
Cómo Analizar Datos de Documentos PDF
La capacidad de extraer y utilizar datos de PDFs de manera programática presenta desafíos únicos para el posible desarrollador, debido a la complejidad del formato interno de los PDFs.
IronPDF es una de las muchas bibliotecas de programación .NET disponibles que está especialmente posicionada para ayudar a los desarrolladores a superar los desafíos de extraer contenido (texto e imágenes) de PDFs de manera confiable, entre muchas otras tareas relacionadas con PDFs. IronPDF te libera de tener que entender los detalles del formato interno de los PDFs y te permite centrar tu tiempo y esfuerzo en entregar tu proyecto de manera rápida y a tiempo.
Este artículo profundiza en las complejidades del análisis de documentos PDF, las herramientas y técnicas involucradas, y el impacto transformador que la biblioteca IronPDF for .NET puede tener para ayudarte a comprender el contenido de tu PDF.
Conceptos clave
- Análisis de PDFs: Extraer datos estructurados de documentos PDF es el núcleo del análisis de PDFs. Implica reconocer patrones de documentos y definir reglas para recuperar puntos de datos específicos. La información extraída a menudo se almacena en bases de datos o se utiliza en otras aplicaciones.
- Herramientas de análisis de PDFs: Estas herramientas, como IronPDF, Tabula, PyPDF2 y PDFMiner, automatizan el proceso de extracción. Utilizan algoritmos para interpretar la estructura del PDF y extraer información con precisión.
- Proceso de extracción de datos: Extraer datos de PDFs generalmente implica importar archivos en una herramienta de análisis, analizar la estructura del documento y convertir los datos analizados en formatos como HTML, CSV, XML, o directamente en aplicaciones como Excel o Word.
- Datos estructurados vs. no estructurados: Los PDFs suelen contener tanto datos estructurados (por ejemplo, tablas) como no estructurados. Las herramientas de análisis deben manejar ambos tipos para asegurar una extracción de datos significativa.
Cómo analizar datos de documentos PDF: Guía paso a paso
Paso 1: Abrir un extractor de PDF gratuito en línea para analizar archivos PDF
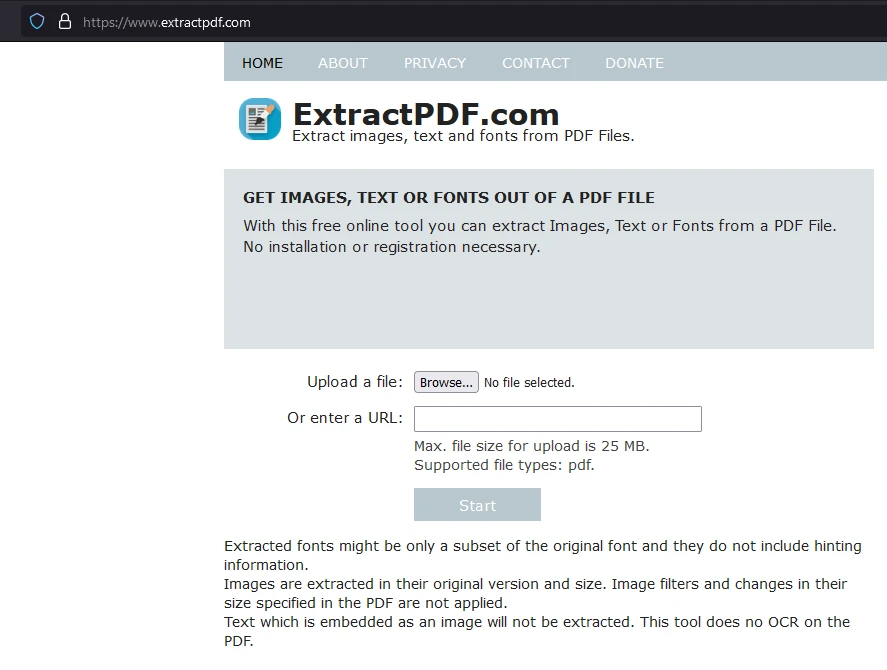
Una herramienta fácil de usar es el Extractor de PDF en línea gratuito. Navega al sitio web, donde puedes ver una descripción general de la herramienta, incluido cómo importa PDFs y qué datos puede extraer.
Paso 2: Cargar el archivo PDF
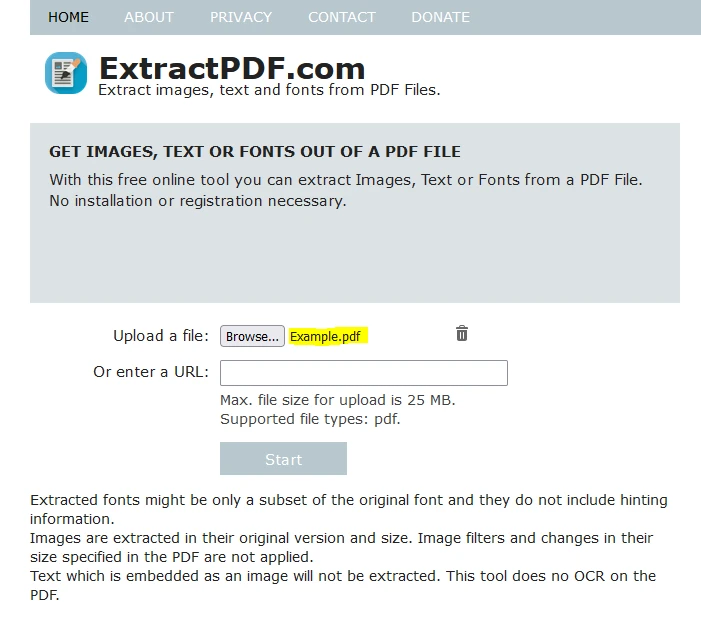
Haz clic en "Examinar" para seleccionar el archivo PDF del cual deseas extraer datos.
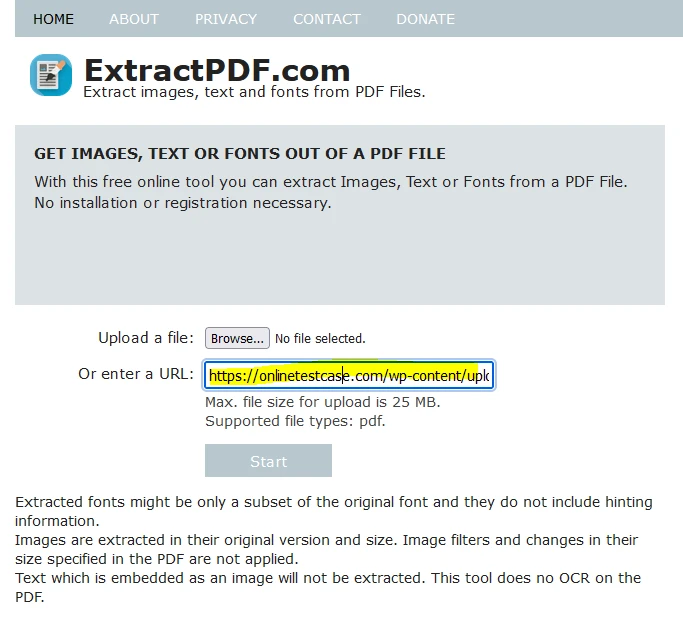
Alternativamente, puedes subir el archivo pegando un enlace al PDF.
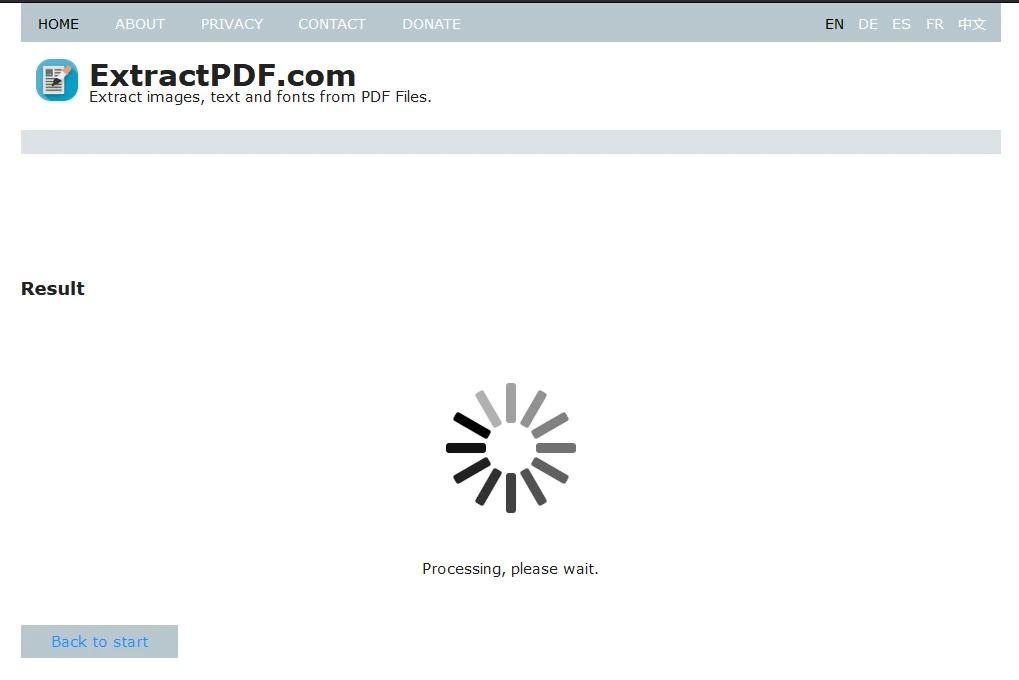
Paso 3: Iniciar la extracción
Después de subir el archivo, haz clic en "Iniciar" para comenzar el proceso de extracción de datos. La herramienta mostrará una pantalla de carga durante el procesamiento.
Paso 4: Descarga de los datos extraídos
Una vez que la extracción se complete, puedes descargar los datos. La herramienta proporciona el texto, las imágenes, las fuentes y los metadatos extraídos del PDF en un formato tabular.
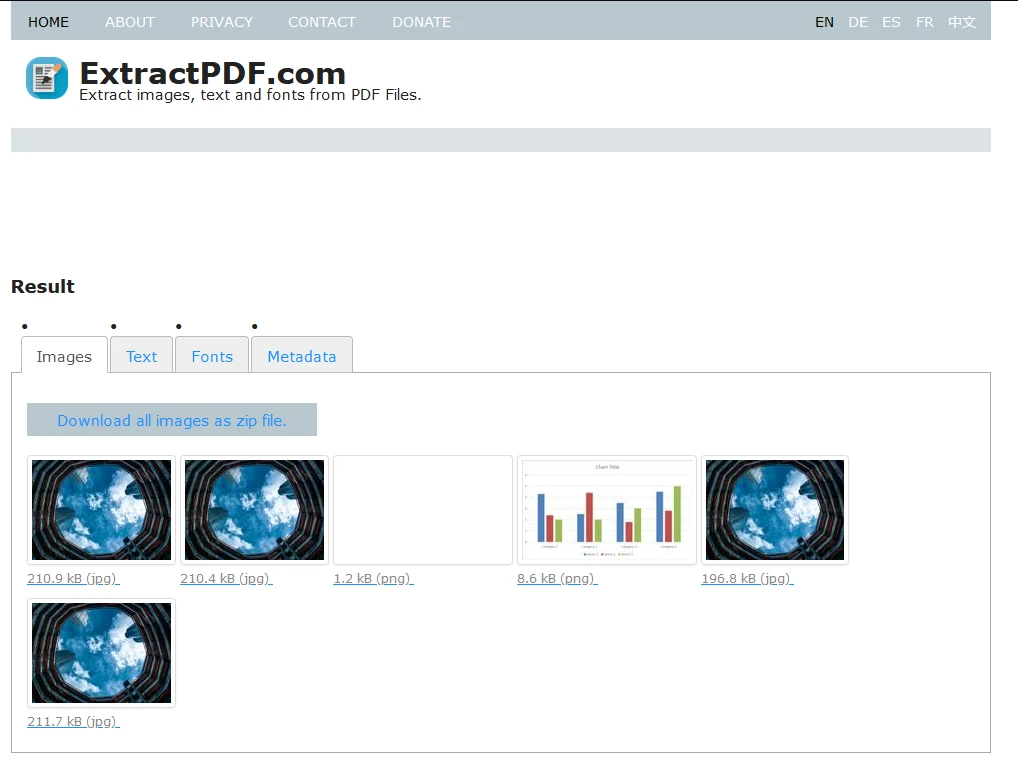
El texto que se puede copiar en bases de datos se encuentra bajo la pestaña 'Texto'.
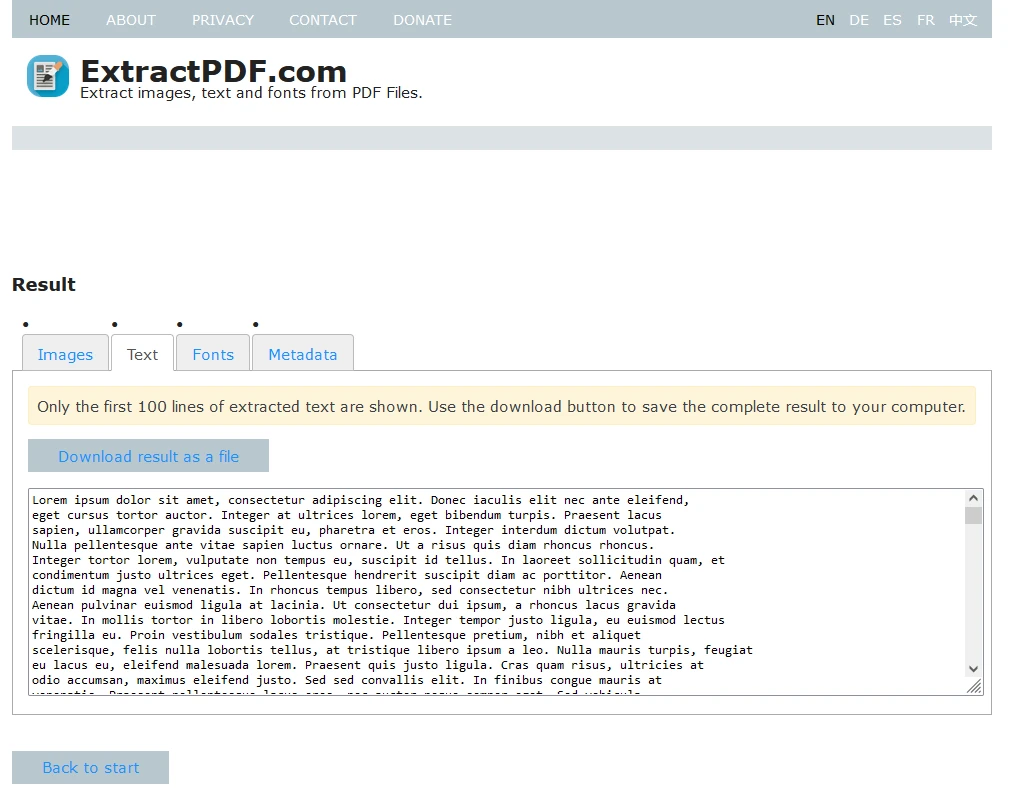
Los metadatos, incluidos el título del documento, el autor, la fecha de creación y más, están disponibles bajo la pestaña 'Metadatos'.
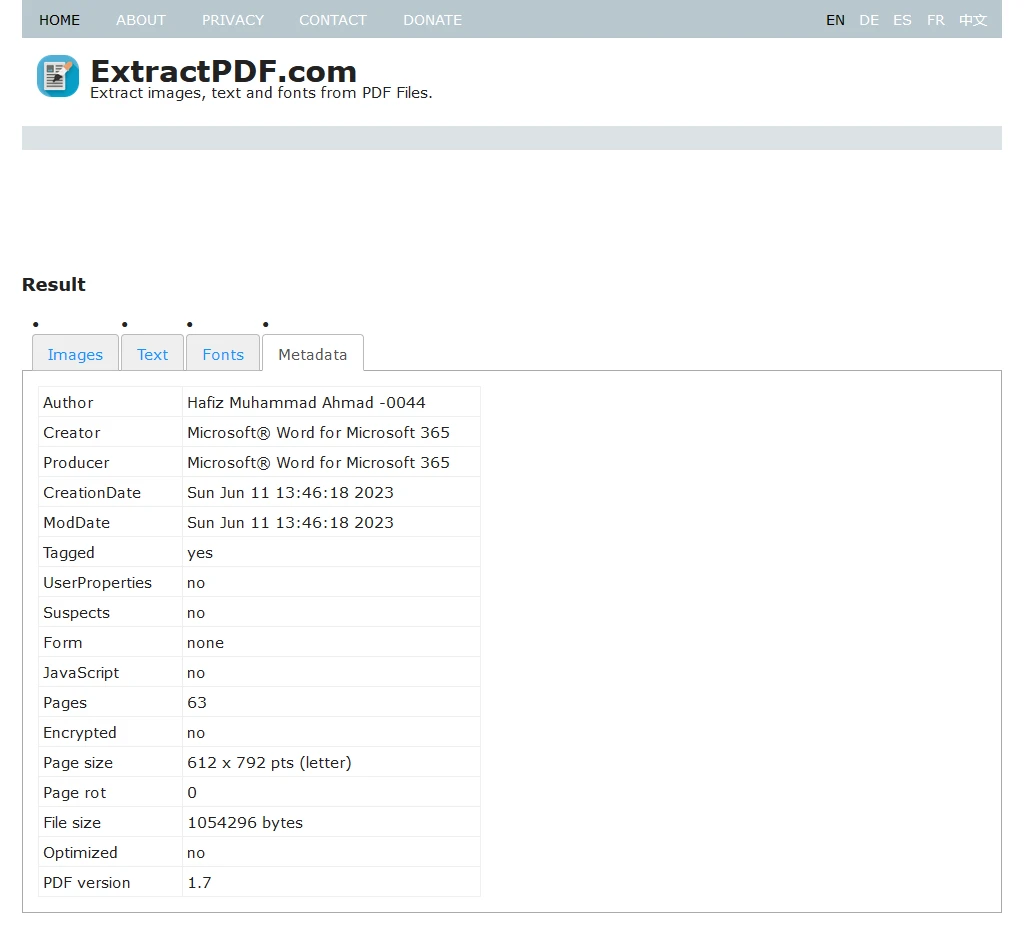
Finalmente, puedes descargar todos los datos extraídos como un archivo ZIP.
Beneficios del análisis de PDF
- Automatización de procesos de negocio: El análisis de PDFs automatiza el proceso de extracción de datos, reduciendo el trabajo manual y mejorando las operaciones empresariales. Esta automatización permite una toma de decisiones más rápida y una mayor escalabilidad.
- Reducción de errores: La entrada manual de datos es propensa a errores. Las herramientas de análisis de PDFs reducen los errores humanos, asegurando un manejo de datos más preciso y reduciendo errores costosos.
- Ahorro de tiempo y costo: Automatizar la extracción de datos de PDFs ahorra tiempo y recursos significativos, que las organizaciones pueden redirigir a tareas más estratégicas.
- Versatilidad en el uso de datos: Los datos extraídos pueden convertirse en varios formatos, lo que facilita su integración con herramientas como Excel, Word o Google Sheets.
Parametrización de datos PDF con IronPDF
IronPDF es una poderosa biblioteca de Iron Software que los desarrolladores pueden usar para extraer datos de PDFs de manera programática. Admite extraer texto, tablas, imágenes y extracción de metadatos de PDF con alta eficiencia.
Instalación de IronPDF
Puedes instalar IronPDF a través del administrador de paquetes IronPDF en NuGet en Visual Studio.
Instalación mediante el gestor de paquetes NuGet
En Visual Studio, busca "IronPDF" en el Administrador de Paquetes NuGet y haz clic en instalar.

Instalación mediante la consola del gestor de paquetes
Alternativamente, usa este comando en la Consola del Administrador de Paquetes:
Install-Package IronPdf
Ejemplo de código: Análisis de un PDF con IronPDF
using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}Imports IronPdf
Namespace ParsePdf
Partial Public Class Form1
Inherits Form
Public Sub New()
InitializeComponent()
' Select the Desired PDF File
Using pdf As PdfDocument = PdfDocument.FromFile("MyDocument.pdf")
' Extract text from the PDF
Dim allText As String = pdf.ExtractAllText()
' Display the extracted text in a MessageBox
' Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK)
End Using
End Sub
End Class
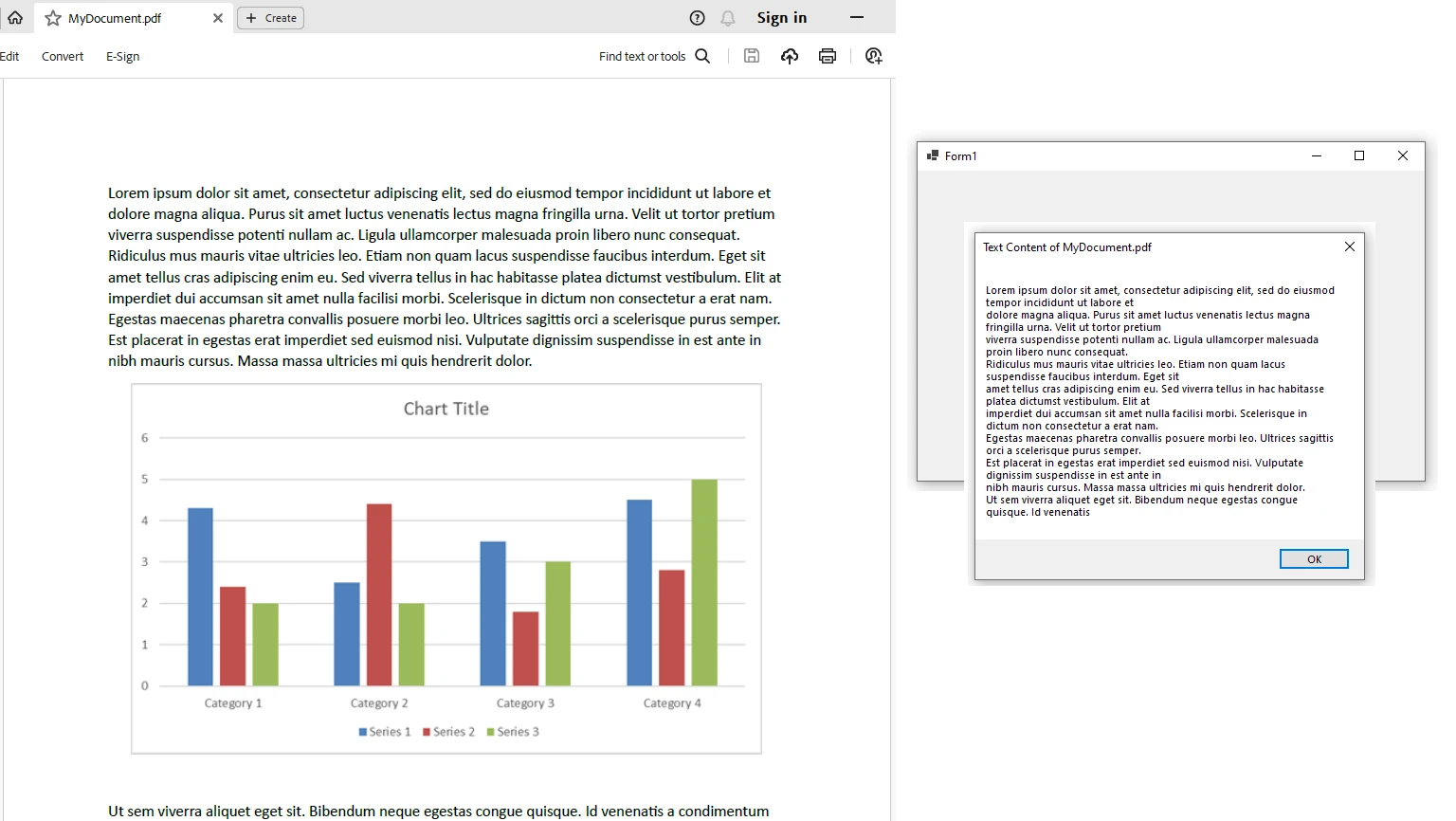
End NamespaceEn este ejemplo, creamos una aplicación de Windows Forms que usa IronPDF para extraer texto de un archivo PDF seleccionado. El texto extraído se muestra en un cuadro de mensaje.
Licencia de IronPDF
IronPDF requiere una clave de licencia de IronPDF que puedes obtener como parte de una licencia de prueba gratuita. Agregue la clave de licencia a su archivo appsettings.json:
{
"IronPdf.LicenseKey": "your license key here"
}Solicita una licencia de prueba gratuita desde la página de licencias del producto de IronPDF.
Conclusión
El análisis eficiente de PDFs desbloquea todo el potencial de los documentos digitales, permitiendo a las empresas automatizar procesos, reducir errores y ahorrar tiempo y dinero. Al dominar las técnicas y herramientas de análisis de PDFs, las organizaciones pueden mejorar la productividad y lograr más con sus activos digitales. IronPDF ofrece una solución ideal para desarrolladores que buscan trabajar programáticamente con documentos PDF.
Preguntas Frecuentes
¿Cómo puedo extraer texto de documentos PDF usando C#?
Puede usar la clase PdfDocument de IronPDF para cargar un archivo PDF y el método ExtractAllText() para extraer texto. Esto permite la fácil recuperación de datos de texto de PDFs.
¿Qué métodos están disponibles en IronPDF para extraer imágenes de un PDF?
IronPDF ofrece métodos como ExtractImages() que se pueden usar para extraer imágenes incrustadas de archivos PDF, convirtiéndolas en formatos como JPEG o PNG.
¿Cómo puedo convertir datos de PDF en un formato CSV usando una biblioteca .NET?
IronPDF le permite analizar y extraer datos de PDFs, que luego se pueden convertir programáticamente en formato CSV utilizando técnicas estándar de manipulación de datos .NET.
¿Cuáles son los desafíos comunes de analizar documentos PDF?
Analizar PDFs puede ser desafiante debido a su estructura compleja, que incluye elementos diversos como texto, imágenes y metadatos. Herramientas como IronPDF ayudan a superar estos desafíos proporcionando métodos sencillos para extraer y manipular contenido de PDF.
¿Se puede usar IronPDF para analizar la estructura del PDF antes de la extracción?
Sí, IronPDF proporciona herramientas para analizar la estructura del PDF, lo que permite a los desarrolladores identificar patrones y determinar las formas más eficientes de extraer los datos necesarios.
¿Cuáles son los requisitos de licencia para usar IronPDF?
IronPDF requiere una licencia válida para su implementación en entornos de producción. Sin embargo, se ofrece una prueba gratuita para fines de evaluación, permitiendo a los usuarios probar las características antes de comprometerse a una compra.
¿Cómo beneficia a las empresas la automatización de la extracción de datos de PDF?
La automatización de la extracción de datos de PDF con herramientas como IronPDF puede reducir significativamente la entrada de datos manual, minimizar errores, ahorrar tiempo y reducir costos operativos, mejorando así la eficiencia general del negocio.
¿Qué lenguajes de programación son compatibles con IronPDF para la extracción de datos de PDF?
IronPDF está diseñado para su uso con lenguajes .NET, principalmente C#, permitiendo una integración perfecta con otras aplicaciones y servicios .NET para una eficiente extracción de datos de PDF.
¿IronPDF es totalmente compatible con .NET 10 al analizar datos PDF?
Sí, IronPDF tiene soporte completo para .NET 10, lo que significa que puede usar sus funciones de análisis como extracción de texto e imágenes, lectura de metadatos, análisis de tablas y conversión de HTML a PDF en proyectos .NET 10 sin soluciones alternativas ni problemas de compatibilidad.












