
Html Agility Pack C# (개발자를 위한 작동 방식)
C# 개발 세계에서 문서 콘텐츠를 동적으로 관리하고 조작해야 하는 필요성이 널리 퍼져 있습니다. 개발자는 보통 PDF 보고서 작성 및 웹 페이지에서 데이터 추출과 같은 작업을 자동화하기 위해 견고한 라이브러리에 의존합니다. 이 문서에서는 IronPDF와 HTML Agility Pack의 간단한 통합을 C#에서 탐구하고 이러한 라이브러리를 사용하여 PDF 문서를 쉽게 만들고 HTML 텍스트를 읽는 방법을 코드 예제로 보여줍니다.
IronPDF는 PDF 파일 작업을 위한 기능이 풍부한 .NET 라이브러리입니다. IronPDF는 개발자가 HTML 콘텐츠, URL 또는 Raw 데이터를 기반으로 동적으로 PDF 파일을 생성할 수 있게 하여 문서 작성, 보고서 생성 및 데이터 시각화를 위한 가치 있는 도구로 작용합니다.
이 게시물에서는 .NET 애플리케이션에서 문서 생성을 간소화하기 위해 IronPDF와 HTML Agility Pack을 연결하는 방법을 살펴보겠습니다. 이러한 기술을 결합하면 프로그래머가 원격 시스템과 협력하고 동적 PDF 페이지를 생성하며 네트워크 연결성을 통해 데이터를 얻을 수 있게 하여 프로그램의 생산성과 확장성을 높입니다.
How to Use HtmlAgilityPack in C
- 새로운 C# 프로젝트를 생성합니다.
- HtmlAgilityPack 라이브러리를 설치합니다.
- 네임스페이스를 가져옵니다. 객체를 생성합니다.
- URL에서 데이터를 가져와 HTML을 구문 분석합니다.
- 필요한 데이터를 얻고 객체를 폐기합니다.
HtmlAgilityPack 소개
HTML Agility Pack는 .NET 개발자를 위한 다재다능하고 강력한 HTML 구문 분석 라이브러리입니다. 광범위한 API 컬렉션을 통해 개발자는 HTML 문서에서 데이터를 쉽고 효율적으로 탐색, 수정, 추출할 수 있습니다. HTML Agility Pack은 모든 개발자가 경험 수준에 관계없이 프로그래밍 방식으로 HTML 콘텐츠 작업을 더욱 쉽게 만듭니다.
HTML Agility Pack의 중요한 점은 잘못 구성되거나 결함이 있는 HTML을 부드럽게 처리할 수 있는 능력입니다. 품질이 다른 HTML 마크업을 사용하는 웹 스크래핑 작업에 적합하며, 잘못된 형식의 HTML을 파싱할 수 있는 유연한 구문 분석 알고리즘을 사용합니다.
HtmlAgilityPack의 기능
HTML 구문 분석
HTML Agility Pack이 제공하는 강력한 HTML 구문 분석 기능을 통해 개발자는 파일, URL, 문자열을 포함한 다양한 소스에서 HTML 문서를 로드할 수 있습니다. 관대한 구문 분석 방법을 통해 잘못된 형식이나 오류가 있는 HTML을 부드럽게 처리할 수 있어, HTML 마크업 품질이 다를 수 있는 웹 스크래핑 작업에 적합합니다.
DOM 조작
HAP는 HTML 문서 객체 모델(HTML Document Object Model, DOM) 구조를 탐색하고 브라우징하며 작업하기 위한 사용자 친화적인 API를 제공합니다. HTML 요소, 속성 및 텍스트 노드는 개발자가 프로그래밍 방식으로 추가, 제거, 수정할 수 있으며, 이를 통해 동적인 HTML 콘텐츠 조작이 가능합니다.
XPath 및 LINQ 지원
HTML Agility Pack은 HTML 구성 요소를 선택하고 쿼리하기 위해 LINQ(통합 언어 쿼리)와 XPath 구문 검색을 지원합니다. XPath 표현식 쿼리는 속성, 태그 또는 계층 구조에 따라 HTML 문서에서 항목을 선택하기 위한 강력하고 이해하기 쉬운 구문을 제공합니다. LINQ를 사용하여 C#에서 작업하는 개발자를 위해 LINQ 쿼리는 다른 .NET 구성 요소와의 원활한 통합을 촉진하는 친숙한 쿼리 구문을 제공합니다.
HtmlAgilityPack 시작하기
C# 프로젝트에서 HtmlAgilityPack 설정하기
HtmlAgility 베이스 클래스 라이브러리는 단일 번들 패키지로 제공되며, NuGet을 통해 설치하여 C# 프로젝트에서 사용할 수 있습니다. HTML 문서 및 HTML URL에서 HTML 구문 분석기와 CSS 선택기를 제공합니다.
Windows 콘솔 및 폼에서 HtmlAgilityPack 구현
Windows Forms(WinForms) 및 Windows Console과 같은 여러 C# 애플리케이션 유형은 HtmlAgilityPack을 구현합니다. 프레임워크마다 구현이 다르지만 기본 아이디어는 동일하게 유지됩니다.
HtmlAgilityPack C# 예제
HTML 문서를 탐색, 처리, 작업하는 C# 개발자의 도구 상자에서 가장 중요한 도구 중 하나는 HTML Agility Pack (HAP)입니다. 사용자 친화적인 API를 통해 HTML 페이지에서 데이터 추출이 더 쉬워지며, 이는 요소들의 조직화된 트리처럼 작동합니다. 사용법을 보여주는 간단한 코드 예제를 살펴보겠습니다.
using HtmlAgilityPack;
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
var doc = web.Load("https://ironpdf.com/");
// Select specific html nodes and parse html string
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
Console.WriteLine(node.InnerText);
}
Console.ReadKey();using HtmlAgilityPack;
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
var doc = web.Load("https://ironpdf.com/");
// Select specific html nodes and parse html string
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
Console.WriteLine(node.InnerText);
}
Console.ReadKey();Imports HtmlAgilityPack
' Load HTML content from a file or URL
Private web As New HtmlWeb()
Private doc = web.Load("https://ironpdf.com/")
' Select specific html nodes and parse html string
Private nodes As HtmlNodeCollection = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']")
' Iterate through selected nodes and extract content
For Each node As HtmlNode In nodes
Console.WriteLine(node.InnerText)
Next node
Console.ReadKey()이 예제에서는 HTML Agility Pack을 사용하여 URL에서 HTML 노드 데이터를 로드합니다. 그런 다음 HTML이 var doc 에 로드되어 구문 분석 및 조작을 위한 준비가 됩니다. 콘텐츠를 추출하기 위해 프로그램은 먼저 HTML 문서의 루트 노드를 식별하고, 이후 XPath 쿼리를 사용하여 문서 내의 특정 노드를 타겟으로 지정합니다. 위 코드에서 우리는 문자열 HTML 데이터에서 product-homepage-header 클래스가 있는 div 요소를 선택하고, 각 선택된 노드의 내부 텍스트를 콘솔에 출력합니다.
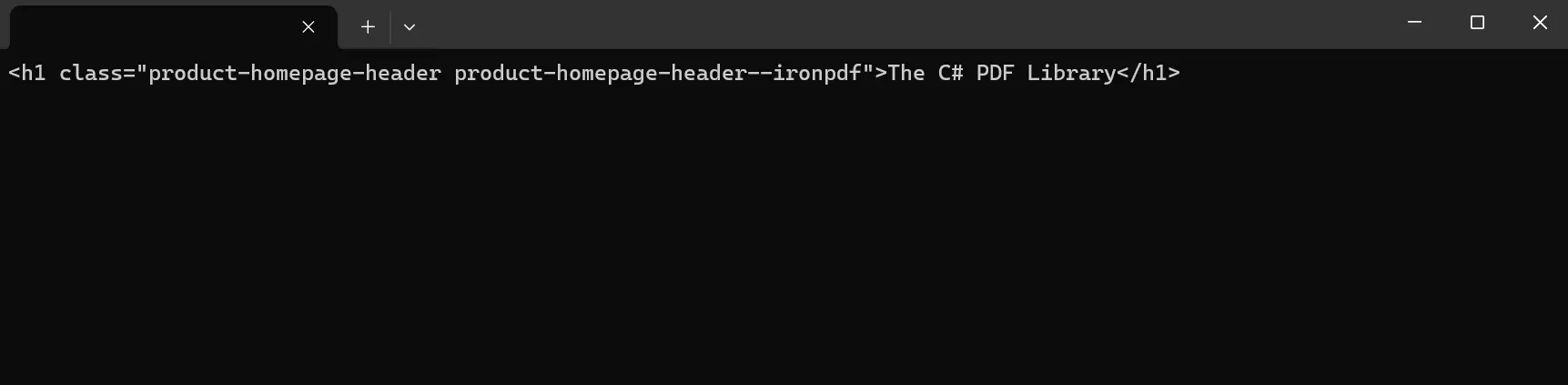
HtmlAgilityPack 작업
HTML 변환
개발자는 HTML Agility Pack을 사용하여 HTML 텍스트에 여러 변환과 조작을 수행할 수 있습니다. 이것은 HTML 문서의 DOM 계층 구조를 재구성하는 것 외에도 텍스트 노드, 요소 및 속성을 추가, 삭제하거나 변경하는 작업을 포함합니다.
확장성
HAP는 확장 가능하도록 설계되어 있어, 프로그래머는 기능과 동작을 추가하여 기능을 확장할 수 있습니다. 제공된 API를 사용하여 개발자는자신의 HTML 구문 분석기, 필터 또는 조작기를 설계하여 HAP를 고유의 필요와 사용 사례에 맞게 사용자 지정할 수 있습니다.
성능 및 효율성
HTML Agility Pack의 알고리즘과 데이터 구조는 빠르고 효율적이며, 대형 HTML 텍스트를 잘 처리할 수 있도록 튜닝되어 있습니다. 이로 인해 메모리 사용량과 처리 오버헤드를 줄이고, 빠르고 응답성이 우수한 HTML 콘텐츠 구문 분석 및 조작을 보장합니다.
HtmlAgilityPack을 IronPDF와 통합하기
IronPDF와 HtmlAgilityPack 사용
HTML Agility Pack과 IronPDF for PDF Conversion을 결합하면 문서 관리 및 보고서 생성의 가능성은 무한합니다. HTML 구문 분석을 위해 HTML Agility Pack을 사용하고 PDF 변환을 위해 IronPDF Documentation를 사용하여, 개발자는 다이내믹한 온라인 자료에서 PDF 문서 생성을 손쉽게 자동화할 수 있습니다.
IronPDF 설치
- Visual Studio 프로젝트를 실행합니다.
- "도구" > "NuGet 패키지 관리자" > "패키지 관리자 콘솔"을 선택합니다.
- 이 명령을 패키지 관리자 콘솔에 입력합니다:
Install-Package IronPdf
- 대안으로, 솔루션용 NuGet 패키지 관리자를 사용하여 IronPDF를 설치할 수 있습니다.
-
IronPDF 패키지의 검색 결과를 찾아보고, 선택한 후 "설치" 버튼을 클릭할 수 있습니다. Visual Studio가 설치와 다운로드를 처리해 줄 것입니다.
- NuGet이 프로젝트에 필요한 IronPDF 패키지 및 모든 종속성을 설치할 것입니다.
- 설치 후 프로젝트에 IronPDF를 사용할 수 있습니다.
NuGet 웹사이트를 통해 설치
IronPDF의 기능, 호환성 및 기타 다운로드 선택에 대해 더 알아보려면 NuGet 웹사이트에서 IronPDF NuGet 패키지 정보를 참조하세요.
DLL을 사용하여 설치
다른 방법으로, IronPDF의 DLL 파일을 프로젝트에 직접 통합할 수 있습니다. DLL이 포함된 ZIP 파일을 얻으려면 IronPDF DLL 다운로드를 클릭하세요. 압축을 풀고, DLL을 프로젝트에 통합하세요.
논리 구현
HTML Agility Pack (HAP)과 IronPDF의 기능을 통합하여 C#에서 HTML 정보를 읽고 PDF 문서를 실시간으로 생성할 수 있습니다. 구현 단계는 아래에 나열되어 있으며, 각 단계를 설명하는 샘플 코드도 있습니다:
- HTML Agility Pack를 사용하여 HTML 콘텐츠 로드하기: 파일, 문자열, 또는 URL과 같은 소스에서 HTML 자료를 로드하려면 HTML Agility Pack를 사용합니다. 이 단계에서 HTML 문서가 구문 분석되고 조작 가능한 HTML 문서 객체가 생성됩니다.
- 원하는 콘텐츠 추출: HTML 문서에서 특정 콘텐츠를 선택하고 추출하려면 XPath 또는 LINQ 쿼리와 함께 HTML Agility Pack를 사용합니다. 이것은 요소를 속성, 태그 또는 계층적 구조에 따라 선택하는 경우를 포함할 수 있습니다.
- IronPDF를 사용하여 HTML을 PDF로 변환: IronPDF를 사용하여 가져온 HTML 콘텐츠에서 PDF 문서를 생성합니다. IronPDF는 스타일과 레이아웃을 유지하면서 HTML 자료를 PDF 형식으로 쉽게 변환할 수 있습니다.
- 선택 사항: PDF 출력 맞춤 설정: 필요에 따라 PDF 출력에 헤더, 푸터, 페이지 번호 매기기 및 기타 동적 구성 요소를 추가하려면 IronPDF를 사용하세요. 이 단계는 결과 PDF 문서의 외관과 사용성을 향상시킵니다.
- PDF 문서 저장 또는 스트리밍: 생성된 PDF 문서를 다운로드를 위해 클라이언트나 브라우저로 바로 스트리밍할 수 있으며, 파일로 저장할 수도 있습니다. IronPDF는 서로 다른 출력 스트림에 PDF 파일을 저장할 방법들을 제공합니다.
using HtmlAgilityPack;
using IronPdf;
using System;
using System.Text;
class Program
{
static void Main()
{
StringBuilder htmlContent = new StringBuilder();
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://ironpdf.com/");
// Select specific elements using XPath or LINQ
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
htmlContent.Append(node.OuterHtml);
Console.WriteLine(node.InnerText);
}
// Convert HTML content to PDF using IronPDF
var Renderer = new HtmlToPdf();
var PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString());
// Save PDF to file
PDF.SaveAs("output.pdf");
Console.WriteLine("PDF generated successfully!");
Console.ReadKey();
}
}using HtmlAgilityPack;
using IronPdf;
using System;
using System.Text;
class Program
{
static void Main()
{
StringBuilder htmlContent = new StringBuilder();
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://ironpdf.com/");
// Select specific elements using XPath or LINQ
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
htmlContent.Append(node.OuterHtml);
Console.WriteLine(node.InnerText);
}
// Convert HTML content to PDF using IronPDF
var Renderer = new HtmlToPdf();
var PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString());
// Save PDF to file
PDF.SaveAs("output.pdf");
Console.WriteLine("PDF generated successfully!");
Console.ReadKey();
}
}Imports HtmlAgilityPack
Imports IronPdf
Imports System
Imports System.Text
Friend Class Program
Shared Sub Main()
Dim htmlContent As New StringBuilder()
' Load HTML content from a file or URL
Dim web As New HtmlWeb()
Dim doc As HtmlDocument = web.Load("https://ironpdf.com/")
' Select specific elements using XPath or LINQ
Dim nodes As HtmlNodeCollection = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']")
' Iterate through selected nodes and extract content
For Each node As HtmlNode In nodes
htmlContent.Append(node.OuterHtml)
Console.WriteLine(node.InnerText)
Next node
' Convert HTML content to PDF using IronPDF
Dim Renderer = New HtmlToPdf()
Dim PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString())
' Save PDF to file
PDF.SaveAs("output.pdf")
Console.WriteLine("PDF generated successfully!")
Console.ReadKey()
End Sub
End ClassIronPDF를 사용하여 변환에 대한 코드 예제를 확인하세요.
실행 출력은 아래에 표시됩니다:
결론
HTML Agility Pack와 IronPDF의 매끄러운 통합 덕분에 개발자는 HTML 데이터를 구문 분석하거나 PDF 보고서를 생성할 때 쉽게 문서 자료를 관리하고 수정할 수 있습니다. 개발자는 IronPDF의 PDF 생성 기능과 HTML Agility Pack의 구문 분석 기능을 결합하여 문서와 관련된 작업을 쉽고 정확하게 자동화할 수 있습니다. 이 두 라이브러리의 결합은 동적 보고서를 생성하든 웹 페이지에서 데이터를 추출하든 강력한 C# 문서 관리 솔루션을 제공합니다.
영구 라이선스, 1년간의 소프트웨어 유지 관리, 라이브러리 업그레이드가 모두 $999 Lite 번들에 포함되어 있습니다. IronPDF 시간적 및 재배포 제한이 있는 무료 라이선스를 제공합니다. 체험판 동안 사용자는 워터마크 없이 솔루션을 평가할 수 있습니다. IronPDF의 라이선스 정보를 방문하여 비용과 라이선스에 대해 더 알아보세요.
Iron Software 라이브러리에 대해 더 알아보세요.
자주 묻는 질문
C#에서 HTML을 PDF로 변환하는 방법은 무엇인가요?
IronPDF의 RenderHtmlAsPdf 메서드를 사용하여 HTML 문자열을 PDF로 변환할 수 있습니다. 또한 RenderHtmlFileAsPdf 사용하여 HTML 파일을 PDF로 변환할 수도 있습니다.
C# 프로젝트에서 HtmlAgilityPack을 사용하는 목적은 무엇입니까?
HtmlAgilityPack은 C# 프로젝트에서 HTML 문서를 구문 분석하고 조작하기 위해 사용됩니다. 잘못된 포맷의 HTML도 처리할 수 있어 웹 스크래핑 및 데이터 추출 작업에 이상적입니다.
C# 응용 프로그램에서 HtmlAgilityPack을 설정하는 방법은 무엇입니까?
HtmlAgilityPack을 설정하려면 Visual Studio에서 NuGet Package Manager를 통해 설치하십시오. 설치 후, 필요한 네임스페이스를 가져와 응용 프로그램에서 HTML 콘텐츠를 구문 분석하기 시작할 수 있습니다.
IronPDF와 HtmlAgilityPack을 문서 생성에 함께 사용할 수 있습니까?
네, IronPDF와 HtmlAgilityPack을 결합하여 HTML 콘텐츠로부터 동적 PDF 문서를 생성할 수 있습니다. HtmlAgilityPack은 HTML 데이터를 추출하고 조작하며, 이를 IronPDF를 사용하여 PDF로 변환할 수 있습니다.
.NET 개발자를 위한 IronPDF의 주요 기능은 무엇입니까?
IronPDF는 HTML을 PDF로 변환하고, PDF를 병합하며, PDF에 텍스트 또는 이미지를 추가하는 기능을 제공합니다. .NET 응용 프로그램에서 강력한 PDF 문서 관리를 위한 다양한 기능을 지원합니다.
HtmlAgilityPack은 웹 페이지에서 데이터를 추출하는 데 어떻게 도움을 줄 수 있습니까?
HtmlAgilityPack을 사용하면 개발자가 HTML 문서를 로드하고 XPath나 LINQ 쿼리를 사용하여 특정 노드나 속성을 기반으로 탐색하고 데이터를 추출할 수 있어 웹 데이터 추출을 용이하게 합니다.
PDF 라이브러리를 HtmlAgilityPack과 통합하는 이점은 무엇입니까?
IronPDF와 HtmlAgilityPack의 통합은 동적 HTML 콘텐츠를 PDF 보고서로 변환함으로써 문서 자동화를 강화하여 .NET 응용 프로그램에서 문서 생성을 간소화합니다.
콘솔 응용 프로그램에서 IronPDF를 사용할 수 있습니까?
네, IronPDF는 Windows 콘솔 응용 프로그램을 포함한 다양한 C# 응용 프로그램 유형에서 구현 가능합니다. 이를 통해 다양한 문서 처리와 PDF 생성을 할 수 있습니다.
HtmlAgilityPack으로 수행할 수 있는 HTML 작업의 종류는 무엇입니까?
HtmlAgilityPack은 HTML 노드와 요소를 추가, 삭제, 수정하거나 DOM 구조를 재구성하는 등의 작업을 지원하여 HTML 문서 조작에 다재다능한 도구입니다.
IronPDF는 개발자를 위한 무료 체험판을 제공하나요?
IronPDF는 특정 제한이 있는 무료 라이선스를 제공하여 개발자가 평가판 기간 동안 워터마크 없이 라이브러리를 평가할 수 있는 기회를 제공하여 구매 전 기능을 테스트할 수 있게 합니다.














