
Html Agility Pack C#(對於開發者的運行原理)
在 C# 開發的世界裡,動態管理和操作文件內容的需求非常普遍。 開發人員通常會依賴強大的函式庫來自動執行各種活動,例如建立 PDF 報告和從網頁中擷取資料。 本文探討如何在 C# 中直接整合 IronPDF 與 HTML Agility Pack,並提供程式碼範例,說明如何使用這些函式庫毫不費力地建立 PDF 文件並讀取 HTML 文字。
IronPDF 是一個功能豐富的 .NET 函式庫,用於處理 PDF 檔案。 由於 IronPDF 可讓開發人員從 HTML 內容、URL 或原始資料動態產生 PDF 檔案,因此它是文件建立、報告和資料可視化的重要工具。
為了簡化 .NET 應用程式中的文件產生,我們將在這篇文章中瞭解如何連接 IronPDF 與 HTML Agility Pack。結合這些技術可以讓程式設計師與遠端系統合作、產生動態 PDF 頁面,並透過網路連線取得資料,同時提高程式的生產力與擴充性。
How to Use HtmlAgilityPack in C#
1.建立一個新的 C# 專案。 2.安裝函式庫 HtmlAgilityPack。 3.導入命名空間。 建立一個物件。 4.從 URL 匯入資料並解析 HTML。 5.取得所需資料並處理物件。
HtmlAgilityPack 簡介
HTML Agility Pack 是專為 .NET 開發人員設計的多功能且功能強大的 HTML 解析函式庫。 借助其廣泛的 API 集合,開發人員可以輕鬆地瀏覽、更改 HTML 文件並從中擷取資料。 HTML Agility Pack 讓所有開發人員,不論經驗等級,都能更輕鬆地以程式化方式處理 HTML 內容。
HTML Agility Pack 的獨特之處在於它能夠輕柔地處理組織不良或錯誤的 HTML。 它非常適合 HTML 標記品質可能參差不齊的線上搜刮作業,因為它使用寬容的解析演算法,甚至可以解析結構最糟糕的 HTML。
HtmlAgilityPack 的特點
HTML 解析
透過 HTML Agility Pack 提供的強大 HTML 解析功能,開發人員可以從各種來源載入 HTML 文件,包括檔案、URL 和字串。 由於其寬鬆的解析方式,它可以優雅地處理格式不佳或不正確的 HTML,因此適用於 HTML 標記品質可能不一樣的網頁搜刮活動。
DOM 操作
為了探索、瀏覽及使用 HTML 文件物件模型 (DOM) 結構,HAP 提供了一個使用者友善的 API。 HTML 元素、屬性和文字節點都可以由開發人員以程式化的方式新增、移除或修改,允許動態的 HTML 內容操作。
XPath 和 LINQ 支援。
為了選擇和查詢 HTML 元件,HTML Agility Pack 支援 LINQ(語言整合查詢)以及 XPath 語法查詢。 要根據 HTML 文件中的屬性、標籤或層次來選擇項目,XPath 表達式查詢提供了強大且易於理解的語法。 對於習慣在 C# 中使用 LINQ 的開發人員而言,LINQ 查詢提供了熟悉的查詢語法,有助於與其他 .NET 元件順利整合。
開始使用 HtmlAgilityPack
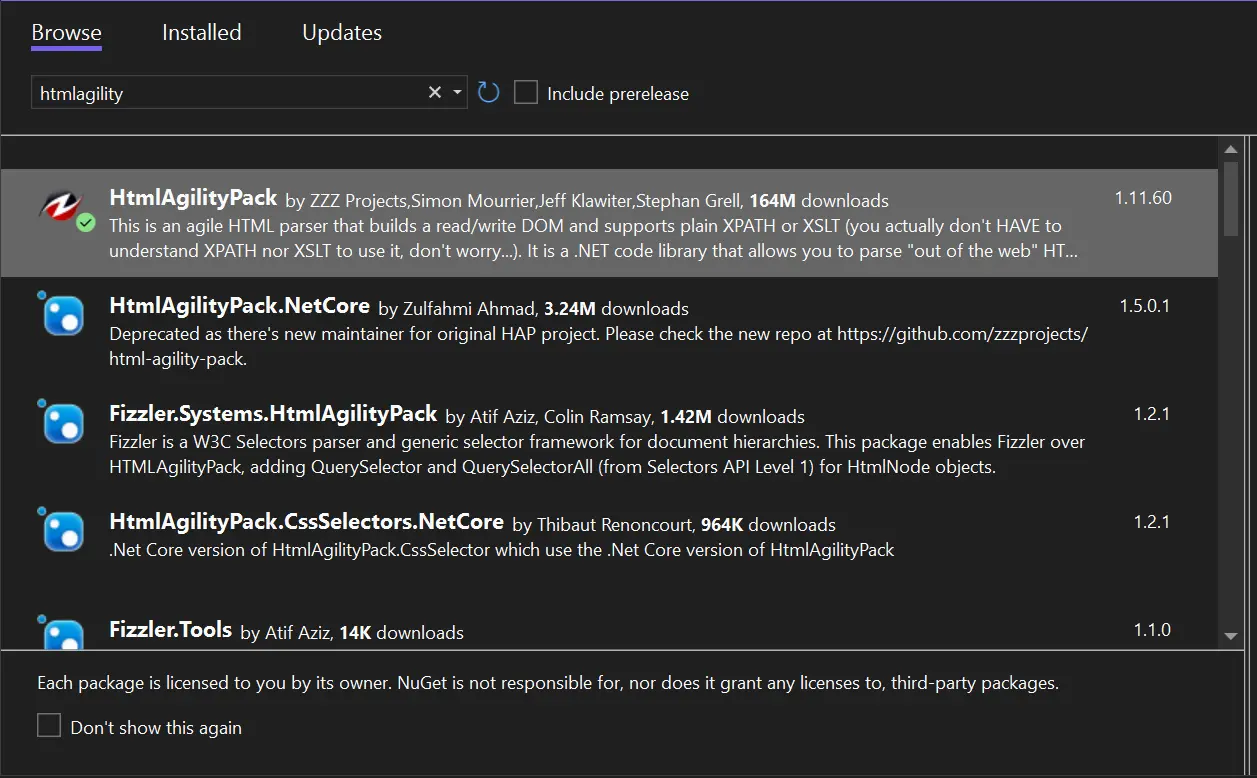
在 C# 專案中設定 HtmlAgilityPack。
HtmlAgility 基礎類函式庫以單一捆綁包的形式提供,安裝後即可在 NuGet 中使用,並可在 C# 專案中使用。 它提供 HTML 解析器以及來自 HTML 文件和 HTML URL 的 CSS 選擇器。
在 Windows Console 和 Forms 中實作 HtmlAgilityPack
許多 C# 應用程式類型,例如 Windows Forms (WinForms) 和 Windows Console,都會實作 HtmlAgilityPack。 儘管不同的架構有不同的實作方式,但基本的想法始終不變。
 。
。
HtmlAgilityPack C# 示例
在 C# 開發人員的工具箱中,HTML Agility Pack (HAP) 是瀏覽、處理和使用 HTML 文件的最重要工具之一。 HTML 頁面的資料擷取因其友善的 API 而變得更容易,其運作方式就像一棵有組織的元素樹。 讓我們檢視一個直接的程式碼範例,以示範如何使用。
using HtmlAgilityPack;
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
var doc = web.Load("https://ironpdf.com/");
// Select specific html nodes and parse html string
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
Console.WriteLine(node.InnerText);
}
Console.ReadKey();using HtmlAgilityPack;
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
var doc = web.Load("https://ironpdf.com/");
// Select specific html nodes and parse html string
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
Console.WriteLine(node.InnerText);
}
Console.ReadKey();Imports HtmlAgilityPack
' Load HTML content from a file or URL
Private web As New HtmlWeb()
Private doc = web.Load("https://ironpdf.com/")
' Select specific html nodes and parse html string
Private nodes As HtmlNodeCollection = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']")
' Iterate through selected nodes and extract content
For Each node As HtmlNode In nodes
Console.WriteLine(node.InnerText)
Next node
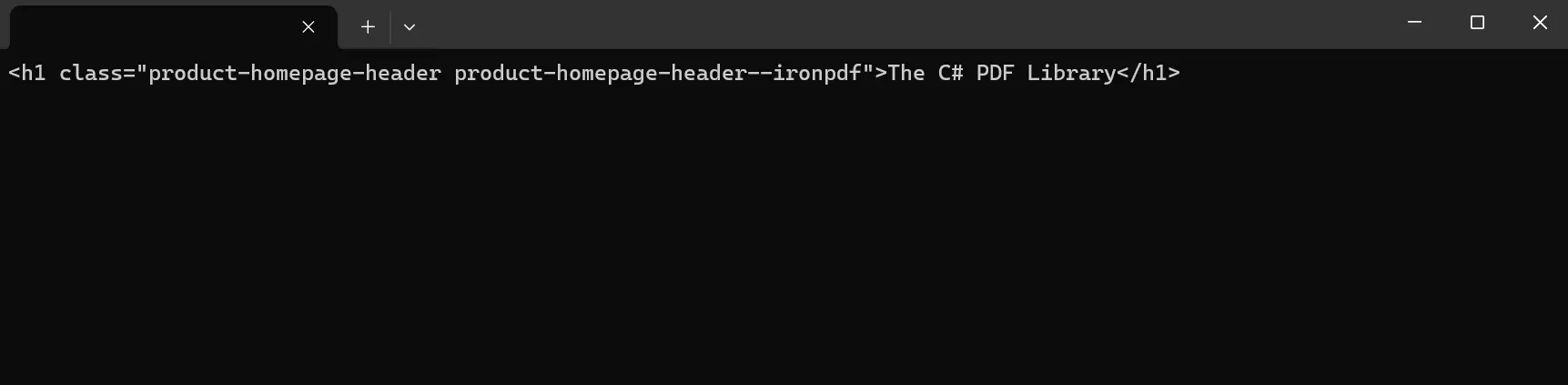
Console.ReadKey()在本範例中,我們使用 HTML Agility Pack 從 URL 載入 HTML 節點素材。 然後,將 HTML 載入到 var doc 中進行解析和操作。 為了擷取內容,程式首先會識別 HTML 文件的根節點,然後使用 XPath 查詢特定目標文件內的節點。 從上面的程式碼中,我們特別從字串 HTML 資料中選取具有 product-homepage-header 類別的 div 元素,然後將每個選取節點的內文列印到控制台。
 。
。
HtmlAgilityPack 操作
HTML 轉換
開發人員可以使用 HTML Agility Pack 對 HTML 文字執行多種轉換和處理。 除了重組 HTML 文件的 DOM 層級結構之外,還包括新增、刪除或變更文字節點、元素和屬性等操作。
延伸性
由於 HAP 意圖是可擴充的,程式設計師可以加入新的功能和行為來增加其功能。 使用提供的 API,開發人員可以設計自己的 HTML 解析器、過濾器或操作器,以客製化 HAP,滿足其獨特的需求和使用個案。
效能與效率
HTML Agility Pack 的演算法和資料結構可以很好地處理大型 HTML 文字,並針對速度和效能進行調整。 透過降低記憶體使用率和處理開銷,確保快速且反應迅速的 HTML 內容解析和操作。
將 HtmlAgilityPack 與 IronPDF 整合。
使用 IronPDF 與 HtmlAgilityPack。
當 HTML Agility Pack 與 IronPDF for PDF Conversion 結合時,文件管理與報表製作將有無限可能。 透過使用 HTML Agility Pack 進行 HTML 解析和 IronPDF Documentation 進行 PDF 轉換,開發人員可以毫不費力地從動態線上資料自動建立 PDF 文件。
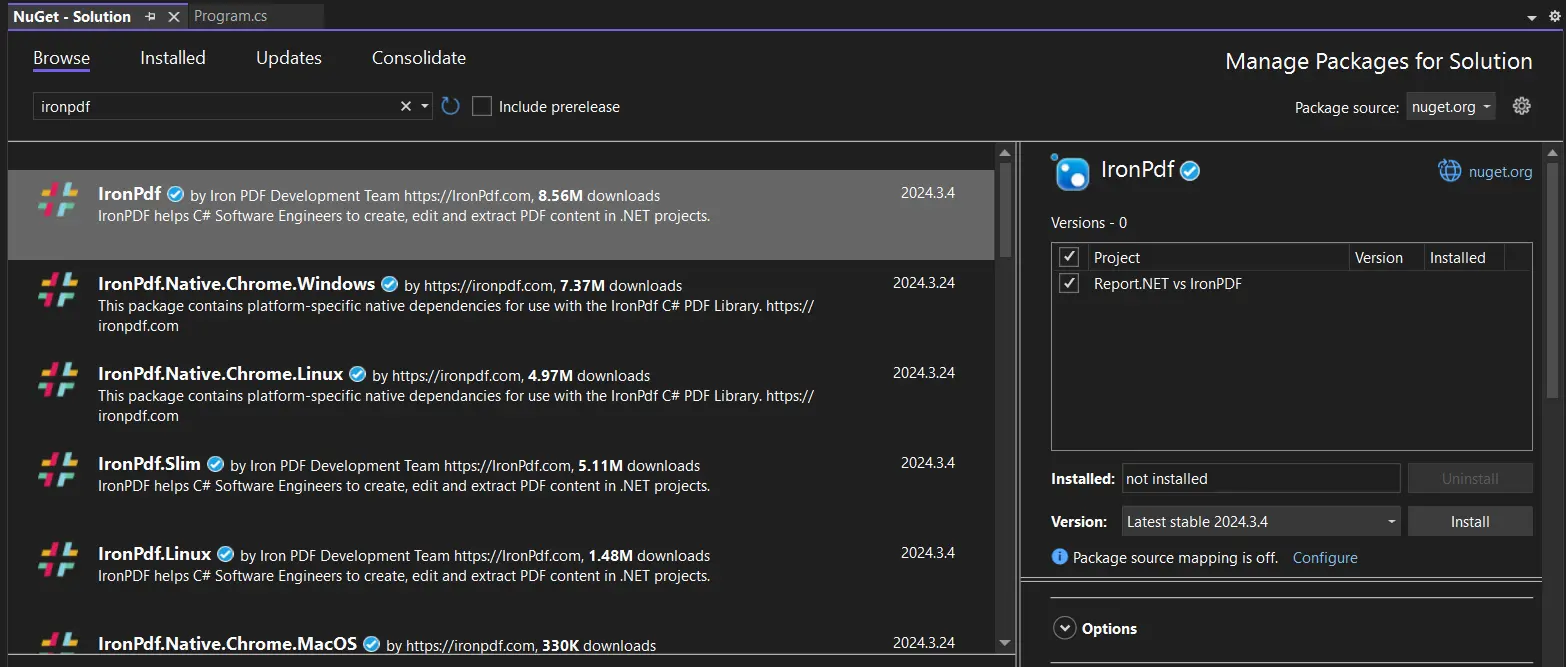
安裝 IronPDF。
- 啟動 Visual Studio 專案。
- 選擇"工具">"NuGet Package Manager">"Package Manager Console"。
- 在套件管理員控制台輸入此指令:
Install-Package IronPdf
- 作為替代方案,您可以使用 NuGet Package Manager for Solutions 安裝 IronPDF。
-
可瀏覽 IronPDF 套件的搜尋結果,並進行選擇,然後點選"安裝"按鈕。 Visual Studio 會為您進行安裝和下載。
 。
。 - 您的專案所需的 IronPDF 套件和任何相依性將由 NuGet 安裝。
- IronPDF 安裝完成後即可用於您的專案。
透過 NuGet 網站安裝
若要瞭解 IronPDF 的功能、相容性及其他下載選擇的詳細資訊,請參閱其 IronPDF NuGet 套件資訊,位於 NuGet 網站。
利用 DLL 安裝
作為替代方案,您可以使用 IronPDF 的 DLL 檔案直接將其整合到您的專案中。 按一下此 IronPDF DLL Download 以取得包含 DLL 的 ZIP 檔案。 解壓縮後,將 DLL 納入您的專案中。
實作邏輯
透過整合這兩個函式庫的功能,HTML Agility Pack (HAP) 和 IronPDF 可以在 C# 中實作,讀取 HTML 資訊並即時產生 PDF 文件。 以下列出了實施的步驟,以及每個步驟的示範程式碼:
1.使用 HTML Agility Pack 載入 HTML 內容:若要從文件、字串或 URL 等來源載入 HTML 材料,請使用 HTML Agility Pack。 在此階段,HTML 文件會被解析,並建立一個可操作的 HTML 文件物件。 2.擷取所需內容:若要從 HTML 文件中選擇並擷取特定內容,請搭配 XPath 或 LINQ 查詢使用 HTML Agility Pack。 這可能需要根據元素的屬性、標籤或層次結構來選擇元素。 3.使用 IronPDF 將 HTML 轉換為 PDF:要從檢索到的 HTML 內容建立 PDF 文檔,請使用 IronPDF。 IronPDF 可輕鬆地將 HTML 資料轉換為 PDF 格式,同時保持樣式和排版。 4.選項:自訂 PDF 輸出:使用 IronPDF 新增頁眉、頁腳、頁碼和其他動態元件,以根據需要自訂 PDF 輸出。 此步驟可改善 PDF 文件的外觀和可用性。 5.儲存或串流 PDF 文件:建立的 PDF 文件可以直接串流到客戶端或瀏覽器以供下載,也可以儲存到文件。 IronPDF 提供多種將 PDF 檔案儲存到不同輸出流的方式。
using HtmlAgilityPack;
using IronPdf;
using System;
using System.Text;
class Program
{
static void Main()
{
StringBuilder htmlContent = new StringBuilder();
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://ironpdf.com/");
// Select specific elements using XPath or LINQ
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
htmlContent.Append(node.OuterHtml);
Console.WriteLine(node.InnerText);
}
// Convert HTML content to PDF using IronPDF
var Renderer = new HtmlToPdf();
var PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString());
// Save PDF to file
PDF.SaveAs("output.pdf");
Console.WriteLine("PDF generated successfully!");
Console.ReadKey();
}
}using HtmlAgilityPack;
using IronPdf;
using System;
using System.Text;
class Program
{
static void Main()
{
StringBuilder htmlContent = new StringBuilder();
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://ironpdf.com/");
// Select specific elements using XPath or LINQ
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
htmlContent.Append(node.OuterHtml);
Console.WriteLine(node.InnerText);
}
// Convert HTML content to PDF using IronPDF
var Renderer = new HtmlToPdf();
var PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString());
// Save PDF to file
PDF.SaveAs("output.pdf");
Console.WriteLine("PDF generated successfully!");
Console.ReadKey();
}
}Imports HtmlAgilityPack
Imports IronPdf
Imports System
Imports System.Text
Friend Class Program
Shared Sub Main()
Dim htmlContent As New StringBuilder()
' Load HTML content from a file or URL
Dim web As New HtmlWeb()
Dim doc As HtmlDocument = web.Load("https://ironpdf.com/")
' Select specific elements using XPath or LINQ
Dim nodes As HtmlNodeCollection = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']")
' Iterate through selected nodes and extract content
For Each node As HtmlNode In nodes
htmlContent.Append(node.OuterHtml)
Console.WriteLine(node.InnerText)
Next node
' Convert HTML content to PDF using IronPDF
Dim Renderer = New HtmlToPdf()
Dim PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString())
' Save PDF to file
PDF.SaveAs("output.pdf")
Console.WriteLine("PDF generated successfully!")
Console.ReadKey()
End Sub
End Class請造訪 利用 IronPDF 進行轉換,以瞭解更多關於程式碼範例的資訊。
 。
。
執行輸出如下所示:
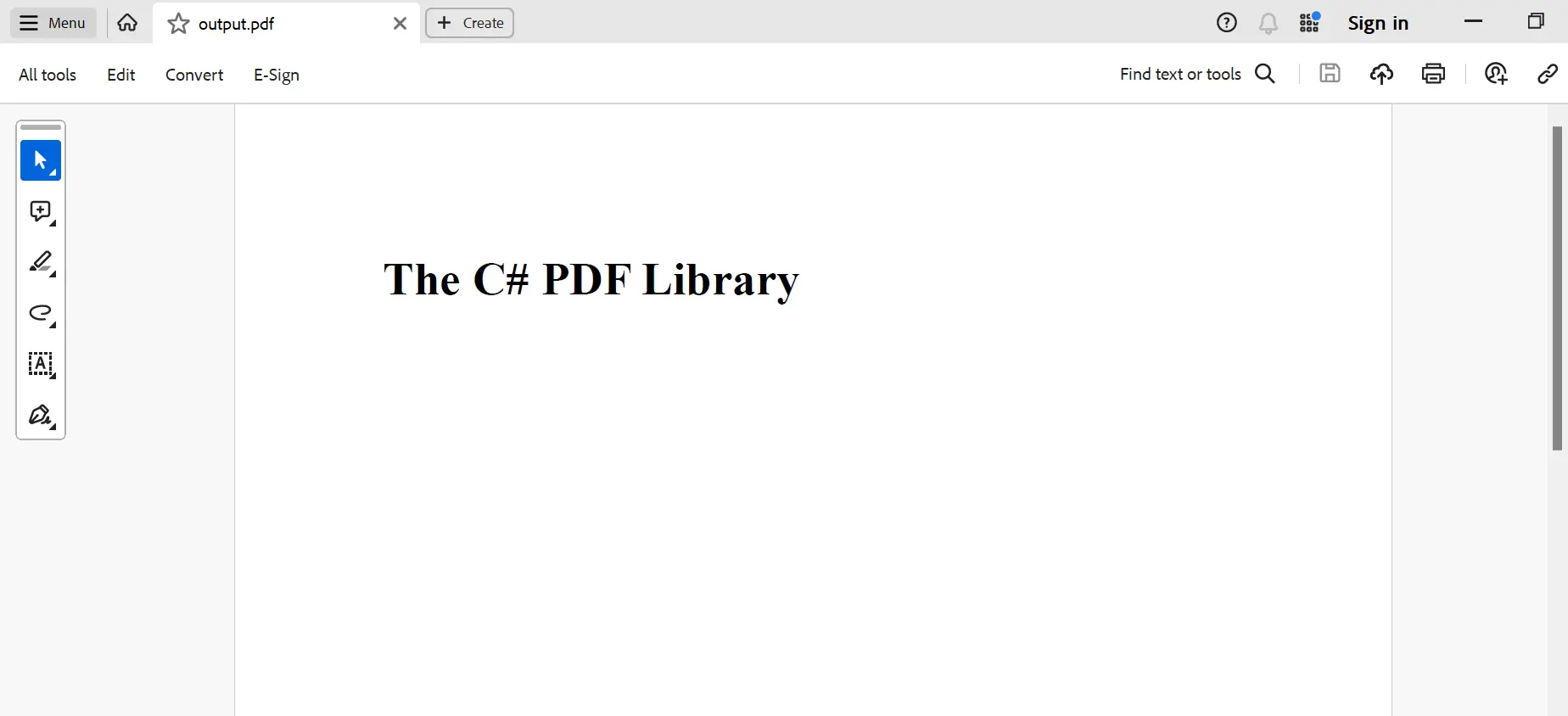
結論
無論是解析 HTML 資料或建立 PDF 報表,由於 HTML Agility Pack 與 IronPDF in C# 的順暢整合,開發人員都能輕鬆管理和修改文件資料。 開發人員可透過結合 IronPDF 的 PDF 製作功能與 HTML Agility Pack 的解析功能,輕鬆且精確地自動執行與文件相關的作業。 這兩個函式庫的結合提供了強大的 C# 文件管理解決方案,無論您是建立動態報表或是從網頁中抽取資料。
$999 Lite 套裝包含永久許可證、一年的軟體維護和庫升級。 IronPDF 提供免費授權,但有時間和再散佈的限制。 在試用期間,使用者可以在看不到水印的情況下評估解決方案。 請至 IronPDF 的授權資訊了解更多關於費用和授權的資訊。
進一步了解 Iron Software 函式庫。
常見問題
怎樣在 C# 中將 HTML 轉換為 PDF?
您可以使用 IronPDF 的 RenderHtmlAsPdf 方法將 HTML 字符串轉換為 PDF。您還可以使用 RenderHtmlFileAsPdf 將 HTML 文件轉換為 PDF。
在 C# 項目中使用 HtmlAgilityPack 的目的是什麼?
HtmlAgilityPack 用於 C# 項目中解析和處理 HTML 文檔。它可以處理格式不佳的 HTML,非常適合網頁爬取和數據提取任務。
如何在 C# 應用程序中設置 HtmlAgilityPack?
要設置 HtmlAgilityPack,請在 Visual Studio 中通過 NuGet Package Manager 安裝。安裝完成後,您可以導入必要的命名空間並在應用程序中開始解析 HTML 內容。
IronPDF 和 HtmlAgilityPack 能否一起用於文件創建?
是的,IronPDF 和 HtmlAgilityPack 可以結合起來從 HTML 內容創建動態 PDF 文件。HtmlAgilityPack 提取並操作 HTML 數據,然後可以使用 IronPDF 將其轉換為 PDF。
IronPDF 對於 .NET 開發人員的主要功能是什麼?
IronPDF 提供的功能包括將 HTML 轉換為 PDF、合併 PDF 以及將文本或圖像添加到 PDF。它支持廣泛的功能,用於 .NET 應用程序中的強大 PDF 文檔管理。
HtmlAgilityPack 如何幫助從網頁中提取數據?
HtmlAgilityPack 允許開發人員加載 HTML 文檔,並使用 XPath 或 LINQ 查詢來導航和提取基於特定節點或屬性的數據,以促進網頁數據提取。
將 PDF 庫與 HtmlAgilityPack 集成的好處是什麼?
將 IronPDF 與 HtmlAgilityPack 結合使用可以通過將動態 HTML 內容轉換為 PDF 報告來增強文檔自動化,從而簡化 .NET 應用程序中的文檔生成。
能否在控制台應用程序中使用 IronPDF?
是的,IronPDF 可以在各種 C# 應用程序類型中實施,包括 Windows 控制台應用程序,這樣可以實現多功能的文檔處理和 PDF 生成。
可使用 HtmlAgilityPack 執行哪些類型的 HTML 操作?
HtmlAgilityPack 支持添加、刪除或修改 HTML 節點和元素,以及重組 DOM 結構等操作,是用於 HTML 文檔處理的多功能工具。
IronPDF 是否提供開發人員的免費試用版?
IronPDF 提供一定限制的免費許可,允許開發人員在試用期間無水印地評估該庫,提供在購買前測試其功能的機會。













