
Cómo Leer Tablas de PDF en C#
Extraer datos de tabla estructurada de documentos PDF es una necesidad frecuente para los desarrolladores de C#, crucial para el análisis de datos, informes o integración de información en otros sistemas. Sin embargo, los PDF están diseñados principalmente para una presentación visual consistente, no para una extracción de datos sencilla. Esto puede hacer que leer tablas de archivos PDF programáticamente en C# sea una tarea desafiante, especialmente porque las tablas pueden variar ampliamente, desde simples cuadrículas basadas en texto hasta diseños complejos con celdas combinadas, o incluso tablas incrustadas como imágenes en documentos escaneados.
Esta guía proporciona un tutorial completo de C# sobre cómo abordar la extracción de tablas PDF utilizando IronPDF. Exploraremos principalmente aprovechando las potentes capacidades de extracción de texto de IronPDF para acceder y luego analizar datos tabulares de PDF basados en texto. Discutiremos la efectividad de este método, proporcionaremos estrategias para el análisis y ofreceremos ideas para manejar la información extraída. Además, abordaremos estrategias para enfrentar escenarios más complejos, incluidos los PDF escaneados.
Pasos Clave para Extraer Datos de Tablas de PDFs en C#
- Instalar la Biblioteca C# IronPDF (https://nuget.org/packages/IronPdf/) para el procesamiento de PDF.
- (Paso de demostración opcional) Cree un PDF de muestra con una tabla a partir de una cadena HTML usando
RenderHtmlAsPdfde IronPDF. (Ver sección: (Paso de Demostración) Crear un Documento PDF con Datos de Tabla) - Cargue cualquier documento PDF y utilice el método
ExtractAllTextpara recuperar su contenido de texto sin formato. (See section: Extract All Text Containing Table Data from the PDF) - Implementar lógica C# para analizar el texto extraído e identificar filas y celdas de la tabla. (See section: Parsing Extracted Text to Reconstruct Table Data in C#)
- Mostrar los datos de tabla estructurados o guardarlos en un archivo CSV para un uso posterior. (See section: Parsing Extracted Text to Reconstruct Table Data in C#)
- Considerar técnicas avanzadas como OCR para PDF escaneados (discutido más adelante).
IronPDF - Biblioteca PDF C#
IronPDF es una solución de Biblioteca C# .NET para manipulación de PDF en .NET (https://ironpdf.com/), que ayuda a los desarrolladores a leer, crear y editar documentos PDF fácilmente en sus aplicaciones de software. Su robusto Motor Chromium renderiza documentos PDF desde HTML con alta precisión y velocidad. Permite a los desarrolladores convertir sin problemas desde diferentes formatos a PDF y viceversa. Soporta los últimos marcos .NET incluyendo .NET 7, .NET 6, 5, 4, .NET Core y Standard.
Además, la API .NET de IronPDF también permite a los desarrolladores manipular y editar PDF, agregar encabezados y pies de página, y lo más importante, extraer texto, imágenes y (como veremos) datos de tabla de PDF con facilidad.
Algunas características importantes son:
- Crear archivos PDF desde varias fuentes (HTML a PDF, Imágenes a PDF)
- Cargar, Guardar y Imprimir archivos PDF
- Combinar y dividir archivos PDF
- Extraer Datos (Texto, Imágenes y datos estructurados como tablas) de archivos PDF
Pasos para extraer datos de tablas en C# utilizando la biblioteca IronPDF
Para extraer datos de tabla de documentos PDF, configuraremos un proyecto de C#:
- Visual Studio: asegúrese de tener instalado Visual Studio (por ejemplo, 2022). Si no, descárgalo desde el sitio web de Visual Studio (https://visualstudio.microsoft.com/downloads/).
-
Crear proyecto:
-
Abre Visual Studio 2022 y haz clic en Crear un nuevo proyecto.
 Pantalla de inicio de Visual Studio
Pantalla de inicio de Visual Studio
-
-
Selecciona "Aplicación de Consola" (o tu tipo de proyecto C# preferido) y haz clic en Siguiente.
 **Crear una nueva aplicación de consola en Visual Studio** -
Nombra tu proyecto (por ej., "ReadPDFTableDemo") y haz clic en Siguiente.
 Configura la nueva aplicación creada
Configura la nueva aplicación creada-
Elige tu marco .NET deseado (por ej., .NET 6 o posterior).
 Selecciona un marco .NET
Selecciona un marco .NET - Haz clic en Crear. El proyecto de consola será creado.
-
- Instalar IronPDF:
- Uso del Administrador de paquetes NuGet de Visual Studio:
-
Haz clic derecho en tu proyecto en el Explorador de Soluciones y selecciona "Administrar Paquetes de NuGet..."
 **Herramientas y Administrar Paquetes de NuGet** -
En el Administrador de Paquetes NuGet, busca "IronPDF" y haz clic en "Instalar".
 Herramientas y Administrar Paquetes de NuGet
Herramientas y Administrar Paquetes de NuGet- Descargue el paquete NuGet directamente: Visite la página del paquete NuGet de IronPDF ( IronPDF ) .
- Descargue la biblioteca IronPDF .DLL: descárguela del sitio web oficial de IronPDF y haga referencia a la DLL en su proyecto.
(Paso de demostración) Crear un documento PDF con datos de tabla
Para este tutorial, primero crearemos un PDF de ejemplo que contenga una tabla simple desde un string de HTML. Esto nos proporciona una estructura PDF conocida para demostrar el proceso de extracción. En un escenario del mundo real, cargarías tus archivos PDF preexistentes.
Añade el espacio de nombres de IronPDF y opcionalmente configura tu clave de licencia (IronPDF es gratis para desarrollo pero requiere una licencia para despliegue comercial sin marcas de agua):
using IronPdf;
using System; // For StringSplitOptions, Console
using System.IO; // For StreamWriter
// Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
// License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";using IronPdf;
using System; // For StringSplitOptions, Console
using System.IO; // For StreamWriter
// Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
// License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";Imports IronPdf
Imports System ' For StringSplitOptions, Console
Imports System.IO ' For StreamWriter
' Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
' License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";Aquí está el string de HTML para nuestra tabla de ejemplo:
string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h1>" + // Corrected typo: h1 not h2
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h1>" + // Corrected typo: h1 not h2
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";Ahora, usa ChromePdfRenderer para crear un PDF a partir de este HTML:
var renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");
Console.WriteLine("Sample PDF 'table_example.pdf' created.");var renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");
Console.WriteLine("Sample PDF 'table_example.pdf' created.");Dim renderer = New ChromePdfRenderer()
Dim pdfDocument As PdfDocument = renderer.RenderHtmlAsPdf(HTML)
pdfDocument.SaveAs("table_example.pdf")
Console.WriteLine("Sample PDF 'table_example.pdf' created.")El método SaveAs guarda el PDF. El table_example.pdf generado se verá así (imagen conceptual basada en HTML):
 Buscar IronPDF en la IU del Administrador de Paquetes NuGet
Buscar IronPDF en la IU del Administrador de Paquetes NuGet
Extraer del PDF todo el texto que contenga datos de tabla
Para extraer datos de la tabla, primero cargamos el PDF (el que acabamos de crear o cualquier PDF existente) y usamos el método ExtractAllText. Este método recupera todo el contenido textual de las páginas del PDF.
// Load the PDF (if you just created it, it's already loaded in pdfDocument)
// If loading an existing PDF:
// PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
// Or use the one created above:
string allText = pdfDocument.ExtractAllText();// Load the PDF (if you just created it, it's already loaded in pdfDocument)
// If loading an existing PDF:
// PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
// Or use the one created above:
string allText = pdfDocument.ExtractAllText();' Load the PDF (if you just created it, it's already loaded in pdfDocument)
' If loading an existing PDF:
' PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
' Or use the one created above:
Dim allText As String = pdfDocument.ExtractAllText()La variable allText ahora contiene todo el contenido de texto del PDF. Puedes mostrarlo para ver la extracción en bruto:
Console.WriteLine("\n--- Raw Extracted Text ---");
Console.WriteLine(allText);Console.WriteLine("\n--- Raw Extracted Text ---");
Console.WriteLine(allText);Imports Microsoft.VisualBasic
Console.WriteLine(vbLf & "--- Raw Extracted Text ---")
Console.WriteLine(allText)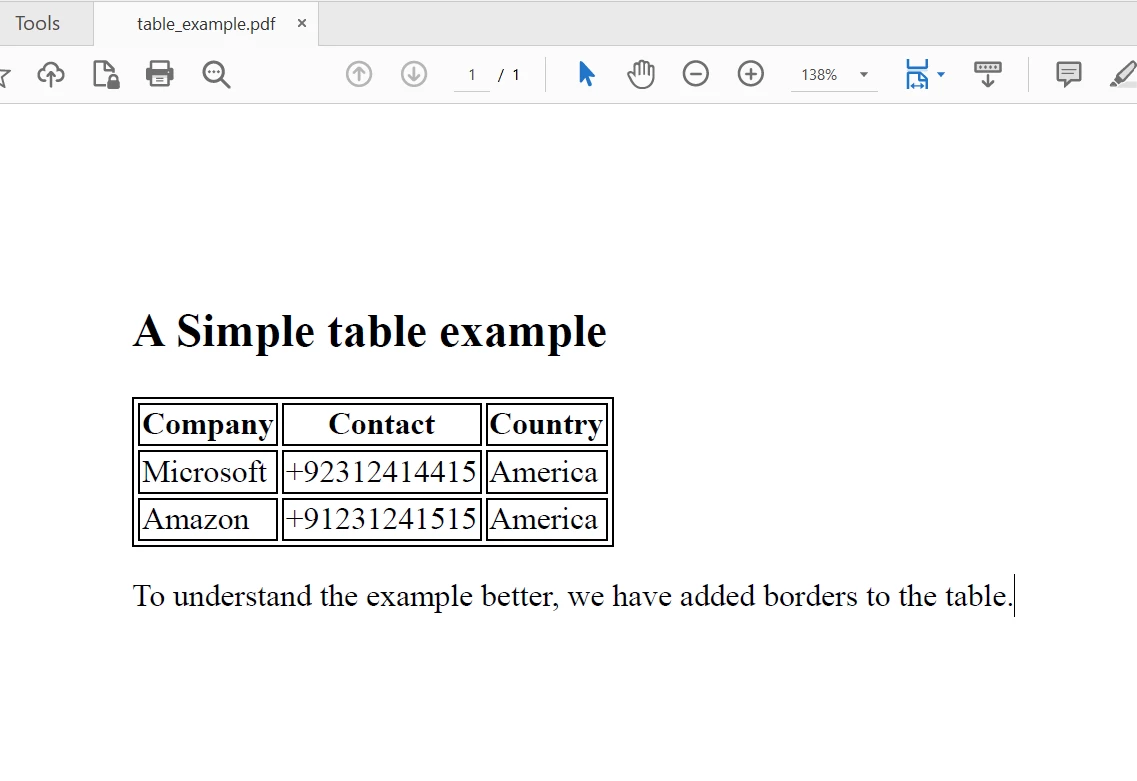 El archivo PDF para extraer texto
El archivo PDF para extraer texto
Parar texto extraído para reconstruir datos de tabla en C#
Con el texto en bruto extraído, el siguiente desafío es analizar este string para identificar y estructurar los datos tabulares. Este paso depende en gran medida de la consistencia y el formato de las tablas en tus PDF.
Estrategias Generales de Análisis:
- Identifique los delimitadores de filas: los caracteres de nueva línea (
\no\r\n) son separadores de filas comunes. - Identificar Delimitadores de Columnas: Las celdas dentro de una fila pueden estar separadas por múltiples espacios, tabulaciones o caracteres conocidos específicos (como '|' o ';').|A veces, si las columnas están alineadas visualmente sin delimitadores claros, se puede inferir la estructura por patrones de espacio, aunque es más complejo. 3. Filtrar Contenido No Tabular: El método
ExtractAllTextobtiene todo el texto. - Filtrar contenido que no es de tabla: el método
ExtractAllTextobtiene todo el texto. El C#String.Splites una herramienta básica para esto.
El método C# String.Split es una herramienta básica para esto. Este código divide el texto en líneas.
Console.WriteLine("\n--- Parsed Table Data (Simple Heuristic) ---");
string[] textLines = allText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (string line in textLines)
{
// Simple filter: skip lines with a period, assuming they are not table data in this example
// and skip lines that are too short or headers if identifiable
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// Further split line into cells based on expected delimiters (e.g., multiple spaces)
// This part requires careful adaptation to your PDF's table structure
// Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line); // For now, just print the filtered line
}
}Console.WriteLine("\n--- Parsed Table Data (Simple Heuristic) ---");
string[] textLines = allText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (string line in textLines)
{
// Simple filter: skip lines with a period, assuming they are not table data in this example
// and skip lines that are too short or headers if identifiable
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// Further split line into cells based on expected delimiters (e.g., multiple spaces)
// This part requires careful adaptation to your PDF's table structure
// Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line); // For now, just print the filtered line
}
}Imports Microsoft.VisualBasic
Console.WriteLine(vbLf & "--- Parsed Table Data (Simple Heuristic) ---")
Dim textLines() As String = allText.Split( { ControlChars.Cr, ControlChars.Lf }, StringSplitOptions.RemoveEmptyEntries)
For Each line As String In textLines
' Simple filter: skip lines with a period, assuming they are not table data in this example
' and skip lines that are too short or headers if identifiable
If line.Contains(".") OrElse line.Contains("A Simple table example") OrElse line.Length < 5 Then
Continue For
Else
' Further split line into cells based on expected delimiters (e.g., multiple spaces)
' This part requires careful adaptation to your PDF's table structure
' Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line) ' For now, just print the filtered line
End If
Next lineEl método String.Split de C# es básico para esto. La condición if es un filtro muy básico para el texto que no es de tabla de este ejemplo específico . Resultado del texto filtrado simple:
Salida del texto filtrado simple:
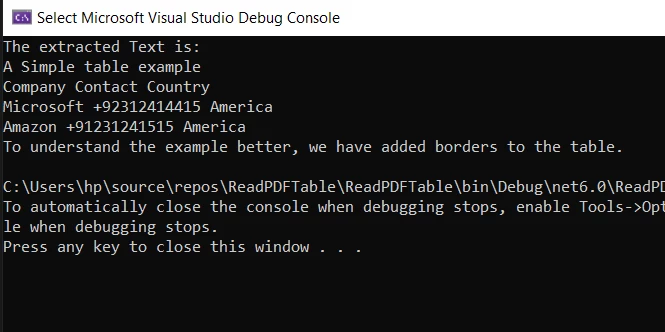 Consideraciones Importantes para el Método de Análisis de Texto:
Consideraciones Importantes para el Método de Análisis de Texto:
-
Más Adecuado Para: PDFs basados en texto con estructuras de tablas simples y consistentes y delimitadores de texto claros.
- Limitaciones: Este método puede tener problemas con:
- Limitaciones: Este método puede tener dificultades con:
Consideraciones Importantes para el Método de Análisis de Texto:
- Tablas incrustadas como imágenes (requiriendo OCR).
- Variaciones en la generación de PDF que llevan a un orden inconsistente de extracción de texto.
Puedes guardar las líneas filtradas (que idealmente representan filas de tabla) en un archivo CSV:
Estrategias para la Extracción de Tablas PDF más Complejas en C#
using (StreamWriter file = new StreamWriter("parsed_table_data.csv", false))
{
file.WriteLine("Company,Contact,Country"); // Write CSV Header
foreach (string line in textLines)
{
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// For a real CSV, you'd split 'line' into cells and join with commas
// E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
// string csvLine = string.Join(",", cells);
// file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()); // Basic replacement for this example
}
}
}
Console.WriteLine("\nFiltered table data saved to parsed_table_data.csv");using (StreamWriter file = new StreamWriter("parsed_table_data.csv", false))
{
file.WriteLine("Company,Contact,Country"); // Write CSV Header
foreach (string line in textLines)
{
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// For a real CSV, you'd split 'line' into cells and join with commas
// E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
// string csvLine = string.Join(",", cells);
// file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()); // Basic replacement for this example
}
}
}
Console.WriteLine("\nFiltered table data saved to parsed_table_data.csv");Imports Microsoft.VisualBasic
Using file As New StreamWriter("parsed_table_data.csv", False)
file.WriteLine("Company,Contact,Country") ' Write CSV Header
For Each line As String In textLines
If line.Contains(".") OrElse line.Contains("A Simple table example") OrElse line.Length < 5 Then
Continue For
Else
' For a real CSV, you'd split 'line' into cells and join with commas
' E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
' string csvLine = string.Join(",", cells);
' file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()) ' Basic replacement for this example
End If
Next line
End Using
Console.WriteLine(vbLf & "Filtered table data saved to parsed_table_data.csv")Estrategias para la extracción de tablas PDF más complejas en C#
IronPDF proporciona funcionalidades que pueden ayudar: * Usando IronOCR para Tablas Escaneadas: Si las tablas están en imágenes (ej., PDFs escaneados), ExtractAllText() no las capturará.
- Uso de las capacidades de IronOCR para tablas escaneadas: si las tablas están dentro de imágenes (por ejemplo, PDF escaneados),
ExtractAllText()por sí solo no las capturará. Para orientación detallada, visita la documentación de IronOCR (https://ironsoftware.com/csharp/ocr/).
// Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
// Install Package IronOcr
using IronOcr;
using (var ocrInput = new OcrInput("scanned_pdf_with_table.pdf"))
{
ocrInput.TargetDPI = 300; // Good DPI for OCR accuracy
var ocrResult = new IronOcr().Read(ocrInput);
string ocrExtractedText = ocrResult.Text;
// Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine("\n--- OCR Extracted Text for Table Parsing ---");
Console.WriteLine(ocrExtractedText);
}// Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
// Install Package IronOcr
using IronOcr;
using (var ocrInput = new OcrInput("scanned_pdf_with_table.pdf"))
{
ocrInput.TargetDPI = 300; // Good DPI for OCR accuracy
var ocrResult = new IronOcr().Read(ocrInput);
string ocrExtractedText = ocrResult.Text;
// Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine("\n--- OCR Extracted Text for Table Parsing ---");
Console.WriteLine(ocrExtractedText);
}' Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
' Install Package IronOcr
Imports Microsoft.VisualBasic
Imports IronOcr
Using ocrInput As New OcrInput("scanned_pdf_with_table.pdf")
ocrInput.TargetDPI = 300 ' Good DPI for OCR accuracy
Dim ocrResult = (New IronOcr()).Read(ocrInput)
Dim ocrExtractedText As String = ocrResult.Text
' Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine(vbLf & "--- OCR Extracted Text for Table Parsing ---")
Console.WriteLine(ocrExtractedText)
End UsingPara obtener una guía detallada, visita la documentación de IronOCR (https://ironsoftware.com/csharp/ocr/). Después de OCR, deberías analizar la cadena de texto resultante.
-
Extracción de texto basada en coordenadas (avanzado): si bien
ExtractAllText()de IronPDF proporciona el flujo de texto, algunos escenarios podrían beneficiarse al conocer las coordenadas x,y de cada fragmento de texto. * Convertir PDF a Otro Formato: IronPDF puede convertir PDFs a formatos estructurados como HTML. - Convertir PDF a Otro Formato: IronPDF puede convertir PDFs a formatos estructurados como HTML. * Reconocimiento de Patrones y Expresiones Regulares: Para tablas con patrones predecibles y delimitadores inconsistentes, expresiones regulares complejas pueden aislar datos de tabla.
PdfDocument pdfToConvert = PdfDocument.FromFile("your_document.pdf");
string htmlOutput = pdfToConvert.ToHtmlString();
// Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.PdfDocument pdfToConvert = PdfDocument.FromFile("your_document.pdf");
string htmlOutput = pdfToConvert.ToHtmlString();
// Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.Dim pdfToConvert As PdfDocument = PdfDocument.FromFile("your_document.pdf")
Dim htmlOutput As String = pdfToConvert.ToHtmlString()
' Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.- Reconocimiento de Patrones y Expresiones Regulares: Para tablas con patrones muy predecibles pero delimitadores inconsistentes, las expresiones regulares complejas aplicadas al texto extraído a veces pueden aislar los datos de la tabla.
Para documentos comerciales comunes con tablas en texto, IronPDF's ExtractAllText y lógica de análisis en C# son muy efectivas. Para tablas en imágenes, es esencial el OCR. Para muchos documentos empresariales comunes con tablas de texto, la combinación de ExtractAllText de IronPDF con la lógica de análisis inteligente de C# puede ser muy eficaz. Para tablas de imágenes, sus funciones de OCR son esenciales.
Resumen
Este artículo demostró cómo extraer datos de una tabla de un documento PDF en C# usando IronPDF , centrándose principalmente en aprovechar el método ExtractAllText() y el posterior análisis de cadenas. IronPDF proporciona un conjunto de herramientas versátil para los desarrolladores de .NET, simplificando muchas tareas relacionadas con PDF, desde la creación y edición hasta la extracción completa de datos.
Proporciona métodos como ExtractTextFromPage para extracción de páginas y soporta conversiones de markdown o DOCX a PDF. Ofrece métodos como ExtractTextFromPage para la extracción de páginas específicas y admite conversiones de formatos como Markdown o DOCX a PDF.
IronPDF es gratuito para desarrollo y ofrece una licencia de prueba gratuita para probar sus características comerciales completas. Para más detalles y casos de uso avanzados, revisa la documentación oficial de IronPDF y ejemplos (https://ironpdf.com/)
Para más detalles y casos de uso avanzados, consulte la documentación y los ejemplos oficiales de IronPDF (https://ironpdf.com/)
Preguntas Frecuentes
¿Cómo puedo leer tablas de archivos PDF de manera programática en C#?
Puedes usar el método `ExtractAllText` de IronPDF para extraer texto en bruto de documentos PDF. Una vez extraído, puedes analizar este texto en C# para identificar filas y celdas de tablas, permitiendo la extracción de datos estructurados.
¿Cuáles son los pasos involucrados en la extracción de datos de tabla de un PDF usando C#?
El proceso incluye instalar la biblioteca IronPDF, usar el método `ExtractAllText` para recuperar texto, analizar este texto para identificar tablas, y opcionalmente guardar los datos estructurados en un formato como CSV.
¿Cómo puedo manejar PDFs escaneados con tablas en C#?
Para PDFs escaneados, IronPDF puede utilizar OCR (Reconocimiento Óptico de Caracteres) para convertir imágenes de tablas en texto, que luego puede ser analizado para extraer datos tabulares.
¿Puede IronPDF convertir PDFs a otros formatos para facilitar la extracción de tablas?
Sí, IronPDF puede convertir PDFs a HTML, lo que puede simplificar la extracción de tablas al permitir a los desarrolladores usar técnicas de análisis de HTML.
¿Es IronPDF adecuado para extraer datos de tablas PDF complejas?
IronPDF proporciona capacidades avanzadas como OCR y extracción de texto basada en coordenadas, que pueden emplearse para manejar disposiciones complejas de tablas, incluidas aquellas con celdas combinadas o delimitadores inconsistentes.
¿Cómo puedo integrar IronPDF en una aplicación .NET Core?
IronPDF es compatible con aplicaciones .NET Core. Puedes integrarlo instalando la biblioteca a través del Administrador de Paquetes NuGet en Visual Studio.
¿Cuáles son los beneficios de usar IronPDF para la manipulación de PDF en C#?
IronPDF ofrece una gama versátil de características para crear, editar y extraer datos de PDFs, incluido el soporte para OCR y conversión a varios formatos, lo que lo convierte en una herramienta poderosa para desarrolladores .NET.
¿Cuáles son los desafíos comunes al extraer datos de tabla de PDFs?
Los desafíos incluyen tratar con disposiciones complejas de tablas, como celdas combinadas, tablas incrustadas como imágenes, y delimitadores inconsistentes, lo que puede requerir estrategias avanzadas de análisis o OCR.
¿Cómo empiezo a usar IronPDF para el procesamiento de PDF?
Comienza instalando la biblioteca IronPDF a través del Administrador de Paquetes NuGet o descargándola desde el sitio web de IronPDF. Esta configuración es esencial para utilizar sus capacidades de procesamiento de PDF en tus proyectos de C#.
¿Requiere una licencia el uso de IronPDF?
IronPDF es gratuito para propósitos de desarrollo, pero se requiere una licencia para el despliegue comercial para eliminar marcas de agua. Se ofrece una licencia de prueba gratuita para probar sus funciones completas.
¿IronPDF es compatible con .NET 10 al extraer tablas de archivos PDF?
Sí. IronPDF es compatible con .NET 10 (así como con .NET 9, 8, 7, 6, Core, Standard y Framework), por lo que todas las funciones de extracción de tablas funcionan sin modificaciones en las aplicaciones .NET 10.












