
Html Agility Pack C# (jak to działa dla programistów)
Potrzeba dynamicznego zarządzania i manipulowania zawartościa dokumentów jest powszechna w świecie rozwoju C#. Deweloperzy często polegają na solidnych bibliotekach, aby zautomatyzowac działania takie jak tworzenie raportow PDF i pobieranie danych ze stron internetowych. Artykul ten omawia prosta integracje IronPDF i HTML Agility Pack w C# i zawiera przykłady kodu, które pokazują, jak te biblioteki mogą być wykorzystywane do bezproblemowego tworzenia dokumentów PDF i odczytywania tekstu HTML.
IronPDF to bogata w funkcje biblioteka .NET do pracy z plikami PDF. Poniewaz IronPDF pozwala deweloperom dynamicznie generować pliki PDF z zawartości HTML, URL-i lub danych surowych, sluzy jako cenne narzędzie do tworzenia dokumentów, raportowania i wizualizacji danych.
Aby usprawnic generowanie dokumentów w aplikacjach .NET, przyjrzymy sie, jak połączyć IronPDF z HTML Agility Pack w tym poscie. Połączenie tych technologii pozwala programistom na prace z zdalnymi systemami, generowanie dynamicznych stron PDF i pobieranie danych przez połączenia sieciowe, jednoczesnie zwiększając produktywnosc i skalowalnosc w ich programach.
How to Use HtmlAgilityPack in C
- Utworz nowy projekt C#.
- Zainstaluj biblioteke HtmlAgilityPack.
- Zaimportuj przestrzen nazw. Utworz obiekt.
- Zaimportuj dane z URL-a i zanalizuj HTML.
- Pobierz wymagane dane i usun obiekt.
Wprowadzenie do HtmlAgilityPack
HTML Agility Pack to wszechstronna i potężna biblioteka do analizy HTML dla programistów .NET. Dzięki bogatej kolekcji API, deweloperzy mogą łatwo nawigowac, zmieniac i pobierac dane z dokumentów HTML. HTML Agility Pack ułatwia prace z zawartościa HTML programistom na kazdym poziomie zaawansowania.
Zdolnosc HTML Agility Pack do łagodnego zarządzania nieprawidłowo zorganizowanym lub wadliwym HTML-em jest tym, co czyni go wyjątkówym. Jest idealny do operacji skrobania online, gdzie jakosc znacznikow HTML może sie roznic, poniewaz używa elastycznego algorytmu analizy, który może przetwarzać nawet najbardziej zle skonstruowany HTML.
Funkcje HtmlAgilityPack
Analiza HTML
Dzięki potężnym funkcjom analizy HTML oferowanym przez HTML Agility Pack, programisci mogą ladawac dokumenty HTML z różnych zrodel, w tym plików, URL-i i ciagow. Dzięki elastycznemu podejsciu do analizy, może lagodnie obsługiwac blednie sformatowany lub niepoprawny HTML, co czyni go odpowiednim do działalnosci skrobania sieciowego, gdzie jakosc znacznikow HTML może sie roznic.
Manipulacja DOM
Do eksploracji, przeglądania i pracy z struktura modelu obiektu dokumentu HTML (DOM), HAP oferuje przyjazne dla użytkownika API. Elementy HTML, atrybuty i wezly tekstowe mogą być programowo dodawane, usuwane lub modyfikowane przez deweloperow, pozwalając na dynamiczna manipulacje zawartościa HTML.
Obsluga XPath i LINQ
Do wybierania i zapytan komponentow HTML, HTML Agility Pack obsługuje LINQ (Language Integrated Query) oraz wyszukiwania wedlug skladni XPath. Zapytania wyrazenia XPath oferuja silna i łatwa w zrozumieniu skladnie do wyboru elementow w dokumencie HTML w zależności od ich atrybutow, tagow lub hierarchii. Dla deweloperow przyzwyczajonych do pracy z LINQ w C#, zapytania LINQ oferuja znana skladnie zapytan, która ułatwia gladkie zintegrowanie z innymi komponentami .NET.
Rozpoczynanie pracy z HtmlAgilityPack
Konfiguracja HtmlAgilityPack w projektach C
Biblioteka bazowa HtmlAgility jest dostarczana w jednym pakiecie, ktory powinien być dostępny w NuGet po jego zainstalowaniu i może być używany w projekcie C#. Oferuje parser HTML i selektory CSS z dokumentu HTML i adresow URL HTML.
Implementacja HtmlAgilityPack w konsoli i formularzach Windows
Wiele typow aplikacji C#, takich jak Windows Forms (WinForms) i Windows Console, implementuje HtmlAgilityPack. Chociaż implementacja rozni sie w zależności od frameworka, podstawowa idea pozostaje niezmienna.
Przykład HtmlAgilityPack w C
Jednym z najwazniejszych narzędzi w skrzynce narzędziowej programisty C# do nawigacji, przetwarzania i pracy z dokumentami HTML jest HTML Agility Pack (HAP). Pobieranie danych z stron HTML jest ulatwione przez przyjazne dla użytkownika API, ktore działa jak zorganizowane drzewo elementow. Przyjrzyjmy sie prostemu przykładówi kodu, aby pokazac, jak można go uzyc.
using HtmlAgilityPack;
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
var doc = web.Load("https://ironpdf.com/");
// Select specific html nodes and parse html string
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
Console.WriteLine(node.InnerText);
}
Console.ReadKey();using HtmlAgilityPack;
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
var doc = web.Load("https://ironpdf.com/");
// Select specific html nodes and parse html string
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
Console.WriteLine(node.InnerText);
}
Console.ReadKey();Imports HtmlAgilityPack
' Load HTML content from a file or URL
Private web As New HtmlWeb()
Private doc = web.Load("https://ironpdf.com/")
' Select specific html nodes and parse html string
Private nodes As HtmlNodeCollection = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']")
' Iterate through selected nodes and extract content
For Each node As HtmlNode In nodes
Console.WriteLine(node.InnerText)
Next node
Console.ReadKey()W tym przykładzie ladujemy material wezla HTML z URL za pomocą HTML Agility Pack. HTML jest następnie ładowany do var doc w celu analizy składniowej i manipulacji. Aby wyodrębnić zawartość, program najpierw identyfikuje wezel głównego dokumentu HTML, a następnie specyficznie celuje w wezly wewnątrz dokumentu za pomoca zapytan XPath. Z powyzszej modyfikacji kodu, celujemy konkretnie w elementy div z klasa product-homepage-header z ciągu danych HTML, a następnie tekst wewnętrzny kazdego wybranego wezla jest drukowany na konsoli.
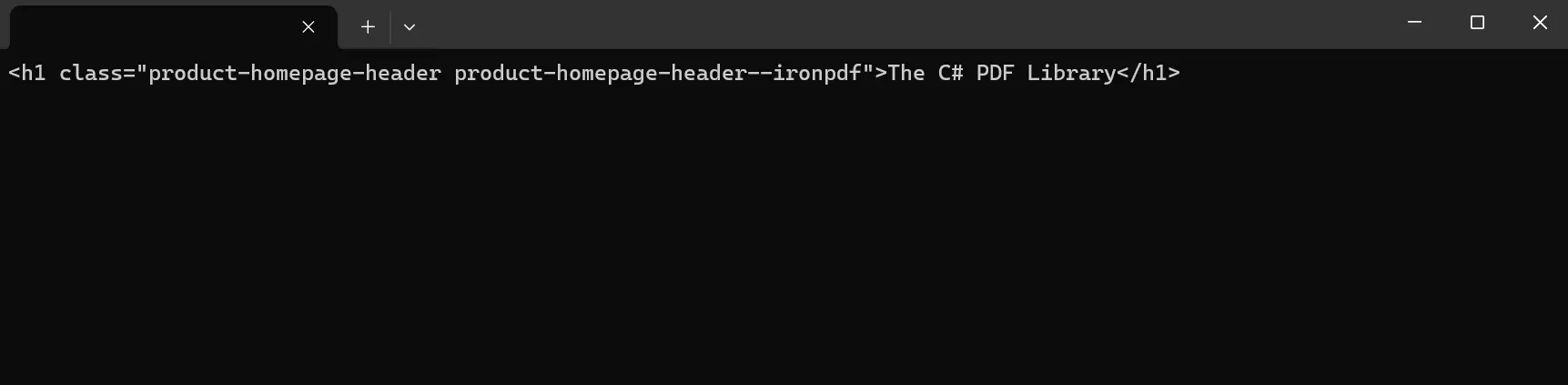
Operacje HtmlAgilityPack
Transformacja HTML
Programisci mogą wykonywać kilka przeksztalcen i manipulacji tekstow HTML za pomoca HTML Agility Pack. Obejmuje to operacje takie jak dodawanie, usuwanie lub zmiana wezlow tekstowych, elementow i atrybutow, a także reorganizowanie hierarchii DOM dokumentu HTML.
Rozszerzalność
Poniewaz HAP jest przeznaczony do rozszerzania, programisci mogą dodawac nowe funkcje i zachowania, aby zwiększyć jego funkcjonalność. Korzystajac z dostarczanego API, deweloperzy mogą projektowac własne parsery HTML, filtry lub manipulatory, aby dostosować HAP do swoich unikalnych potrzeb i przypadkow użycia.
Wydajnosc i efektywność
Duze teksty HTML mogą być dobrze obsługiwane przez algorytmy i struktury danych HTML Agility Pack, które są zoptymalizowane dla szybkości i efektywności. Zapewnia szybka i responsywna analize zawartości HTML i manipulacje, minimalizujac zużycie pamięci i obciazenie przetwarzania.
Integrating HtmlAgilityPack with IronPDF
Uzycie IronPDF z HtmlAgilityPack
Mozliwosci zarządzania dokumentami i tworzenia raportow sa nieskonczone, gdy HTML Agility Pack i IronPDF dla konwersji PDF sa polaczone. Za pomoca HTML Agility Pack do analizy HTML i dokumentacji IronPDF do konwersji PDF, programisci mogą zautomatyzowac tworzenie dokumentów PDF z dynamicznej zawartości online bez zadnych trudności.
Zainstaluj IronPDF
- Uruchom projekt Visual Studio.
- Wybierz "Narzędzia" > "Menedżer pakietów NuGet" > "Konsola Menedżera pakietów".
- Wprowadz to polecenie do konsoli Menedżera pakietów:
Install-Package IronPdf
- Alternatywnie, można użyć Menedżera Pakietów NuGet dla Rozwiązań, aby zainstalować IronPDF.
-
Można przeglądać wyniki wyszukiwania pakietu IronPDF, wybrać go, a następnie kliknąć przycisk "Zainstaluj". Visual Studio zajmie się instalacją i pobieraniem za Ciebie.
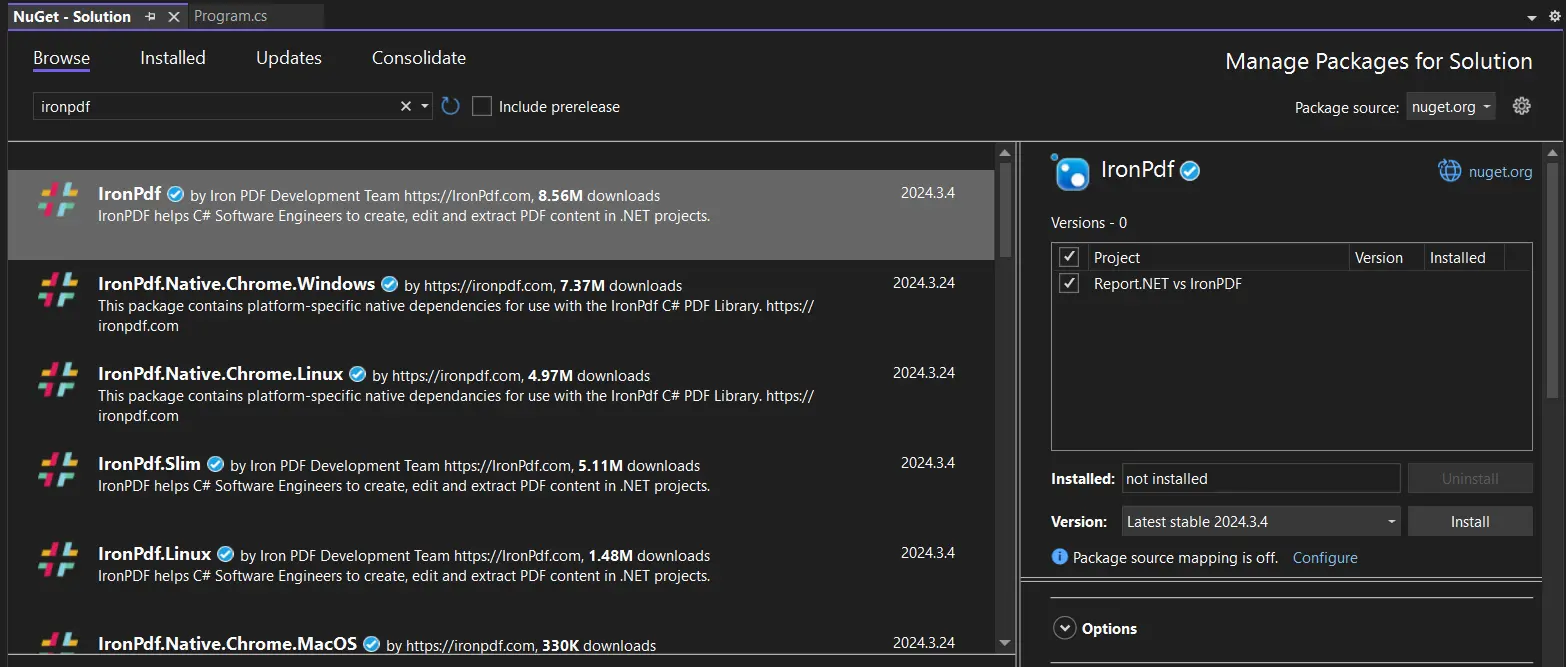
- NuGet zainstaluje pakiet IronPDF i wszelkie wymagane zależności dla twojego projektu.
- Po zainstalowaniu IronPDF można uzyc go dla swojego projektu.
Zainstaluj za pośrednictwem strony internetowej NuGet
Aby dowiedzieć się więcej o funkcjach, kompatybilności i innych możliwościach pobierania IronPDF, zobacz jego Informacje o pakiecie NuGet IronPDF na stronie NuGet.
Wykorzystaj bibliotekę DLL do instalacji
Alternatywnie można użyć pliku DLL IronPDF, aby zintegrować go bezpośrednio z projektem. Kliknij ten Pobierz DLL IronPDF, aby uzyskać plik ZIP zawierający DLL. Po rozpakowaniu, włącz DLL do swojego projektu.
Wdrażanie logiki
Poprzez integracje funkcji obu bibliotek, HTML Agility Pack (HAP) i IronPDF można zaimplementowac w C#, aby odczytywać informacje HTML i tworzyć dokumenty PDF na bierzaco. Kroki implementacji sa wymienione poniżej, wraz z przykładówym kodem, ktory przechodzi przez kazdy krok:
- Laduj zawartość HTML za pomoca HTML Agility Pack: Uzyj HTML Agility Pack, aby załadować material HTML z zrodla, takiego jak plik, ciag lub URL. W tej fazie HTML dokumentówany jest i tworzony jest obiekt dokumentu HTML, ktorym można manipulowac.
- Wyodrebnij Pozadana Zawartosc: Uzyj HTML Agility Pack w połączeniu z zapytaniami XPath lub LINQ, aby wybrac i wyodrębnij konkretna zawartość z dokumentu HTML. To może obejmowac wybieranie elementow wedlug ich właściwości, tagow lub struktury hierarchicznej.
- Konwersja HTML do PDF za pomoca IronPDF: Uzyj IronPDF, aby utworzyć dokument PDF z pobranej zawartości HTML. IronPDF łatwo konwertuje material HTML do formatu PDF, zachowujac styl i uklad.
- Opcjonalnie: Dostosowanie wygladu PDF: Uzyj IronPDF, aby dodac nagłówki, stopki, numerowanie stron i inne dynamiczne komponenty, aby dostosować wynikowe wyglad PDF w zależności od potrzeb. Ten krok poprawia wyglad i uzytecznosc wynikowego dokumentu PDF.
- Zapisz lub Wyslij Dokument PDF: Utworzony dokument PDF może być przesylany bezpośrednio do klienta lub przeglądarki do pobrania, lub może być zapisany w pliku. IronPDF oferuje sposoby zapisania plików PDF do róznych strumieni wyjsciow.
using HtmlAgilityPack;
using IronPdf;
using System;
using System.Text;
class Program
{
static void Main()
{
StringBuilder htmlContent = new StringBuilder();
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://ironpdf.com/");
// Select specific elements using XPath or LINQ
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
htmlContent.Append(node.OuterHtml);
Console.WriteLine(node.InnerText);
}
// Convert HTML content to PDF using IronPDF
var Renderer = new HtmlToPdf();
var PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString());
// Save PDF to file
PDF.SaveAs("output.pdf");
Console.WriteLine("PDF generated successfully!");
Console.ReadKey();
}
}using HtmlAgilityPack;
using IronPdf;
using System;
using System.Text;
class Program
{
static void Main()
{
StringBuilder htmlContent = new StringBuilder();
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://ironpdf.com/");
// Select specific elements using XPath or LINQ
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
htmlContent.Append(node.OuterHtml);
Console.WriteLine(node.InnerText);
}
// Convert HTML content to PDF using IronPDF
var Renderer = new HtmlToPdf();
var PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString());
// Save PDF to file
PDF.SaveAs("output.pdf");
Console.WriteLine("PDF generated successfully!");
Console.ReadKey();
}
}Imports HtmlAgilityPack
Imports IronPdf
Imports System
Imports System.Text
Friend Class Program
Shared Sub Main()
Dim htmlContent As New StringBuilder()
' Load HTML content from a file or URL
Dim web As New HtmlWeb()
Dim doc As HtmlDocument = web.Load("https://ironpdf.com/")
' Select specific elements using XPath or LINQ
Dim nodes As HtmlNodeCollection = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']")
' Iterate through selected nodes and extract content
For Each node As HtmlNode In nodes
htmlContent.Append(node.OuterHtml)
Console.WriteLine(node.InnerText)
Next node
' Convert HTML content to PDF using IronPDF
Dim Renderer = New HtmlToPdf()
Dim PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString())
' Save PDF to file
PDF.SaveAs("output.pdf")
Console.WriteLine("PDF generated successfully!")
Console.ReadKey()
End Sub
End ClassOdwiedz Uzycie IronPDF do Konwersji, aby dowiedziec sie więcej o przykładzie kodu.
Poniżej przedstawiono wynik działania:
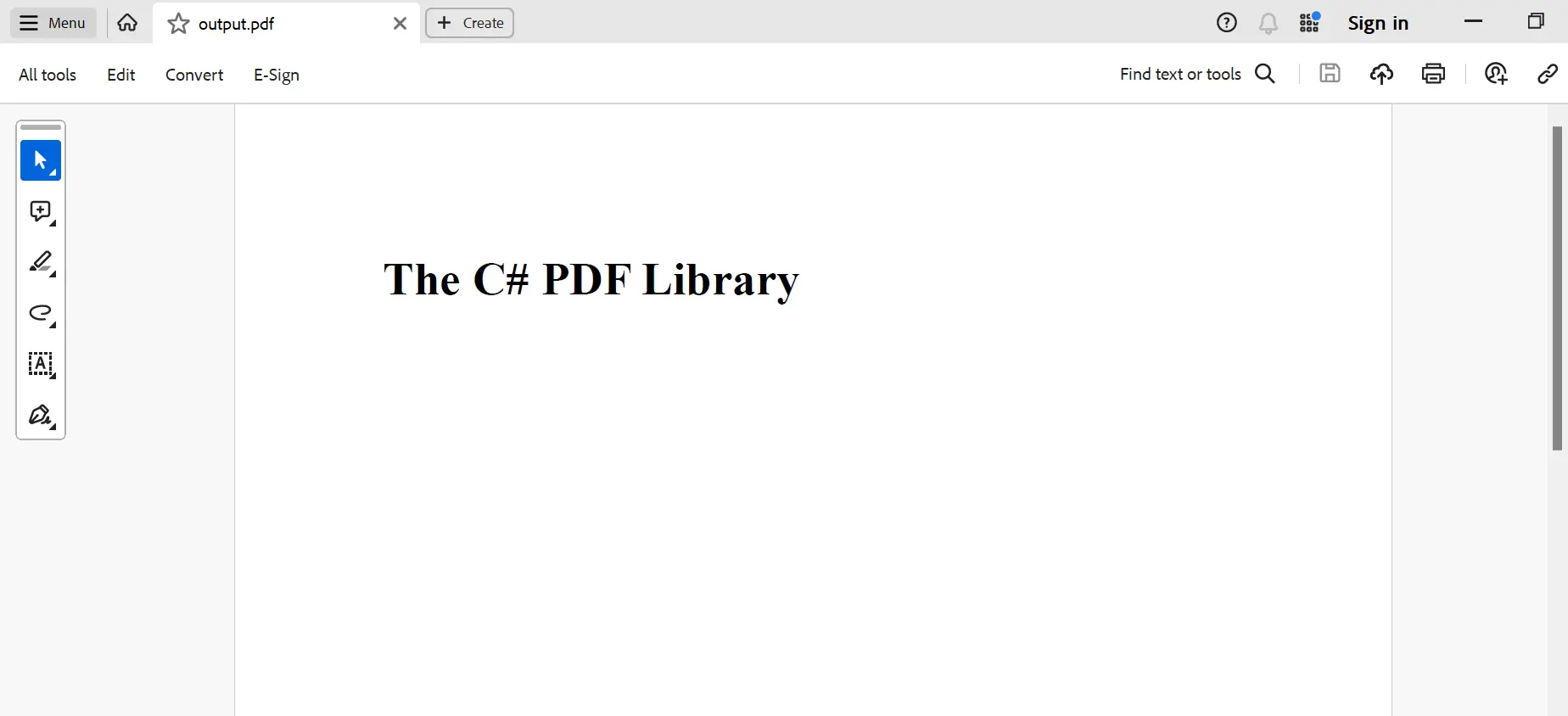
Wnioski
Niezaleznie od tego, czy analizujesz dane HTML, czy tworzysz raporty PDF, deweloperzy mogą łatwo zarzadzać i zmieniac zawartość dokumentów dzięki plynnemu zintegrowaniu HTML Agility Pack i IronPDF w C#. Deweloperzy mogą łatwo i dokladnie zautomatyzowac operacje powiazane z dokumentami, łącząc funkcje produkcji PDF z IronPDF z możliwościami analizy HTML Agility Pack. Połączenie tych dwóch bibliotek zapewnia silne rozwiązanie do zarządzania dokumentami w C#, niezależnie od tego, czy budujesz dynamiczne raporty czy pobierasz dane ze stron internetowych.
Licencja wieczysta, rok utrzymania oprogramowania i aktualizacja biblioteki są zawarte w pakiecie $999 Lite. IronPDF oferuje bezpłatną licencję z ograniczeniami czasowymi i dotyczącymi redystrybucji. Podczas okresu próbnego, użytkownicy mogą ocenias rozwiązanie bez widocznego znaku wodnego. Przejdz do informacji o licencjonowaniu IronPDF, aby dowiedziec sie więcej o kosztach i licencji.
Dowiedz sie więcej o bibliotekach Iron Software.
Często Zadawane Pytania
Jak mogę przekonwertować HTML na PDF w języku C#?
Możesz użyć metody RenderHtmlAsPdf biblioteki IronPDF do konwersji ciągów HTML na pliki PDF. Możesz również konwertować pliki HTML na pliki PDF za pomocą metody RenderHtmlFileAsPdf.
Jaki jest cel używania HtmlAgilityPack w projektach C#?
HtmlAgilityPack jest używany w projektach C# do analizowania i manipulowania dokumentami HTML. Potrafi obsługiwać źle sformatowany kod HTML, co czyni go idealnym rozwiązaniem do zadań związanych z web scrapingiem i ekstrakcją danych.
Jak skonfigurować HtmlAgilityPack w aplikacji C#?
Aby skonfigurować HtmlAgilityPack, zainstaluj go za pomocą menedżera pakietów NuGet w Visual Studio. Po instalacji możesz zaimportować niezbędne przestrzenie nazw i rozpocząć parsowanie treści HTML w swojej aplikacji.
Czy IronPDF i HtmlAgilityPack mogą być używane razem do tworzenia dokumentów?
Tak, IronPDF i HtmlAgilityPack można połączyć w celu tworzenia dynamicznych dokumentów PDF na podstawie treści HTML. HtmlAgilityPack wyodrębnia i przetwarza dane HTML, które następnie można przekonwertować do formatu PDF za pomocą IronPDF.
Jakie są główne funkcje IronPDF for .NET dla programistów .NET?
IronPDF oferuje takie funkcje, jak konwersja HTML do PDF, scałanie plików PDF oraz dodawanie tekstu lub obrazów do plików PDF. Obsługuje szeroki zakres funkcji umożliwiających solidne zarządzanie dokumentami PDF w aplikacjach .NET.
W jaki sposób HtmlAgilityPack może pomóc w pozyskiwaniu danych ze stron internetowych?
HtmlAgilityPack pozwala programistom na ładowanie dokumentów HTML oraz korzystanie z zapytań XPath lub LINQ w celu nawigacji i wyodrębniania danych na podstawie określonych węzłów lub atrybutów, ułatwiając ekstrakcję danych z sieci.
Jakie są zalety integracji biblioteki PDF z HtmlAgilityPack?
Integracja IronPDF z HtmlAgilityPack usprawnia automatyzację dokumentów, umożliwiając konwersję dynamicznej zawartości HTML na raporty PDF, co usprawnia generowanie dokumentów w aplikacjach .NET.
Czy można używać IronPDF w aplikacjach konsolowych?
Tak, IronPDF można wdrożyć w różnych typach aplikacji C#, w tym w aplikacjach konsolowych Windows, co pozwala na wszechstronne przetwarzanie dokumentów i generowanie plików PDF.
Jakie operacje HTML można wykonywać za pomocą HtmlAgilityPack?
HtmlAgilityPack obsługuje operacje takie jak dodawanie, usuwanie lub modyfikowanie węzłów i elementów HTML oraz reorganizację struktury DOM, co czyni go wszechstronnym narzędziem do manipulacji dokumentami HTML.
Czy IronPDF oferuje bezpłatną wersję próbną dla programistów?
IronPDF oferuje bezpłatną licencję z pewnymi ograniczeniami, umożliwiającą programistom ocenę biblioteki bez znaku wodnego w okresie próbnym, co daje możliwość przetestowania jej funkcji przed zakupem.














