
How to Read PDF Table in C#
Extracting structured table data from PDF documents is a frequent necessity for C# developers, crucial for data analysis, reporting, or integrating information into other systems. However, PDFs are primarily designed for consistent visual presentation, not straightforward data extraction. This can make reading tables from PDF files programmatically in C# a challenging task, especially as tables can vary widely—from simple text-based grids to complex layouts with merged cells, or even tables embedded as images in scanned documents.
This guide provides a comprehensive C# tutorial on how to approach PDF table extraction using IronPDF. We will primarily explore leveraging IronPDF's powerful text extraction capabilities to access and then parse tabular data from text-based PDFs. We'll discuss the effectiveness of this method, provide strategies for parsing, and offer insights into handling the extracted information. Additionally, we'll touch upon strategies for tackling more complex scenarios, including scanned PDFs.
Key Steps to Extract Table Data from PDFs in C#
- Install the IronPDF C# Library (https://nuget.org/packages/IronPdf/) for PDF processing.
- (Optional Demo Step) Create a sample PDF with a table from an HTML string using IronPDF's
RenderHtmlAsPdf. (See section: (Demo Step) Create a PDF Document with Table Data) - Load any PDF document and use the
ExtractAllTextmethod to retrieve its raw text content. (See section: Extract All Text Containing Table Data from the PDF) - Implement C# logic to parse the extracted text and identify table rows and cells. (See section: Parsing Extracted Text to Reconstruct Table Data in C#)
- Output the structured table data or save it to a CSV file for further use. (See section: Parsing Extracted Text to Reconstruct Table Data in C#)
- Consider advanced techniques like OCR for scanned PDFs (discussed later).
IronPDF - C# PDF Library
IronPDF is a C# .NET Library solution for PDF manipulation in .NET (https://ironpdf.com/), that helps developers read, create, and edit PDF documents easily in their software applications. Its robust Chromium Engine renders PDF documents from HTML with high accuracy and speed. It allows developers to convert from different formats to PDF and vice versa seamlessly. It supports the latest .NET frameworks including .NET 7, .NET 6, 5, 4, .NET Core, and Standard.
Moreover, the IronPDF .NET API also enables developers to manipulate and edit PDFs, add headers and footers, and importantly, extract text, images, and (as we'll see) table data from PDFs with ease.
Some Important Features include:
- Create PDF files from various sources (HTML to PDF, Images to PDF)
- Load, Save, and Print PDF files
- Merge and split PDF files
- Extract Data (Text, Images, and structured data like tables) from PDF files
Steps to Extract Table Data in C# using IronPDF Library
To extract table data from PDF documents, we'll set up a C# project:
- Visual Studio: Ensure you have Visual Studio (e.g., 2022) installed. If not, download it from the Visual Studio website (https://visualstudio.microsoft.com/downloads/).
-
Create Project:
-
Open Visual Studio 2022 and click on Create a new project.
 Visual Studio's start screen
Visual Studio's start screen -
Select "Console App" (or your preferred C# project type) and click Next.
 Create a new Console Application in Visual Studio
Create a new Console Application in Visual Studio -
Name your project (e.g., "ReadPDFTableDemo") and click Next.
 Configure the newly created application
Configure the newly created application -
Choose your desired .NET Framework (e.g., .NET 6 or later).
 Select a .NET Framework
Select a .NET Framework - Click Create. The console project will be created.
-
-
Install IronPDF:
-
Using Visual Studio NuGet Package Manager:
- Right-click your project in Solution Explorer and select "Manage NuGet Packages..."
 Tools & Manage NuGet Packages
Tools & Manage NuGet Packages- In the NuGet Package Manager, browse for "IronPDF" and click "Install".
 Tools & Manage NuGet Packages
Tools & Manage NuGet Packages
- Download NuGet Package directly: Visit IronPDF's NuGet package page (https://www.nuget.org/packages/IronPdf/).
- Download IronPDF .DLL Library: Download from the official IronPDF website and reference the DLL in your project.
-
(Demo Step) Create a PDF Document with Table Data
For this tutorial, we'll first create a sample PDF containing a simple table from an HTML string. This gives us a known PDF structure to demonstrate the extraction process. In a real-world scenario, you would load your pre-existing PDF files.
Add the IronPDF namespace and optionally set your license key (IronPDF is free for development but requires a license for commercial deployment without watermarks):
using IronPdf;
using System; // For StringSplitOptions, Console
using System.IO; // For StreamWriter
// Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
// License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";using IronPdf;
using System; // For StringSplitOptions, Console
using System.IO; // For StreamWriter
// Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
// License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";Imports IronPdf
Imports System ' For StringSplitOptions, Console
Imports System.IO ' For StreamWriter
' Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
' License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";Here's the HTML string for our sample table:
string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h1>" + // Corrected typo: h1 not h2
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h1>" + // Corrected typo: h1 not h2
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";Now, use ChromePdfRenderer to create a PDF from this HTML:
var renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");
Console.WriteLine("Sample PDF 'table_example.pdf' created.");var renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");
Console.WriteLine("Sample PDF 'table_example.pdf' created.");Dim renderer = New ChromePdfRenderer()
Dim pdfDocument As PdfDocument = renderer.RenderHtmlAsPdf(HTML)
pdfDocument.SaveAs("table_example.pdf")
Console.WriteLine("Sample PDF 'table_example.pdf' created.")The SaveAs method saves the PDF. The generated table_example.pdf will look like this (conceptual image based on HTML):
 Search for IronPDF in NuGet Package Manager UI
Search for IronPDF in NuGet Package Manager UI
Extract All Text Containing Table Data from the PDF
To extract table data, we first load the PDF (either the one we just created or any existing PDF) and use the ExtractAllText method. This method retrieves all textual content from the PDF pages.
// Load the PDF (if you just created it, it's already loaded in pdfDocument)
// If loading an existing PDF:
// PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
// Or use the one created above:
string allText = pdfDocument.ExtractAllText();// Load the PDF (if you just created it, it's already loaded in pdfDocument)
// If loading an existing PDF:
// PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
// Or use the one created above:
string allText = pdfDocument.ExtractAllText();' Load the PDF (if you just created it, it's already loaded in pdfDocument)
' If loading an existing PDF:
' PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
' Or use the one created above:
Dim allText As String = pdfDocument.ExtractAllText()The allText variable now holds the entire text content from the PDF. You can display it to see the raw extraction:
Console.WriteLine("\n--- Raw Extracted Text ---");
Console.WriteLine(allText);Console.WriteLine("\n--- Raw Extracted Text ---");
Console.WriteLine(allText);Imports Microsoft.VisualBasic
Console.WriteLine(vbLf & "--- Raw Extracted Text ---")
Console.WriteLine(allText)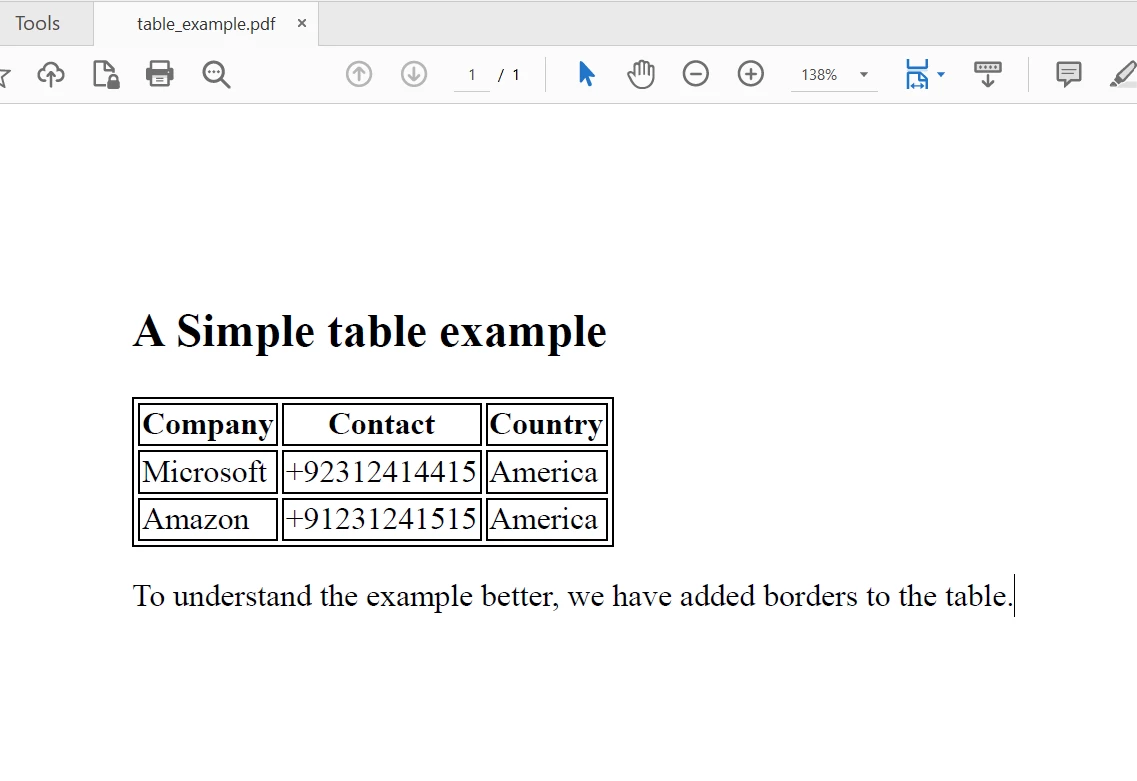 The PDF file to extract text
The PDF file to extract text
Parsing Extracted Text to Reconstruct Table Data in C#
With the raw text extracted, the next challenge is to parse this string to identify and structure the tabular data. This step is highly dependent on the consistency and format of the tables in your PDFs.
General Parsing Strategies:
- Identify Row Delimiters: Newline characters (
\nor\r\n) are common row separators. - Identify Column Delimiters: Cells within a row might be separated by multiple spaces, tabs, or specific known characters (like '|' or ';'). Sometimes, if columns are visually aligned but lack clear text delimiters, you might infer structure based on consistent spacing patterns, although this is more complex.
- Filter Non-Table Content: The
ExtractAllTextmethod gets all text. You'll need logic to isolate the text that actually forms your table, possibly by looking for header keywords or skipping preamble/postamble text.
The C# String.Split method is a basic tool for this. Here's an example that attempts to extract only the table lines from our sample, filtering out lines with periods (a simple heuristic for this specific example):
Console.WriteLine("\n--- Parsed Table Data (Simple Heuristic) ---");
string[] textLines = allText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (string line in textLines)
{
// Simple filter: skip lines with a period, assuming they are not table data in this example
// and skip lines that are too short or headers if identifiable
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// Further split line into cells based on expected delimiters (e.g., multiple spaces)
// This part requires careful adaptation to your PDF's table structure
// Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line); // For now, just print the filtered line
}
}Console.WriteLine("\n--- Parsed Table Data (Simple Heuristic) ---");
string[] textLines = allText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (string line in textLines)
{
// Simple filter: skip lines with a period, assuming they are not table data in this example
// and skip lines that are too short or headers if identifiable
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// Further split line into cells based on expected delimiters (e.g., multiple spaces)
// This part requires careful adaptation to your PDF's table structure
// Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line); // For now, just print the filtered line
}
}Imports Microsoft.VisualBasic
Console.WriteLine(vbLf & "--- Parsed Table Data (Simple Heuristic) ---")
Dim textLines() As String = allText.Split( { ControlChars.Cr, ControlChars.Lf }, StringSplitOptions.RemoveEmptyEntries)
For Each line As String In textLines
' Simple filter: skip lines with a period, assuming they are not table data in this example
' and skip lines that are too short or headers if identifiable
If line.Contains(".") OrElse line.Contains("A Simple table example") OrElse line.Length < 5 Then
Continue For
Else
' Further split line into cells based on expected delimiters (e.g., multiple spaces)
' This part requires careful adaptation to your PDF's table structure
' Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line) ' For now, just print the filtered line
End If
Next lineThis code splits the text into lines. The if condition is a very basic filter for this specific example's non-table text. In real-world scenarios, you would need more robust logic to identify and parse table rows and cells accurately.
Output of the simple filtered text:
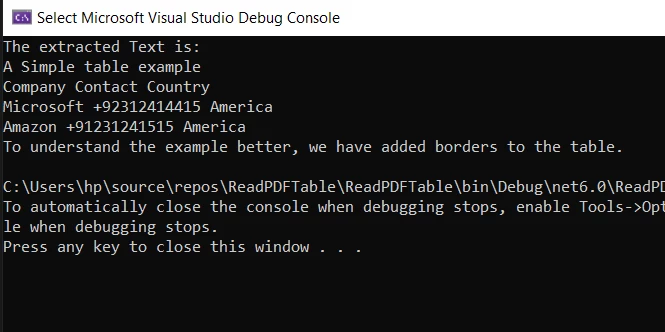 The Console displays extracted texts
The Console displays extracted texts
Important Considerations for Text-Parsing Method:
- Best Suited For: Text-based PDFs with simple, consistent table structures and clear textual delimiters.
- Limitations: This method can struggle with:
- Tables with merged cells or complex nested structures.
- Tables where columns are defined by visual spacing rather than text delimiters.
- Tables embedded as images (requiring OCR).
- Variations in PDF generation leading to inconsistent text extraction order.
You can save the filtered lines (which ideally represent table rows) to a CSV file:
using (StreamWriter file = new StreamWriter("parsed_table_data.csv", false))
{
file.WriteLine("Company,Contact,Country"); // Write CSV Header
foreach (string line in textLines)
{
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// For a real CSV, you'd split 'line' into cells and join with commas
// E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
// string csvLine = string.Join(",", cells);
// file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()); // Basic replacement for this example
}
}
}
Console.WriteLine("\nFiltered table data saved to parsed_table_data.csv");using (StreamWriter file = new StreamWriter("parsed_table_data.csv", false))
{
file.WriteLine("Company,Contact,Country"); // Write CSV Header
foreach (string line in textLines)
{
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// For a real CSV, you'd split 'line' into cells and join with commas
// E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
// string csvLine = string.Join(",", cells);
// file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()); // Basic replacement for this example
}
}
}
Console.WriteLine("\nFiltered table data saved to parsed_table_data.csv");Imports Microsoft.VisualBasic
Using file As New StreamWriter("parsed_table_data.csv", False)
file.WriteLine("Company,Contact,Country") ' Write CSV Header
For Each line As String In textLines
If line.Contains(".") OrElse line.Contains("A Simple table example") OrElse line.Length < 5 Then
Continue For
Else
' For a real CSV, you'd split 'line' into cells and join with commas
' E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
' string csvLine = string.Join(",", cells);
' file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()) ' Basic replacement for this example
End If
Next line
End Using
Console.WriteLine(vbLf & "Filtered table data saved to parsed_table_data.csv")Strategies for More Complex PDF Table Extraction in C#
Extracting data from complex or image-based PDF tables often requires more advanced techniques than simple text parsing. IronPDF provides features that can assist:
- Using IronOCR's Capabilities for Scanned Tables: If tables are within images (e.g., scanned PDFs),
ExtractAllText()alone won't capture them. IronOCR's text detection functionality can convert these images to text first.
// Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
// Install Package IronOcr
using IronOcr;
using (var ocrInput = new OcrInput("scanned_pdf_with_table.pdf"))
{
ocrInput.TargetDPI = 300; // Good DPI for OCR accuracy
var ocrResult = new IronOcr().Read(ocrInput);
string ocrExtractedText = ocrResult.Text;
// Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine("\n--- OCR Extracted Text for Table Parsing ---");
Console.WriteLine(ocrExtractedText);
}// Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
// Install Package IronOcr
using IronOcr;
using (var ocrInput = new OcrInput("scanned_pdf_with_table.pdf"))
{
ocrInput.TargetDPI = 300; // Good DPI for OCR accuracy
var ocrResult = new IronOcr().Read(ocrInput);
string ocrExtractedText = ocrResult.Text;
// Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine("\n--- OCR Extracted Text for Table Parsing ---");
Console.WriteLine(ocrExtractedText);
}' Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
' Install Package IronOcr
Imports Microsoft.VisualBasic
Imports IronOcr
Using ocrInput As New OcrInput("scanned_pdf_with_table.pdf")
ocrInput.TargetDPI = 300 ' Good DPI for OCR accuracy
Dim ocrResult = (New IronOcr()).Read(ocrInput)
Dim ocrExtractedText As String = ocrResult.Text
' Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine(vbLf & "--- OCR Extracted Text for Table Parsing ---")
Console.WriteLine(ocrExtractedText)
End UsingFor detailed guidance, visit the IronOCR documentation (https://ironsoftware.com/csharp/ocr/). After OCR, you'd parse the resulting text string.
-
Coordinate-Based Text Extraction (Advanced): While IronPDF's
ExtractAllText()provides the text stream, some scenarios might benefit from knowing the x,y coordinates of each text snippet. If IronPDF offers APIs to get text with its bounding box information (check current documentation), this could allow for more sophisticated spatial parsing to reconstruct tables based on visual alignment. - Converting PDF to Another Format: IronPDF can convert PDFs to structured formats like HTML. Often, parsing an HTML table is more straightforward than parsing raw PDF text.
PdfDocument pdfToConvert = PdfDocument.FromFile("your_document.pdf");
string htmlOutput = pdfToConvert.ToHtmlString();
// Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.PdfDocument pdfToConvert = PdfDocument.FromFile("your_document.pdf");
string htmlOutput = pdfToConvert.ToHtmlString();
// Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.Dim pdfToConvert As PdfDocument = PdfDocument.FromFile("your_document.pdf")
Dim htmlOutput As String = pdfToConvert.ToHtmlString()
' Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.- Pattern Recognition and Regular Expressions: For tables with very predictable patterns but inconsistent delimiters, complex regular expressions applied to the extracted text can sometimes isolate table data.
Choosing the right strategy depends on the complexity and consistency of your source PDFs. For many common business documents with text-based tables, IronPDF's ExtractAllText coupled with smart C# parsing logic can be very effective. For image-based tables, its OCR capabilities are essential.
Summary
This article demonstrated how to extract table data from a PDF document in C# using IronPDF, primarily focusing on leveraging the ExtractAllText() method and subsequent string parsing. We've seen that while this approach is powerful for text-based tables, more complex scenarios like image-based tables can be addressed using IronPDF's OCR features or by converting PDFs to other formats first.
IronPDF provides a versatile toolkit for .NET developers, simplifying many PDF-related tasks, from creation and editing to comprehensive data extraction. It offers methods like ExtractTextFromPage for page-specific extraction and supports conversions from formats like markdown or DOCX to PDF.
IronPDF is free for development and offers a free trial license for testing its full commercial features. For production deployment, various licensing options are available.
For more details and advanced use cases, explore the official IronPDF documentation and examples (https://ironpdf.com/)
Frequently Asked Questions
How can I read tables from PDF files programmatically in C#?
You can use IronPDF's `ExtractAllText` method to extract raw text from PDF documents. Once extracted, you can parse this text in C# to identify table rows and cells, allowing for structured data extraction.
What steps are involved in extracting table data from a PDF using C#?
The process involves installing the IronPDF library, using the `ExtractAllText` method to retrieve text, parsing this text to identify tables, and optionally saving the structured data to a format like CSV.
How can I handle scanned PDFs with tables in C#?
For scanned PDFs, IronPDF can utilize OCR (Optical Character Recognition) to convert images of tables into text, which can then be parsed to extract tabular data.
Can IronPDF convert PDFs to other formats for easier table extraction?
Yes, IronPDF can convert PDFs to HTML, which can simplify table extraction by allowing developers to use HTML parsing techniques.
Is IronPDF suitable for extracting data from complex PDF tables?
IronPDF provides advanced capabilities like OCR and coordinate-based text extraction, which can be employed to handle complex table layouts, including those with merged cells or inconsistent delimiters.
How can I integrate IronPDF into a .NET Core application?
IronPDF is compatible with .NET Core applications. You can integrate it by installing the library via the NuGet Package Manager in Visual Studio.
What are the benefits of using IronPDF for PDF manipulation in C#?
IronPDF offers a versatile range of features for creating, editing, and extracting data from PDFs, including support for OCR and conversion to various formats, making it a powerful tool for .NET developers.
What are common challenges when extracting table data from PDFs?
Challenges include dealing with complex table layouts, such as merged cells, tables embedded as images, and inconsistent delimiters, which may require advanced parsing strategies or OCR.
How do I start using IronPDF for PDF processing?
Begin by installing the IronPDF library through the NuGet Package Manager or by downloading it from the IronPDF website. This setup is essential for utilizing its PDF processing capabilities in your C# projects.
Does using IronPDF require a license?
IronPDF is free for development purposes, but a license is required for commercial deployment to remove watermarks. A free trial license is available for testing its full features.
Is IronPDF compatible with .NET 10 when extracting tables from PDFs?
Yes. IronPDF supports .NET 10 (as well as .NET 9, 8, 7, 6, Core, Standard, and Framework), so all table extraction functionality works without modification in .NET 10 applications.











