
Html Agility Pack C#(开发人员如何使用)
在C#开发的世界中,动态管理和操作文档内容的需求非常广泛。 开发人员通常依赖强大的库来自动化创建PDF报告和从网页中提取数据等活动。 本文探讨了IronPDF与HTML Agility Pack在C#中的简单集成,并提供了代码示例以展示如何轻松使用这些库创建PDF文档和读取HTML文本。
IronPDF是一个功能丰富的.NET库,用于处理PDF文件。 由于IronPDF允许开发人员动态从HTML内容、URL或原始数据生成PDF文件,它在文档创建、报告和数据可视化方面是一个有价值的工具。
为了简化.NET应用程序中的文档生成,我们将在这篇文章中研究如何将IronPDF与HTML Agility Pack连接起来。结合这些技术可让程序员使用远程系统、生成动态PDF页面,并通过网络连接获取数据,同时提高程序的生产力和可扩展性。
如何在 C# 中使用 HtmlAgilityPack
- 创建一个新的C#项目。
- 安装HtmlAgilityPack库。
- 导入命名空间。 创建一个对象。
- 从URL导入数据并解析HTML。
- 获取所需的数据并处理对象。
HTML Agility Pack简介
HTML Agility Pack是一个多功能且强大的HTML解析库,供.NET开发人员使用。 借助其广泛的API集合,开发人员可以轻松浏览、修改和从HTML文档中提取数据。 HTML Agility Pack能让所有开发者,无论经验水平如何,通过编程方式更容易地处理HTML内容。
HTML Agility Pack能够温和地处理组织不良或有缺陷的HTML,使其独一无二。 由于它使用宽容的解析算法,即使最糟糕的HTML结构也能解析,因此非常适合进行在线抓取操作,在HTML标记质量可能变化的情况下。
HtmlAgilityPack功能
HTML解析
通过HTML Agility Pack提供的强大HTML解析功能,开发人员可以从多种来源,包含文件、URL和字符串,加载HTML文档。 由于其宽容的解析方式,它能优雅地处理格式不良或错误的HTML,适用于HTML标记质量变化的网页抓取活动。
DOM操作
HAP提供了一个用户友好的API,用于探索、浏览和处理HTML文档对象模型 (DOM) 结构。 开发人员可以以编程方式添加、删除或修改HTML元素、属性和文本节点,从而实现动态的HTML内容操作。
XPath和LINQ支持
HTML Agility Pack支持LINQ(语言集成查询)以及XPath语法搜索来选择和查询HTML组件。 XPath表达式查询为根据属性、标签或层级在HTML文档中选择项目提供了强大且易于理解的语法。 对于习惯于在C#中使用LINQ的开发人员,LINQ查询提供一种熟悉的查询语法,帮助与其他.NET组件实现平滑集成。
HtmlAgilityPack入门
在C#项目中设置HtmlAgilityPack
HtmlAgility基本类库是一个单一的捆绑包,可通过安装的NuGet中获得,并可用于C#项目。 它提供了一个HTML解析器和从HTML文档和HTML URL中获取CSS选择器。
在Windows控制台和窗体中使用HtmlAgilityPack
许多C#应用程序类型,如Windows窗体(WinForms)和Windows控制台,都实现了HtmlAgilityPack。 尽管每个框架的实现有所不同,但基本思想不变。
HtmlAgilityPack C#示例
HTML Agility Pack (HAP) 是C#开发者工具箱中导航、处理和操作HTML文档的重要工具之一。 其用户友好的API使得从HTML页面提取数据更加容易,该API就像是一个元素的有组织树。 让我们通过一个简单的代码示例来演示如何使用它。
using HtmlAgilityPack;
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
var doc = web.Load("https://ironpdf.com/");
// Select specific html nodes and parse html string
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
Console.WriteLine(node.InnerText);
}
Console.ReadKey();using HtmlAgilityPack;
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
var doc = web.Load("https://ironpdf.com/");
// Select specific html nodes and parse html string
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
Console.WriteLine(node.InnerText);
}
Console.ReadKey();Imports HtmlAgilityPack
' Load HTML content from a file or URL
Private web As New HtmlWeb()
Private doc = web.Load("https://ironpdf.com/")
' Select specific html nodes and parse html string
Private nodes As HtmlNodeCollection = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']")
' Iterate through selected nodes and extract content
For Each node As HtmlNode In nodes
Console.WriteLine(node.InnerText)
Next node
Console.ReadKey()在这个示例中,我们使用HTML Agility Pack从一个URL加载HTML节点素材。 然后,将 HTML 加载到 var doc 中进行解析和操作。 为了提取内容,程序首先识别HTML文档的根节点,然后使用XPath查询特别定位文档内的节点。 根据上述代码,我们从字符串HTML数据中特别选择具有类product-homepage-header的div元素,然后将每个选定节点的内部文本打印到控制台。
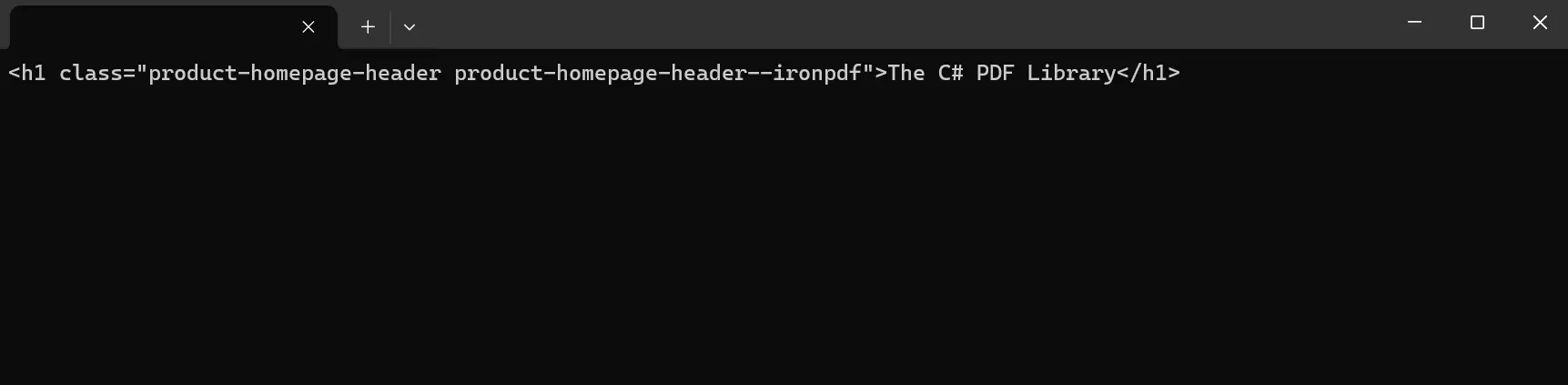
HtmlAgilityPack操作
HTML转换
开发人员可以使用HTML Agility Pack对HTML文本进行多种转换和操作。 这涵盖了诸如添加、删除或更改文本节点、元素和属性以及重新组织HTML文档的DOM层次结构等操作。
可扩展性
由于HAP旨在可扩展,程序员可以添加新功能和行为以增强其功能。 通过提供的API,开发人员可以设计自己的HTML解析器、过滤器或操纵器,以根据其特定需求和用例自定义HAP。
性能与效率
HTML Agility Pack的算法和数据结构经过优化以保证速度和效率,能够很好地处理大型HTML文本。 它通过减少内存使用和处理开销,确保快速响应的HTML内容解析和操作。
将HtmlAgilityPack与IronPDF集成
使用IronPDF和HtmlAgilityPack
当HTML Agility Pack与用于PDF转换的IronPDF结合时,文档管理和报表创建的可能性是无穷的。 通过使用HTML Agility Pack进行HTML解析和IronPDF文档进行PDF转换,开发人员可以轻松实现动态在线素材创建的PDF文档。
安装 IronPDF
- 启动Visual Studio项目。
- 选择"工具" > "NuGet包管理器" > "包管理控制台"。
- 在包管理控制台中输入以下命令:
Install-Package IronPdf
- 作为替代,您可以使用解决方案的NuGet包管理器来安装IronPDF。
- 搜索IronPDF包的搜索结果可以被浏览、选择,然后单击"安装"按钮。 Visual Studio将为您处理安装和下载。
- NuGet将为您的项目安装IronPDF包和所需的依赖项。
- 安装后,IronPDF即可用于您的项目。
通过NuGet网站安装
要了解IronPDF的功能、兼容性和其他下载选项,请访问其在NuGet网站上的<IronPDF NuGet包信息。
使用DLL安装
作为替代,您可以使用IronPDF的DLL文件将其直接集成到您的项目中。 点击此IronPDF DLL下载以获取包含DLL的ZIP文件。 解压后,将DLL集成到您的项目中。
实施逻辑
通过结合两个库的功能,HTML Agility Pack (HAP)和IronPDF可以在C#中进行实施,以实时读取HTML信息并生成PDF文档。 下面列出了实施步骤,并附有一个样例代码来逐步演示每个步骤:
1.使用 HTML Agility Pack 加载 HTML 内容:要从文件、字符串或 URL 等源加载 HTML 材料,请使用 HTML Agility Pack。 在此步骤中,HTML文档被解析并创建一个可操作的HTML文档对象。
- 提取所需内容:结合XPath或LINQ查询,使用HTML Agility Pack从HTML文档中选择和提取特定内容。 这可能涉及根据它们的属性、标签或层级结构来选择元素。 3.使用 IronPDF 将 HTML 转换为 PDF:要从检索到的 HTML 内容创建 PDF 文档,请使用 IronPDF。 IronPDF可轻松将HTML素材转换为PDF格式,同时保持样式和布局。
- 可选:自定义PDF输出:使用IronPDF添加标题、页脚、页码和其他动态元素,根据需要自定义PDF输出。 这一步提高了生成的PDF文档的外观和可用性。 5.保存或流式传输 PDF 文档:创建的 PDF 文档可以直接流式传输到客户端或浏览器以供下载,也可以保存到文件。IronPDF 提供多种将 PDF 文件保存到不同输出流的方式。
using HtmlAgilityPack;
using IronPdf;
using System;
using System.Text;
class Program
{
static void Main()
{
StringBuilder htmlContent = new StringBuilder();
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://ironpdf.com/");
// Select specific elements using XPath or LINQ
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
htmlContent.Append(node.OuterHtml);
Console.WriteLine(node.InnerText);
}
// Convert HTML content to PDF using IronPDF
var Renderer = new HtmlToPdf();
var PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString());
// Save PDF to file
PDF.SaveAs("output.pdf");
Console.WriteLine("PDF generated successfully!");
Console.ReadKey();
}
}using HtmlAgilityPack;
using IronPdf;
using System;
using System.Text;
class Program
{
static void Main()
{
StringBuilder htmlContent = new StringBuilder();
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://ironpdf.com/");
// Select specific elements using XPath or LINQ
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
htmlContent.Append(node.OuterHtml);
Console.WriteLine(node.InnerText);
}
// Convert HTML content to PDF using IronPDF
var Renderer = new HtmlToPdf();
var PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString());
// Save PDF to file
PDF.SaveAs("output.pdf");
Console.WriteLine("PDF generated successfully!");
Console.ReadKey();
}
}Imports HtmlAgilityPack
Imports IronPdf
Imports System
Imports System.Text
Friend Class Program
Shared Sub Main()
Dim htmlContent As New StringBuilder()
' Load HTML content from a file or URL
Dim web As New HtmlWeb()
Dim doc As HtmlDocument = web.Load("https://ironpdf.com/")
' Select specific elements using XPath or LINQ
Dim nodes As HtmlNodeCollection = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']")
' Iterate through selected nodes and extract content
For Each node As HtmlNode In nodes
htmlContent.Append(node.OuterHtml)
Console.WriteLine(node.InnerText)
Next node
' Convert HTML content to PDF using IronPDF
Dim Renderer = New HtmlToPdf()
Dim PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString())
' Save PDF to file
PDF.SaveAs("output.pdf")
Console.WriteLine("PDF generated successfully!")
Console.ReadKey()
End Sub
End Class访问利用IronPDF进行转换了解代码示例。
执行输出如下所示:
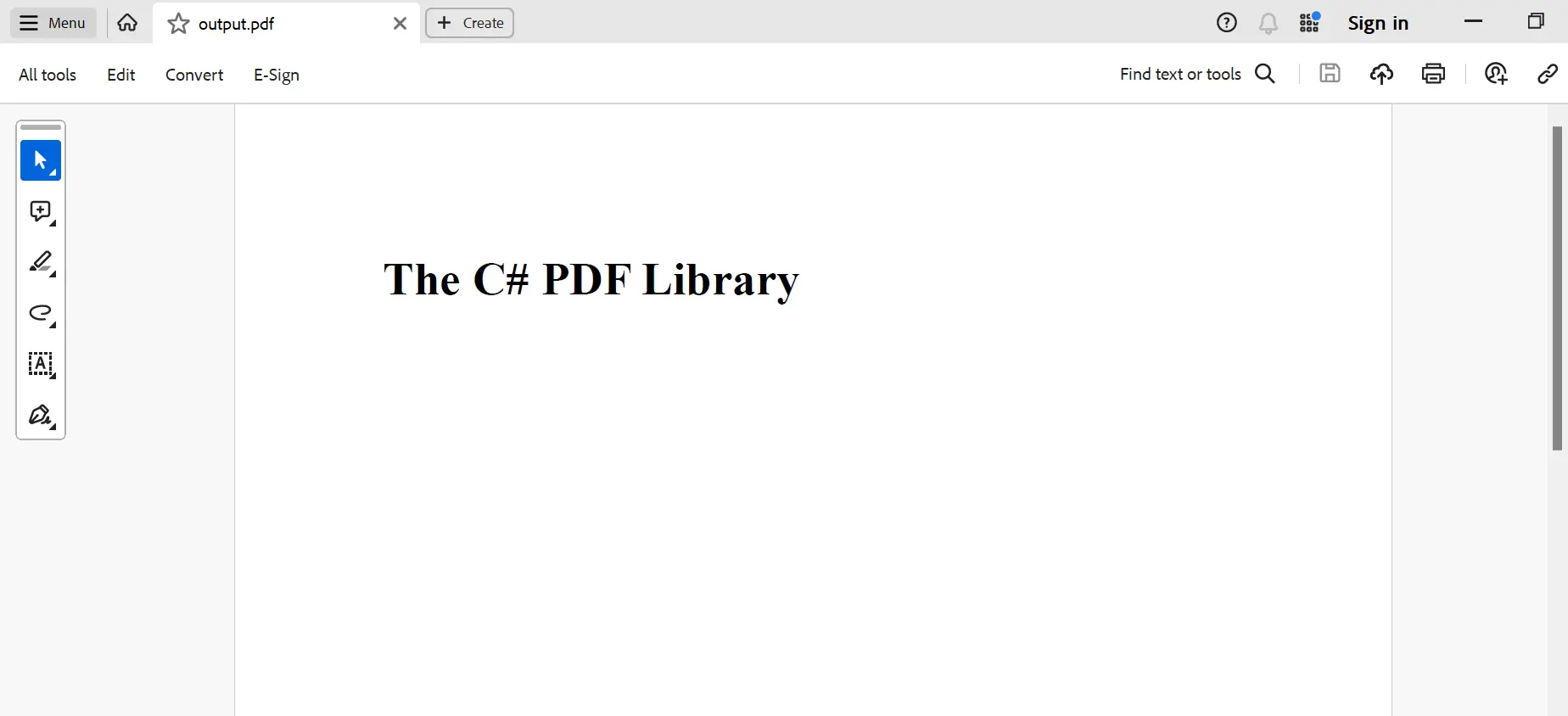
结论
无论是解析HTML数据还是创建PDF报告,通过HTML Agility Pack和IronPDF的在C#中的平滑集成,开发人员都能轻松管理和修改文档材料。 通过结合IronPDF的PDF生产功能和HTML Agility Pack的解析能力,开发人员可以轻松准确地自动化与文档相关的操作。 这两个库的结合提供了一个强大的C#文档管理解决方案,无论是构建动态报告还是从网页中提取数据。
$999 Lite 套装包含永久许可证、一年的软件维护和库升级。 IronPDF提供了有限制的免费许可证,有时间和再分发的限制。 在试用期内,用户可以在没有水印的情况下评估该解决方案。 请访问IronPDF的许可信息以了解更多关于成本和许可证。
了解更多关于Iron Software库的信息。
常见问题解答
如何在C#中将HTML转换为PDF?
你可以使用IronPDF的RenderHtmlAsPdf方法将HTML字符串转换为PDF。你还可以使用RenderHtmlFileAsPdf将HTML文件转换为PDF。
在 C# 项目中使用 HtmlAgilityPack 的目的是什么?
HtmlAgilityPack 在 C# 项目中用于解析和操作 HTML 文档。它可以处理格式不佳的 HTML,非常适合用于网页抓取和数据提取任务。
如何在 C# 应用程序中设置 HtmlAgilityPack?
要设置 HtmlAgilityPack,请在 Visual Studio 中通过 NuGet 包管理器安装它。安装后,您可以导入必要的命名空间并开始在应用程序中解析 HTML 内容。
IronPDF 和 HtmlAgilityPack 可以一起用于文档创建吗?
是的,IronPDF 和 HtmlAgilityPack 可以结合使用,从 HTML 内容创建动态 PDF 文档。HtmlAgilityPack 提取和操作 HTML 数据,然后可以使用 IronPDF 将其转换为 PDF。
.NET 开发人员的 IronPDF 主要功能是什么?
IronPDF 提供将 HTML 转换为 PDF、合并 PDF、向 PDF 添加文本或图像等功能。它支持广泛的功能,以实现 .NET 应用程序中强大的 PDF 文档管理。
HtmlAgilityPack 如何帮助从网页中提取数据?
HtmlAgilityPack 允许开发人员加载 HTML 文档并使用 XPath 或 LINQ 查询基于特定节点或属性导航和提取数据,从而促进网页数据提取。
将 PDF 库与 HtmlAgilityPack 集成有哪些好处?
将 IronPDF 与 HtmlAgilityPack 集成可以通过将动态 HTML 内容转换为 PDF 报告来增强文档自动化,从而简化 .NET 应用程序中的文档生成。
是否可以在控制台应用程序中使用 IronPDF?
是的,IronPDF 可以在各种 C# 应用程序类型中实现,包括 Windows 控制台应用程序,允许进行多样化的文档处理和 PDF 生成。
HtmlAgilityPack 可以执行哪些类型的 HTML 操作?
HtmlAgilityPack 支持添加、删除或修改 HTML 节点和元素以及重新组织 DOM 结构等操作,使其成为 HTML 文档操作的多功能工具。
IronPDF 为开发人员提供免费试用吗?
IronPDF 提供带有某些限制的免费许可证,允许开发人员在试用期内评估库而没有水印,提供测试功能的机会。














