explora la integración sencilla de IronPDF y HTML Agility Pack en C# y proporciona ejemplos de código para demostrar cómo se pueden usar estas bibliotecas para crear documentos PDF sin esfuerzo y leer texto HTML.
IronPDF es una biblioteca .NET rica en funciones para trabajar con archivos PDF. Como IronPDF permite a los desarrolladores generar archivos PDF dinámicamente a partir de contenido HTML, URL o datos sin procesar, sirve como una herramienta valiosa para la creación de documentos, informes y visualización de datos.
Para agilizar la generación de documentos en aplicaciones .NET, veremos cómo conectar IronPDF con HTML Agility Pack en este post. Al combinar estas tecnologías, los programadores pueden trabajar con sistemas remotos, generar páginas PDF dinámicas y obtener datos mediante conectividad de red, todo mientras aumentan la productividad y escalabilidad en sus programas.
Cómo usar HtmlAgilityPack en C
- Crea un nuevo Proyecto de C#.
- Instalar la biblioteca HtmlAgilityPack.
- Importar el espacio de nombres. Crear un objeto.
- Importar datos desde URL y analizar el HTML.
- Obtener los datos requeridos y deshacerse del objeto.
Introducción a HtmlAgilityPack
HTML Agility Pack es una biblioteca de análisis HTML versátil y potente para desarrolladores .NET. Con la ayuda de su extensa colección de API, los desarrolladores pueden navegar, alterar y extraer fácilmente datos de documentos HTML. HTML Agility Pack hace más fácil trabajar con contenido HTML de manera programática para todos los desarrolladores, independientemente del nivel de experiencia.
La capacidad de HTML Agility Pack para gestionar con delicadeza HTML que está mal organizado o es defectuoso es lo que lo hace único. Es perfecto para operaciones de scraping en línea donde la calidad del marcado HTML puede variar, ya que utiliza un algoritmo de análisis permisivo que puede analizar incluso el HTML peor construido.
Características de HtmlAgilityPack
Interpretación HTML
Con las potentes características de análisis HTML que ofrece HTML Agility Pack, los desarrolladores pueden cargar documentos HTML desde una variedad de fuentes, incluidos archivos, URL y cadenas. Debido a su enfoque de análisis permisivo, puede manejar con elegancia HTML mal formateado o incorrecto, lo que lo hace adecuado para actividades de scraping web donde la calidad del marcado HTML puede variar.
Manipulación DOM
Para explorar, navegar y trabajar con la estructura del Modelo de Objeto de Documento (DOM) HTML, HAP ofrece una API fácil de usar. Elementos HTML, atributos y nodos de texto se pueden agregar, eliminar o modificar programáticamente por los desarrolladores, permitiendo la manipulación dinámica de contenido HTML.
Soporte XPath y LINQ
Para elegir y consultar componentes HTML, HTML Agility Pack admite la sintaxis de búsqueda XPath así como LINQ (consulta integrada en lenguaje). Para elegir elementos en un documento HTML según sus atributos, etiquetas o jerarquía, las consultas de expresiones XPath proporcionan una sintaxis sólida y fácil de entender. Para los desarrolladores acostumbrados a trabajar con LINQ en C#, las consultas LINQ ofrecen una sintaxis de consulta familiar que facilita la integración fluida con otros componentes .NET.
Cómo empezar con HtmlAgilityPack
Configuración de HtmlAgilityPack en proyectos de C
La Biblioteca Base de HtmlAgility viene en un solo paquete empaquetado, que debería estar disponible en NuGet instalándolo y puede usarse en el proyecto C#. Ofrece un analizador HTML y selectores CSS desde el documento HTML y las URL HTML.
Implementación de HtmlAgilityPack en la consola y formularios de Windows
Muchos tipos de aplicaciones C#, como Formularios de Windows (WinForms) y Consola de Windows, implementan HtmlAgilityPack. Aunque la implementación varía de un marco a otro, la idea fundamental permanece constante.
HtmlAgilityPack C# Ejemplo
Uno de las herramientas más importantes en la caja de herramientas del desarrollador de C# para navegar, procesar y trabajar con documentos HTML es HTML Agility Pack (HAP). La extracción de datos de las páginas HTML se facilita con su API fácil de usar, que funciona como un árbol organizado de elementos. Examinemos un ejemplo de código sencillo para demostrar cómo usarlo.
using HtmlAgilityPack;
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
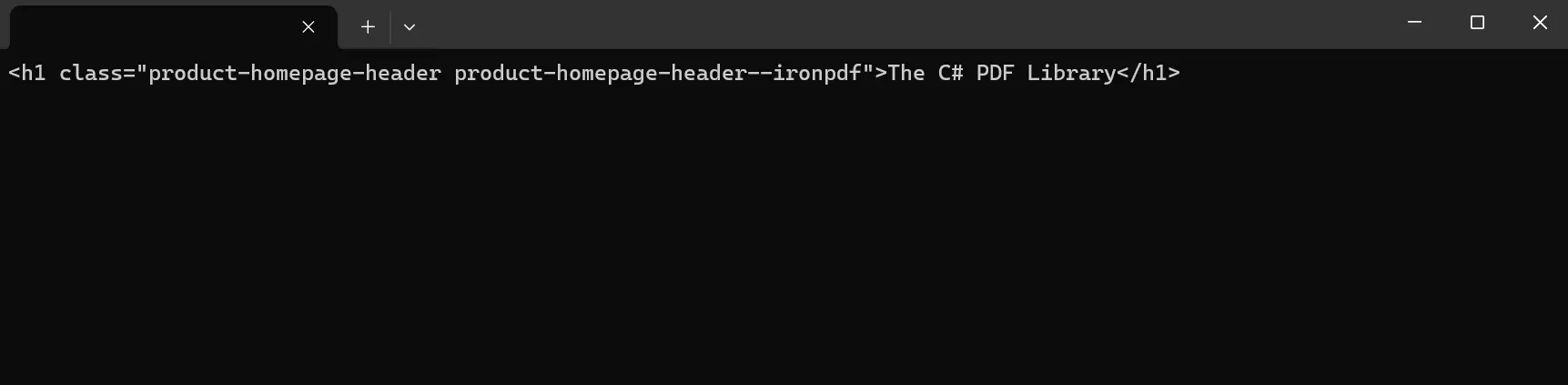
var doc = web.Load("https://ironpdf.com/");
// Select specific html nodes and parse html string
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
Console.WriteLine(node.InnerText);
}
Console.ReadKey();using HtmlAgilityPack;
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
var doc = web.Load("https://ironpdf.com/");
// Select specific html nodes and parse html string
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
Console.WriteLine(node.InnerText);
}
Console.ReadKey();Imports HtmlAgilityPack
' Load HTML content from a file or URL
Private web As New HtmlWeb()
Private doc = web.Load("https://ironpdf.com/")
' Select specific html nodes and parse html string
Private nodes As HtmlNodeCollection = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']")
' Iterate through selected nodes and extract content
For Each node As HtmlNode In nodes
Console.WriteLine(node.InnerText)
Next node
Console.ReadKey()En este ejemplo, cargamos material de nodo HTML desde una URL usando HTML Agility Pack. Luego, el HTML se carga en var doc para su análisis y manipulación. Para extraer contenido, el programa primero identifica el nodo raíz del documento HTML y luego apunta específicamente a nodos dentro del documento utilizando consultas XPath. Del código anterior, seleccionamos específicamente elementos div con la clase product-homepage-header desde los datos HTML en cadena, y luego se imprime el texto interno de cada nodo seleccionado en la consola.
Operaciones de HtmlAgilityPack
Transformación HTML
Los desarrolladores pueden realizar varias transformaciones y manipulaciones en textos HTML usando el HTML Agility Pack. Esto cubre operaciones como agregar, eliminar o cambiar nodos de texto, elementos y atributos además de reorganizar la jerarquía del DOM del documento HTML.
Extensibilidad
Debido a que HAP está destinado a ser ampliable, los programadores pueden agregar nuevas funciones y comportamientos para aumentar su funcionalidad. Usando la API proporcionada, los desarrolladores pueden diseñar sus propios analizadores, filtros o manipuladores HTML para personalizar HAP a sus necesidades y casos de uso únicos.
Rendimiento y eficacia
Grandes textos HTML pueden ser manejados bien por los algoritmos y estructuras de datos de HTML Agility Pack, que está afinado para la velocidad y eficacia. Garantiza un análisis y manipulación de contenido HTML rápido y receptivo al reducir el uso de memoria y la sobrecarga de procesamiento.
Integración de HtmlAgilityPack con IronPdf
Uso de IronPDF con HtmlAgilityPack
Las posibilidades para la gestión de documentos y la creación de informes son infinitas cuando se combinan HTML Agility Pack e IronPDF. A través del uso de HTML Agility Pack para el análisis HTML y la documentación de IronPDF para la conversión a PDF, los desarrolladores pueden automatizar con facilidad la creación de documentos PDF a partir de contenido dinámico en línea.
Instalar IronPDF
- Lanzar el proyecto de Visual Studio.
- Seleccione "Herramientas" > "Administrador de Paquetes NuGet" > "Consola de Paquetes".
- Introduce este comando en la Consola del Administrador de Paquetes:
Install-Package IronPdf
- Como alternativa, puedes usar el Administrador de Paquetes NuGet para Soluciones para instalar IronPDF.
-
Se pueden navegar los resultados de búsqueda del paquete IronPDF, seleccionar y luego hacer clic en el botón "Instalar". Visual Studio se encargará de la instalación y descarga por ti.
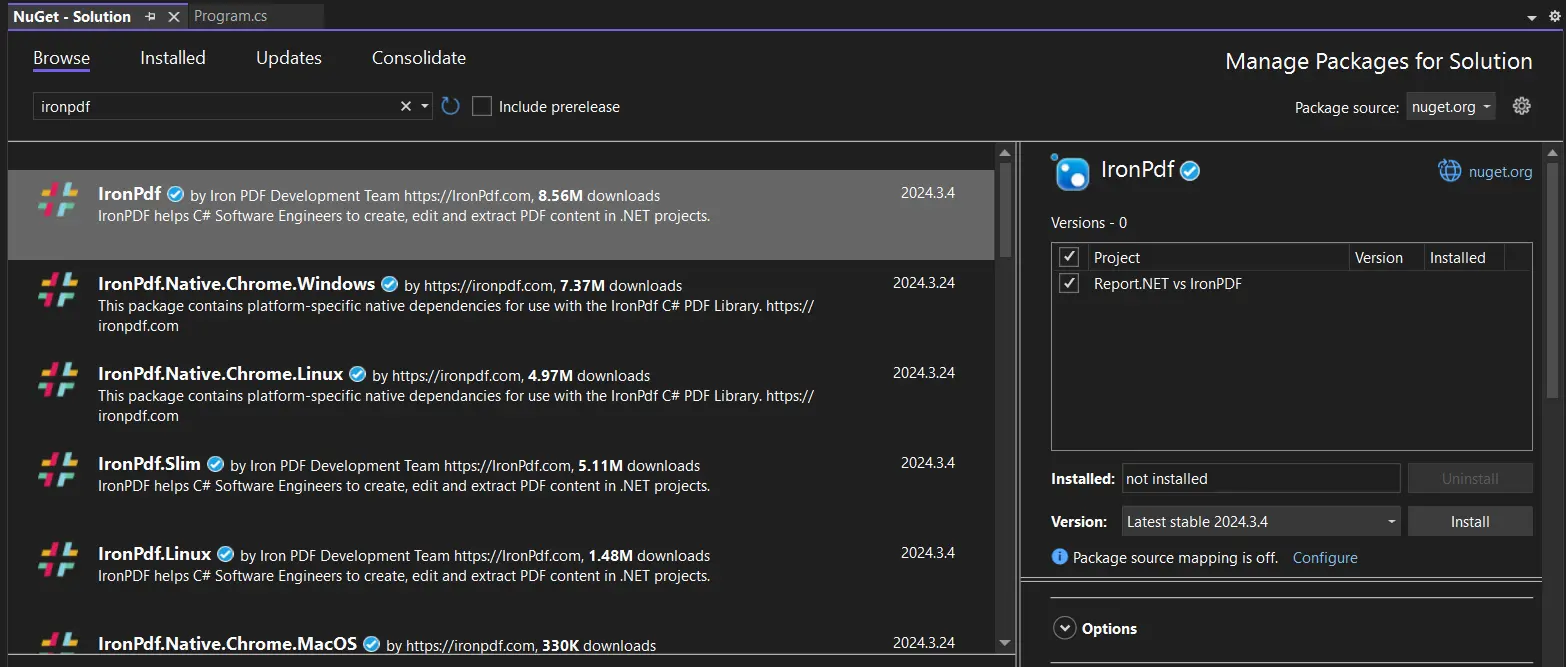
- El paquete IronPDF y cualquier dependencia necesaria para tu proyecto se instalarán por NuGet.
- IronPDF se puede usar para tu proyecto después de la instalación.
Instalación a través del sitio web de NuGet
Para saber más sobre las características, compatibilidad y otras opciones de descarga de IronPDF, consulta su Información del Paquete NuGet de IronPDF en el sitio web de NuGet.
Utilizar DLL para instalar
Como alternativa, puedes usar el archivo DLL de IronPDF para integrarlo directamente en tu proyecto. Haz clic en este Descarga del DLL de IronPDF para obtener el archivo ZIP que contiene el DLL. Después de descomprimir, incorpora el DLL en tu proyecto.
Implementación de la lógica
Al integrar las características de ambas bibliotecas, HTML Agility Pack (HAP) y IronPDF se pueden implementar en C# para leer información HTML y producir documentos PDF sobre la marcha. Los pasos para la implementación se enumeran a continuación, junto con un código de muestra que guía a través de cada uno:
- Cargue contenido HTML con HTML Agility Pack: para cargar material HTML desde una fuente, como un archivo, una cadena o una URL, utilice HTML Agility Pack. En esta fase, el documento HTML se analiza y se crea un objeto de documento HTML manipulable.
- Extraer Contenido Deseado: para elegir y extraer contenido particular del documento HTML, usa HTML Agility Pack junto con consultas XPath o LINQ. Esto podría implicar elegir elementos de acuerdo a sus propiedades, etiquetas o estructura jerárquica.
- Convierta HTML a PDF usando IronPDF: para crear un documento PDF a partir del contenido HTML recuperado, utilice IronPDF. IronPDF convierte el material HTML a formato PDF con facilidad manteniendo el estilo y el diseño.
- Opcional: Personalizar la Salida PDF: usa IronPDF para agregar encabezados, pies de página, numeración de páginas y otros componentes dinámicos para personalizar la salida PDF según se requiera. Este paso mejora la apariencia y la utilidad del documento PDF resultante.
- Guardar o transmitir documento PDF: El documento PDF creado puede transmitirse directamente al cliente o navegador para su descarga, o bien guardarse en un archivo. IronPDF ofrece diversas maneras de guardar archivos PDF en diferentes flujos de salida.
using HtmlAgilityPack;
using IronPdf;
using System;
using System.Text;
class Program
{
static void Main()
{
StringBuilder htmlContent = new StringBuilder();
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://ironpdf.com/");
// Select specific elements using XPath or LINQ
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
htmlContent.Append(node.OuterHtml);
Console.WriteLine(node.InnerText);
}
// Convert HTML content to PDF using IronPDF
var Renderer = new HtmlToPdf();
var PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString());
// Save PDF to file
PDF.SaveAs("output.pdf");
Console.WriteLine("PDF generated successfully!");
Console.ReadKey();
}
}using HtmlAgilityPack;
using IronPdf;
using System;
using System.Text;
class Program
{
static void Main()
{
StringBuilder htmlContent = new StringBuilder();
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://ironpdf.com/");
// Select specific elements using XPath or LINQ
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
htmlContent.Append(node.OuterHtml);
Console.WriteLine(node.InnerText);
}
// Convert HTML content to PDF using IronPDF
var Renderer = new HtmlToPdf();
var PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString());
// Save PDF to file
PDF.SaveAs("output.pdf");
Console.WriteLine("PDF generated successfully!");
Console.ReadKey();
}
}Imports HtmlAgilityPack
Imports IronPdf
Imports System
Imports System.Text
Friend Class Program
Shared Sub Main()
Dim htmlContent As New StringBuilder()
' Load HTML content from a file or URL
Dim web As New HtmlWeb()
Dim doc As HtmlDocument = web.Load("https://ironpdf.com/")
' Select specific elements using XPath or LINQ
Dim nodes As HtmlNodeCollection = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']")
' Iterate through selected nodes and extract content
For Each node As HtmlNode In nodes
htmlContent.Append(node.OuterHtml)
Console.WriteLine(node.InnerText)
Next node
' Convert HTML content to PDF using IronPDF
Dim Renderer = New HtmlToPdf()
Dim PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString())
' Save PDF to file
PDF.SaveAs("output.pdf")
Console.WriteLine("PDF generated successfully!")
Console.ReadKey()
End Sub
End ClassVisite el ejemplo de HTML a PDF con IronPDF para saber más sobre el ejemplo de código.
La salida de ejecución se muestra a continuación:
Conclusión
Ya sea analizando datos HTML o creando informes PDF, los desarrolladores pueden gestionar y alterar el material del documento con facilidad gracias a la integración fluida de HTML Agility Pack e IronPDF en C#. Los desarrolladores pueden fácilmente y con precisión automatizar operaciones relacionadas con documentos al combinar las características de producción de PDF de IronPDF con las capacidades de análisis de HTML Agility Pack. La combinación de estas dos bibliotecas proporciona una solución sólida de gestión de documentos en C# independientemente de si estás construyendo informes dinámicos o extrayendo datos de páginas web.
El paquete $999 Lite incluye una licencia perpetua, un año de mantenimiento de software y una actualización de la biblioteca. IronPDF proporciona licencias gratuitas con limitaciones temporales y de redistribución. Durante el período de prueba, los usuarios pueden evaluar la solución sin ver una marca de agua. Por favor, vaya a la Información de Licencia de IronPDF para saber más sobre el costo y la licencia.
Obtenga más información sobre las bibliotecas de Iron Software.
Preguntas Frecuentes
¿Cómo puedo convertir HTML a PDF en C#?
Puedes usar el método RenderHtmlAsPdf de IronPDF para convertir cadenas de HTML en PDFs. También puedes convertir archivos HTML a PDFs usando RenderHtmlFileAsPdf.
¿Cuál es el propósito de usar HtmlAgilityPack en proyectos de C#?
HtmlAgilityPack se utiliza en proyectos de C# para analizar y manipular documentos HTML. Puede manejar HTML mal formateado, lo que lo hace ideal para tareas de web scraping y extracción de datos.
¿Cómo configuro HtmlAgilityPack en una aplicación C#?
Para configurar HtmlAgilityPack, instálalo a través del Administrador de Paquetes NuGet en Visual Studio. Después de la instalación, puedes importar los espacios de nombres necesarios y comenzar a analizar contenido HTML en tu aplicación.
¿Pueden usarse IronPDF y HtmlAgilityPack juntos para la creación de documentos?
Sí, IronPDF y HtmlAgilityPack pueden combinarse para crear documentos PDF dinámicos a partir de contenido HTML. HtmlAgilityPack extrae y manipula datos HTML, que luego pueden convertirse en PDF usando IronPDF.
¿Cuáles son las principales características de IronPDF para desarrolladores .NET?
IronPDF ofrece características como convertir HTML a PDF, fusionar PDFs y agregar texto o imágenes a PDFs. Soporta una amplia gama de funcionalidades para una gestión robusta de documentos PDF en aplicaciones .NET.
¿Cómo puede ayudar HtmlAgilityPack en la extracción de datos de páginas web?
HtmlAgilityPack permite a los desarrolladores cargar documentos HTML y usar consultas XPath o LINQ para navegar y extraer datos basados en nodos o atributos específicos, facilitando la extracción de datos web.
¿Cuáles son los beneficios de integrar una biblioteca PDF con HtmlAgilityPack?
Integrar IronPDF con HtmlAgilityPack mejora la automatización de documentos al permitir la conversión de contenido HTML dinámico en informes PDF, simplificando la generación de documentos en aplicaciones .NET.
¿Es posible usar IronPDF en aplicaciones de consola?
Sí, IronPDF puede implementarse en varios tipos de aplicaciones C#, incluidas las aplicaciones de consola de Windows, permitiendo un procesamiento versátil de documentos y generación de PDFs.
¿Qué tipos de operaciones HTML pueden realizarse con HtmlAgilityPack?
HtmlAgilityPack admite operaciones como agregar, eliminar o modificar nodos y elementos HTML, y reorganizar la estructura del DOM, lo que lo convierte en una herramienta versátil para la manipulación de documentos HTML.
¿Ofrece IronPDF una prueba gratuita para desarrolladores?
IronPDF ofrece una licencia gratuita con ciertas limitaciones, permitiendo a los desarrolladores evaluar la biblioteca sin una marca de agua durante el período de prueba, brindando la oportunidad de probar sus características antes de comprarla.














