
Pacote de Agilidade HTML em C# (Como funciona para desenvolvedores)
A necessidade de gerenciar e manipular dinamicamente o conteúdo de documentos é generalizada no mundo do desenvolvimento em C#. Os desenvolvedores geralmente dependem de bibliotecas robustas para automatizar atividades como a criação de relatórios em PDF e a extração de dados de páginas da web. Este artigo explora a integração simples do IronPDF e do HTML Agility Pack em C# e fornece exemplos de código para demonstrar como essas bibliotecas podem ser usadas para criar documentos PDF e ler texto HTML sem esforço.
IronPDF é uma biblioteca .NET rica em recursos para trabalhar com arquivos PDF. Como o IronPDF permite que os desenvolvedores gerem arquivos PDF dinamicamente a partir de conteúdo HTML, URLs ou dados brutos, ele serve como uma ferramenta valiosa para criação de documentos, relatórios e visualização de dados.
Para agilizar a geração de documentos em aplicações .NET , neste artigo veremos como conectar o IronPDF ao HTML Agility Pack. A combinação dessas tecnologias permite que os programadores trabalhem com sistemas remotos, gerem páginas PDF dinâmicas e obtenham dados via conectividade de rede, aumentando a produtividade e a escalabilidade de seus programas.
How to Use HtmlAgilityPack in C
- Crie um novo projeto em C#.
- Instale a biblioteca HtmlAgilityPack.
- Importe o namespace. Criar um objeto.
- Importar dados da URL e analisar o HTML.
- Obtenha os dados necessários e descarte o objeto.
Introdução ao HtmlAgilityPack
O HTML Agility Pack é uma biblioteca de análise HTML versátil e poderosa para desenvolvedores .NET . Com a ajuda de sua extensa coleção de APIs, os desenvolvedores podem navegar, alterar e extrair dados de documentos HTML com facilidade. O HTML Agility Pack facilita o trabalho com conteúdo HTML de forma programática para todos os desenvolvedores, independentemente do nível de experiência.
A capacidade do HTML Agility Pack de gerenciar com cuidado HTML mal organizado ou com erros é o que o torna único. É perfeito para operações de extração de dados online, onde a qualidade da marcação HTML pode variar, pois utiliza um algoritmo de análise sintática tolerante que consegue analisar até mesmo o HTML mais mal construído.
Funcionalidades do HtmlAgilityPack
Análise de HTML
Com os poderosos recursos de análise de HTML oferecidos pelo HTML Agility Pack, os desenvolvedores podem carregar documentos HTML de diversas fontes, incluindo arquivos, URLs e strings. Graças à sua abordagem de análise sintática flexível, ele consegue lidar de forma eficiente com HTML mal formatado ou incorreto, tornando-o adequado para atividades de web scraping onde a qualidade da marcação HTML pode variar.
Manipulação do DOM
Para explorar, navegar e trabalhar com a estrutura do Modelo de Objeto de Documento HTML (DOM), o HAP oferece uma API amigável. Elementos HTML, atributos e nós de texto podem ser adicionados, removidos ou modificados programaticamente pelos desenvolvedores, permitindo a manipulação dinâmica do conteúdo HTML.
Suporte a XPath e LINQ
Para selecionar e consultar componentes HTML, o HTML Agility Pack oferece suporte a pesquisas com LINQ (Language Integrated Query), bem como com a sintaxe XPath. Para selecionar itens em um documento HTML de acordo com seus atributos, tags ou hierarquia, as consultas com expressões XPath oferecem uma sintaxe robusta e fácil de entender. Para desenvolvedores acostumados a trabalhar com LINQ em C#, as consultas LINQ oferecem uma sintaxe de consulta familiar que facilita a integração perfeita com outros componentes .NET .
Primeiros passos com o HtmlAgilityPack
Configurando o HtmlAgilityPack em Projetos C
A biblioteca de classes base HtmlAgility é fornecida em um único pacote agrupado, que deve estar disponível no NuGet após a instalação e pode ser usado no projeto C#. Oferece um analisador HTML e seletores CSS a partir do documento HTML e URLs HTML.
Implementando o HtmlAgilityPack no Console e no Windows Forms
Muitos tipos de aplicativos C#, como Windows Forms (WinForms) e Windows Console, implementam o HtmlAgilityPack. Embora a implementação varie de framework para framework, a ideia fundamental permanece constante.
Exemplo de HtmlAgilityPack em C
Uma das ferramentas mais importantes no conjunto de ferramentas do desenvolvedor C# para navegar, processar e trabalhar com documentos HTML é o HTML Agility Pack (HAP). A extração de dados de páginas HTML é facilitada por sua API amigável, que funciona como uma árvore organizada de elementos. Vamos examinar um exemplo de código simples para demonstrar como usá-lo.
using HtmlAgilityPack;
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
var doc = web.Load("https://ironpdf.com/");
// Select specific html nodes and parse html string
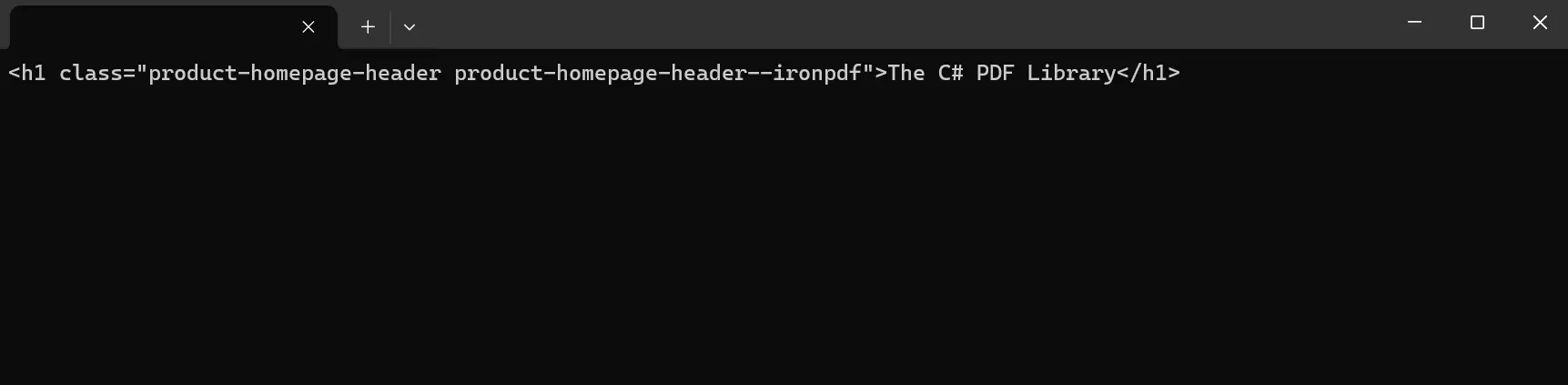
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
Console.WriteLine(node.InnerText);
}
Console.ReadKey();using HtmlAgilityPack;
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
var doc = web.Load("https://ironpdf.com/");
// Select specific html nodes and parse html string
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
Console.WriteLine(node.InnerText);
}
Console.ReadKey();Imports HtmlAgilityPack
' Load HTML content from a file or URL
Private web As New HtmlWeb()
Private doc = web.Load("https://ironpdf.com/")
' Select specific html nodes and parse html string
Private nodes As HtmlNodeCollection = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']")
' Iterate through selected nodes and extract content
For Each node As HtmlNode In nodes
Console.WriteLine(node.InnerText)
Next node
Console.ReadKey()Neste exemplo, carregamos conteúdo de nós HTML a partir de uma URL usando o HTML Agility Pack. O HTML é então carregado no var doc para análise e manipulação. Para extrair o conteúdo, o programa primeiro identifica o nó raiz do documento HTML e, em seguida, seleciona nós específicos dentro do documento usando consultas XPath. No código acima, selecionamos especificamente elementos div com a classe product-homepage-header dos dados HTML da string e, em seguida, o texto interno de cada nó selecionado é impresso no console.
Operações HtmlAgilityPack
Transformação HTML
Os desenvolvedores podem realizar diversas transformações e manipulações em textos HTML usando o HTML Agility Pack. Isso abrange operações como adicionar, excluir ou alterar nós de texto, elementos e atributos, além de reorganizar a hierarquia DOM do documento HTML.
Extensibilidade
Como o HAP foi projetado para ser expansível, os programadores podem adicionar novos recursos e comportamentos para aumentar sua funcionalidade. Utilizando a API fornecida, os desenvolvedores podem criar seus próprios analisadores, filtros ou manipuladores HTML para personalizar o HAP de acordo com suas necessidades e casos de uso específicos.
Desempenho e Eficiência
Textos HTML extensos podem ser processados com eficiência pelos algoritmos e estruturas de dados do HTML Agility Pack, que é otimizado para velocidade e eficácia. Isso garante uma análise e manipulação de conteúdo HTML rápidas e responsivas, reduzindo a utilização de memória e a sobrecarga de processamento.
Integração de HtmlAgilityPack com IronPDF
Utilizando o IronPDF com o HtmlAgilityPack
As possibilidades de gerenciamento de documentos e criação de relatórios são infinitas quando o HTML Agility Pack e o IronPDF para conversão de PDF são combinados. Por meio do uso do HTML Agility Pack para análise sintática de HTML e do IronPDF Documentation para conversão de PDF, os desenvolvedores podem automatizar facilmente a criação de documentos PDF a partir de material online dinâmico.
Instale o IronPDF
- Inicie o projeto do Visual Studio.
- Selecione "Ferramentas" > "Gerenciador de Pacotes NuGet " > "Console do Gerenciador de Pacotes".
- Insira este comando no Console do Gerenciador de Pacotes:
Install-Package IronPdf
Como alternativa, você pode usar o NuGet Package Manager for Solutions para instalar o IronPDF.
-
Os resultados da pesquisa para o pacote IronPDF podem ser visualizados, selecionados e, em seguida, o botão "Instalar" pode ser clicado. O Visual Studio cuidará da instalação e do download para você.
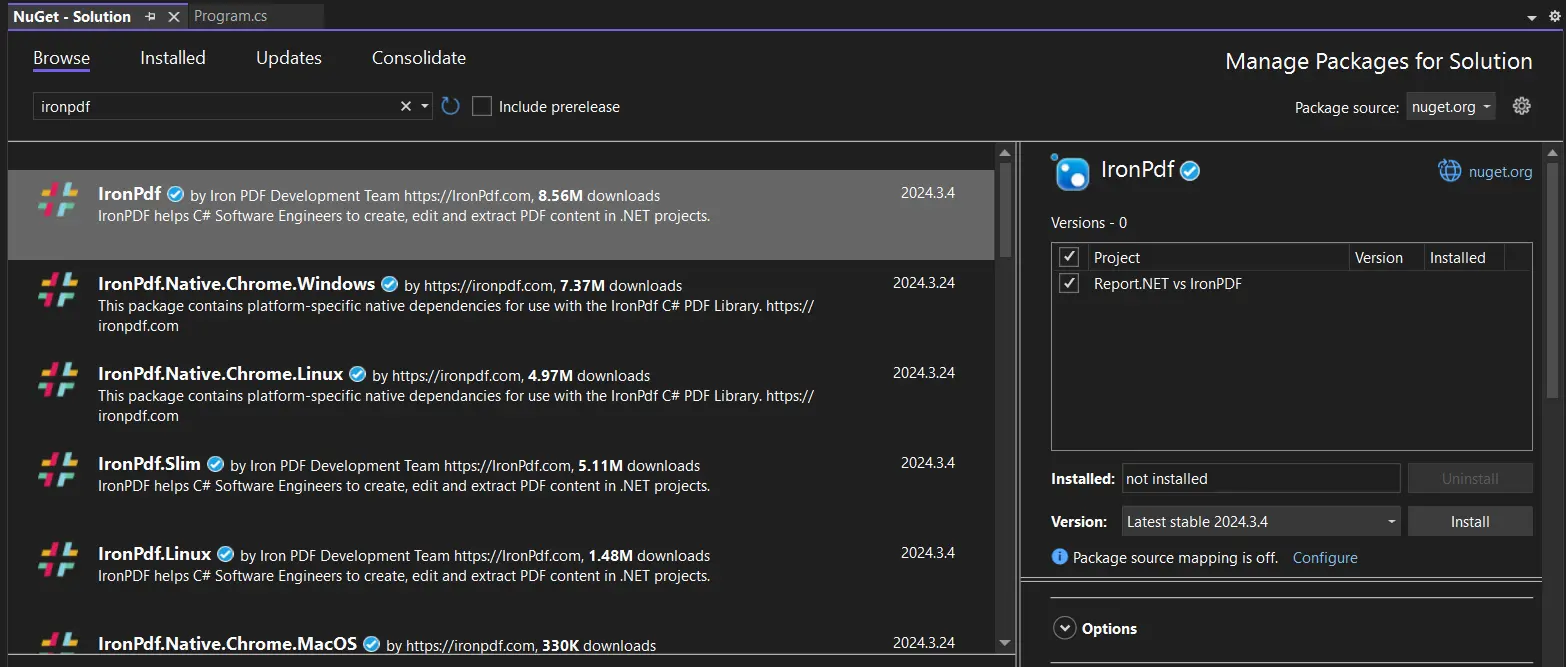
- O pacote IronPDF e quaisquer dependências necessárias para o seu projeto serão instalados pelo NuGet.
- O IronPDF pode ser usado em seu projeto após a instalação.
Instale através do site do NuGet.
Para saber mais sobre os recursos, a compatibilidade e outras opções de download do IronPDF , consulte as informações do pacote NuGet do IronPDF no site do NuGet .
Utilize DLL para instalar
Como alternativa, você pode usar o arquivo DLL do IronPDF para integrá-lo diretamente ao seu projeto. Clique neste link para baixar o arquivo ZIP contendo a DLL do IronPDF . Após descompactar, incorpore a DLL ao seu projeto.
Implementando a lógica
Ao integrar as funcionalidades de ambas as bibliotecas, o HTML Agility Pack (HAP) e o IronPDF podem ser implementados em C# para ler informações HTML e gerar documentos PDF dinamicamente. Os passos para a implementação estão listados abaixo, juntamente com um exemplo de código que demonstra cada um deles:
- Carregar conteúdo HTML usando o HTML Agility Pack: Para carregar material HTML de uma fonte, como um arquivo, string ou URL, use o HTML Agility Pack. Nesta fase, o documento HTML é analisado e um objeto de documento HTML manipulável é criado.
- Extrair o conteúdo desejado: Para selecionar e extrair conteúdo específico do documento HTML, utilize o HTML Agility Pack em conjunto com consultas XPath ou LINQ. Isso pode implicar a escolha de elementos de acordo com suas propriedades, tags ou estrutura hierárquica.
- Converter HTML para PDF usando o IronPDF: Para criar um documento PDF a partir do conteúdo HTML obtido, use o IronPDF. O IronPDF converte material HTML para o formato PDF com facilidade, mantendo o estilo e o layout.
- Opcional: Personalizar a saída em PDF: Use o IronPDF para adicionar cabeçalhos, rodapés, numeração de páginas e outros componentes dinâmicos para personalizar a saída em PDF conforme necessário. Esta etapa melhora a aparência e a usabilidade do documento PDF resultante.
- Salvar ou transmitir documento PDF: O documento PDF criado pode ser transmitido diretamente para o cliente ou navegador para download, ou pode ser salvo em um arquivo. O IronPDF oferece maneiras de salvar arquivos PDF em diferentes fluxos de saída.
using HtmlAgilityPack;
using IronPdf;
using System;
using System.Text;
class Program
{
static void Main()
{
StringBuilder htmlContent = new StringBuilder();
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://ironpdf.com/");
// Select specific elements using XPath or LINQ
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
htmlContent.Append(node.OuterHtml);
Console.WriteLine(node.InnerText);
}
// Convert HTML content to PDF using IronPDF
var Renderer = new HtmlToPdf();
var PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString());
// Save PDF to file
PDF.SaveAs("output.pdf");
Console.WriteLine("PDF generated successfully!");
Console.ReadKey();
}
}using HtmlAgilityPack;
using IronPdf;
using System;
using System.Text;
class Program
{
static void Main()
{
StringBuilder htmlContent = new StringBuilder();
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://ironpdf.com/");
// Select specific elements using XPath or LINQ
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
htmlContent.Append(node.OuterHtml);
Console.WriteLine(node.InnerText);
}
// Convert HTML content to PDF using IronPDF
var Renderer = new HtmlToPdf();
var PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString());
// Save PDF to file
PDF.SaveAs("output.pdf");
Console.WriteLine("PDF generated successfully!");
Console.ReadKey();
}
}Imports HtmlAgilityPack
Imports IronPdf
Imports System
Imports System.Text
Friend Class Program
Shared Sub Main()
Dim htmlContent As New StringBuilder()
' Load HTML content from a file or URL
Dim web As New HtmlWeb()
Dim doc As HtmlDocument = web.Load("https://ironpdf.com/")
' Select specific elements using XPath or LINQ
Dim nodes As HtmlNodeCollection = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']")
' Iterate through selected nodes and extract content
For Each node As HtmlNode In nodes
htmlContent.Append(node.OuterHtml)
Console.WriteLine(node.InnerText)
Next node
' Convert HTML content to PDF using IronPDF
Dim Renderer = New HtmlToPdf()
Dim PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString())
' Save PDF to file
PDF.SaveAs("output.pdf")
Console.WriteLine("PDF generated successfully!")
Console.ReadKey()
End Sub
End ClassVisite a página Utilizando o IronPDF para Conversão para saber mais sobre o exemplo de código.
O resultado da execução é mostrado abaixo:
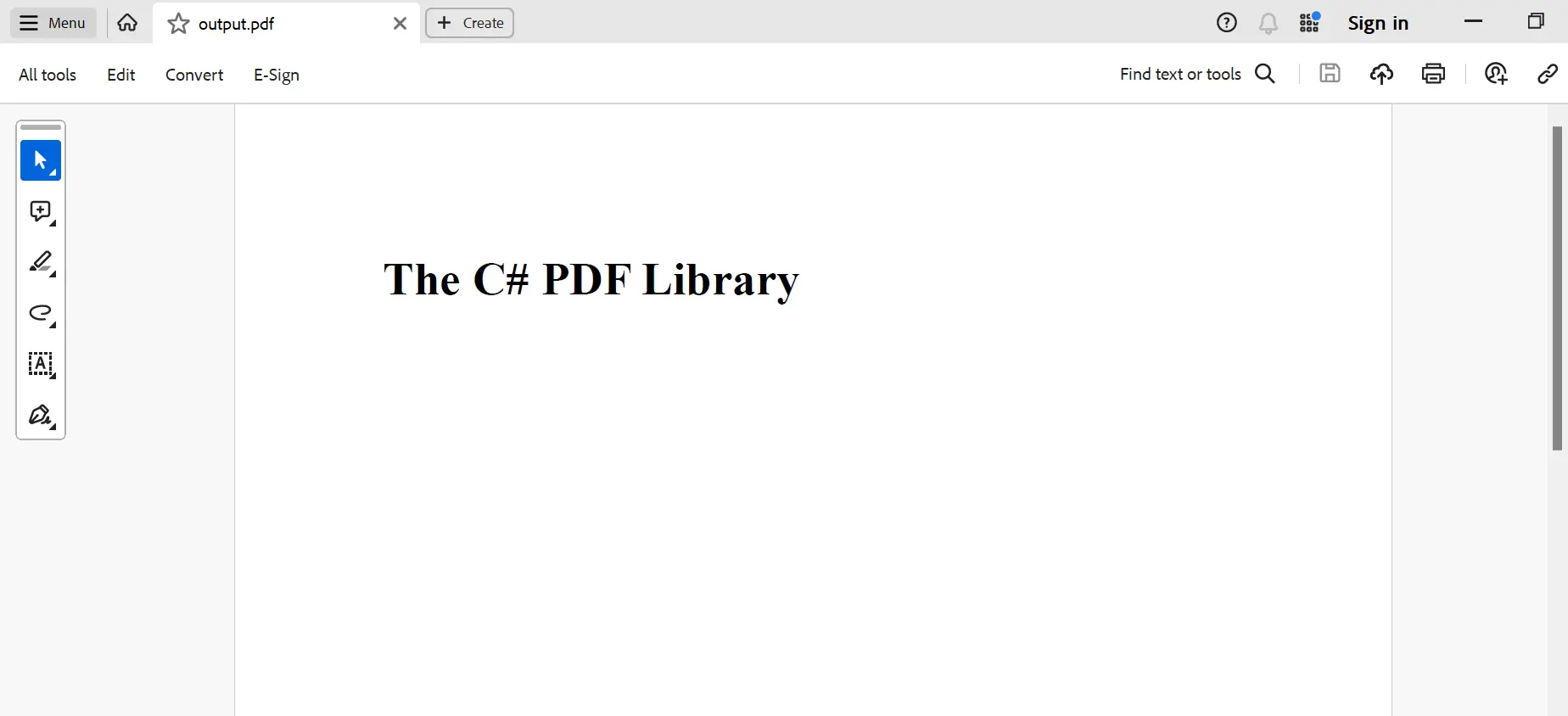
Conclusão
Seja analisando dados HTML ou criando relatórios em PDF, os desenvolvedores podem gerenciar e alterar o conteúdo dos documentos com facilidade graças à integração perfeita do HTML Agility Pack e do IronPDF em C#. Os desenvolvedores podem automatizar com facilidade e precisão as operações relacionadas a documentos, combinando os recursos de produção de PDF do IronPDF com as capacidades de análise sintática do HTML Agility Pack. A combinação dessas duas bibliotecas oferece uma solução robusta de gerenciamento de documentos em C#, independentemente de você estar criando relatórios dinâmicos ou extraindo dados de páginas da web.
Uma licença perpétua, um ano de manutenção de software e uma atualização de biblioteca estão todos incluídos no $999 pacote Lite. O IronPDF oferece licença gratuita com limitações temporais e de redistribuição. Durante o período de teste, os usuários podem avaliar a solução sem visualizar a marca d'água. Acesse a página de Informações sobre Licenciamento do IronPDF para saber mais sobre custos e licenças.
Saiba mais sobre as bibliotecas da Iron Software .
Perguntas frequentes
Como posso converter HTML para PDF em C#?
Você pode usar o método RenderHtmlAsPdf do IronPDF para converter strings HTML em PDFs. Você também pode converter arquivos HTML em PDFs usando o RenderHtmlFileAsPdf .
Qual a finalidade de usar o HtmlAgilityPack em projetos C#?
O HtmlAgilityPack é usado em projetos C# para analisar e manipular documentos HTML. Ele consegue lidar com HTML mal formatado, sendo ideal para tarefas de web scraping e extração de dados.
Como faço para configurar o HtmlAgilityPack em uma aplicação C#?
Para configurar o HtmlAgilityPack, instale-o através do Gerenciador de Pacotes NuGet no Visual Studio. Após a instalação, você poderá importar os namespaces necessários e começar a analisar o conteúdo HTML em sua aplicação.
É possível usar o IronPDF e o HtmlAgilityPack juntos para a criação de documentos?
Sim, o IronPDF e o HtmlAgilityPack podem ser combinados para criar documentos PDF dinâmicos a partir de conteúdo HTML. O HtmlAgilityPack extrai e manipula dados HTML, que podem então ser convertidos em PDF usando o IronPDF.
Quais são as principais funcionalidades do IronPDF para desenvolvedores .NET?
O IronPDF oferece recursos como conversão de HTML para PDF, mesclagem de PDFs e adição de texto ou imagens a PDFs. Ele suporta uma ampla gama de funcionalidades para um gerenciamento robusto de documentos PDF em aplicações .NET.
Como o HtmlAgilityPack pode ajudar na extração de dados de páginas da web?
O HtmlAgilityPack permite que os desenvolvedores carreguem documentos HTML e usem consultas XPath ou LINQ para navegar e extrair dados com base em nós ou atributos específicos, facilitando a extração de dados da web.
Quais são os benefícios de integrar uma biblioteca de PDFs com o HtmlAgilityPack?
A integração do IronPDF com o HtmlAgilityPack aprimora a automação de documentos, permitindo a conversão de conteúdo HTML dinâmico em relatórios PDF e simplificando a geração de documentos em aplicativos .NET.
É possível usar o IronPDF em aplicativos de console?
Sim, o IronPDF pode ser implementado em vários tipos de aplicativos C#, incluindo aplicativos de console do Windows, permitindo processamento versátil de documentos e geração de PDFs.
Que tipos de operações HTML podem ser realizadas com o HtmlAgilityPack?
O HtmlAgilityPack suporta operações como adicionar, excluir ou modificar nós e elementos HTML, além de reorganizar a estrutura DOM, tornando-se uma ferramenta versátil para manipulação de documentos HTML.
O IronPDF oferece um período de teste gratuito para desenvolvedores?
O IronPDF oferece uma licença gratuita com certas limitações, permitindo que os desenvolvedores avaliem a biblioteca sem marca d'água durante o período de teste, proporcionando a oportunidade de testar seus recursos antes da compra.














