
How to Parse Data from PDF Documents
The ability to efficiently extract and utilize data from PDFs programmatically presents unique challenges to the would-be developer, due to the complexities of PDFs' internal format.
IronPDF is one of many .NET programming libraries available that is uniquely positioned to help developers overcome the challenges of extracting content (text and images) from PDFs reliably, among many other PDF-related tasks. IronPDF frees you from having to understand the ins and outs of PDFs' internal structure and allows you to focus your time and effort on delivering your project quickly and on time.
This article delves into the intricacies of PDF document parsing, the tools and techniques involved, and the transformative impact that the IronPDF .NET library can have on helping you get a handle on your PDF's content.
Key Concepts
- PDF Parsing: Extracting structured data from PDF documents is the core of PDF parsing. It involves recognizing document patterns and defining rules to retrieve specific data points. The extracted information is often stored in databases or used in other applications.
- PDF Parser Tools: These tools, like IronPDF, Tabula, PyPDF2, and PDFMiner, automate the extraction process. They utilize algorithms to interpret the PDF structure and extract information accurately.
- Data Extraction Process: Extracting data from PDFs typically involves importing files into a parsing tool, analyzing the document’s structure, and converting the parsed data into formats like HTML, CSV, XML, or directly into applications like Excel or Word.
- Structured vs. Unstructured Data: PDFs often contain both structured (e.g., tables) and unstructured data. Parsing tools must handle both types to ensure meaningful data extraction.
How to Parse Data from PDF Documents: Step-by-Step Guide
Step 1: Open Free Online PDF Extractor to Parse PDF Files
One easy-to-use tool is the Free Online PDF Extractor. Navigate to the website, where you can see an overview of the tool, including how it imports PDFs and what data it can extract.
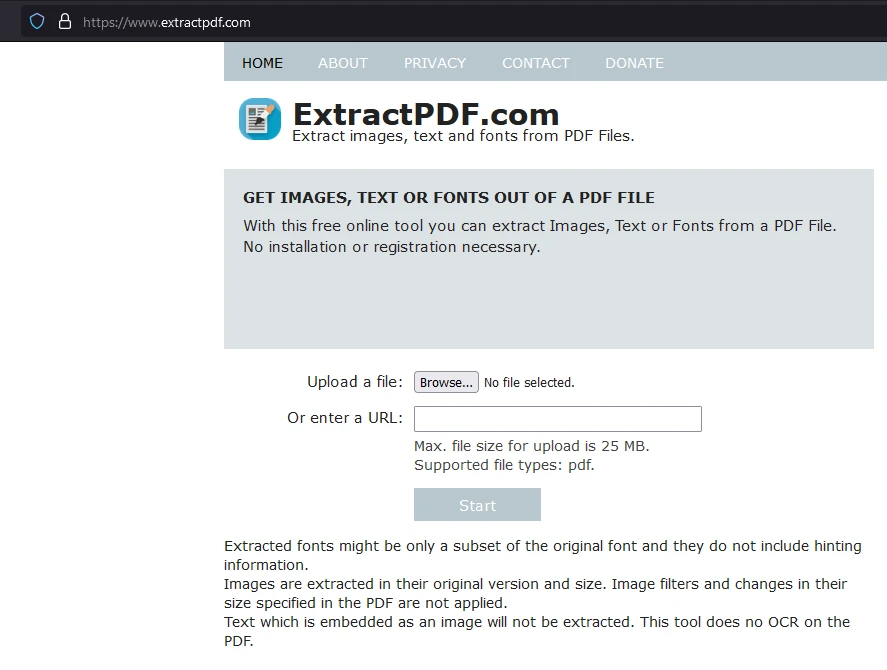
Step 2: Upload the PDF File
Click "Browse" to select the PDF file from which you wish to extract data.
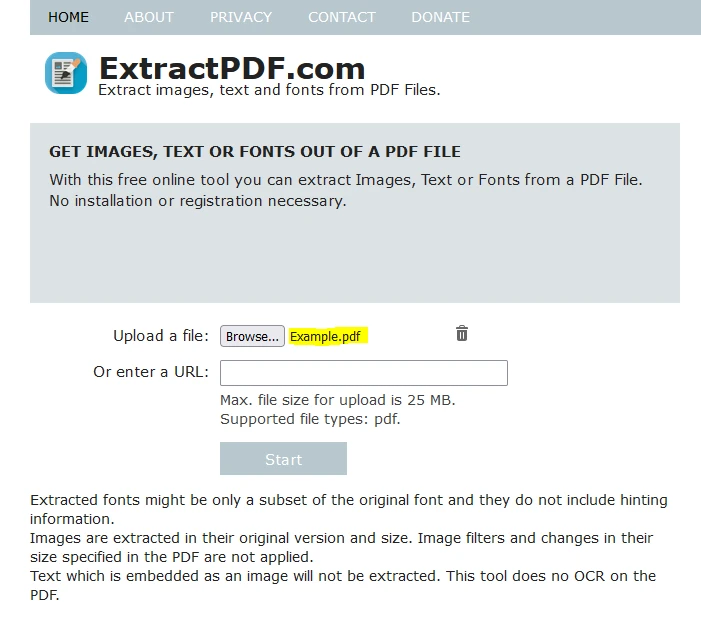
Alternatively, you can upload the file by pasting a link to the PDF.
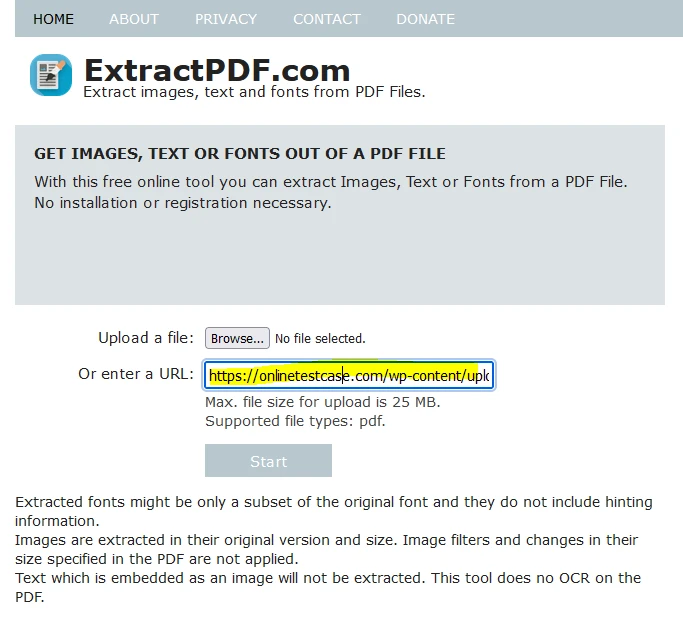
Step 3: Start Extraction
After uploading the file, click "Start" to begin the data extraction process. The tool will display a loading screen during processing.
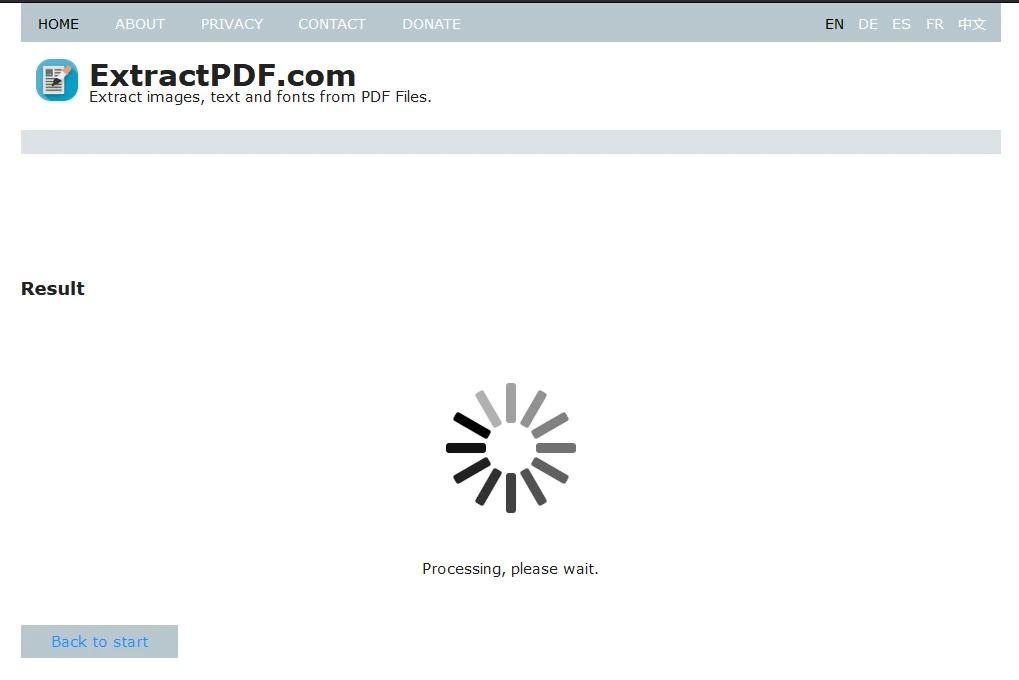
Step 4: Download the Extracted Data
Once the extraction is complete, you can download the data. The tool provides the text, images, fonts, and metadata extracted from the PDF in a tabular format.
Text that can be copied into databases is found under the 'Text' tab.
Metadata, including document title, author, creation date, and more, is available under the 'Metadata' tab.
Finally, you can download all extracted data as a ZIP file.
Benefits of PDF Parsing
- Business Process Automation: PDF parsing automates the data extraction process, reducing manual work and enhancing business operations. This automation enables faster decision-making and greater scalability.
- Error Reduction: Manual data entry is prone to mistakes. PDF parsing tools reduce human errors, ensuring more accurate data handling and reducing costly mistakes.
- Time and Cost Savings: Automating PDF data extraction saves significant time and resources, which organizations can redirect to more strategic tasks.
- Versatility in Data Usage: Extracted data can be converted into various formats, making it easier to integrate with tools like Excel, Word, or Google Sheets.
Parsing PDF Data Using IronPDF
IronPDF is a powerful library from Iron Software that developers can use to extract data from PDFs programmatically. It supports extracting text, tables, images, and PDF metadata extraction with high efficiency.
Installing IronPDF
You can install IronPDF via the IronPDF on NuGet package manager in Visual Studio.
Install Using NuGet Package Manager
In Visual Studio, search for "IronPDF" in the NuGet Package Manager and click install.

Install Using Package Manager Console
Alternatively, use this command in the Package Manager Console:
Install-Package IronPdf
Code Example: Parsing a PDF Using IronPDF
using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
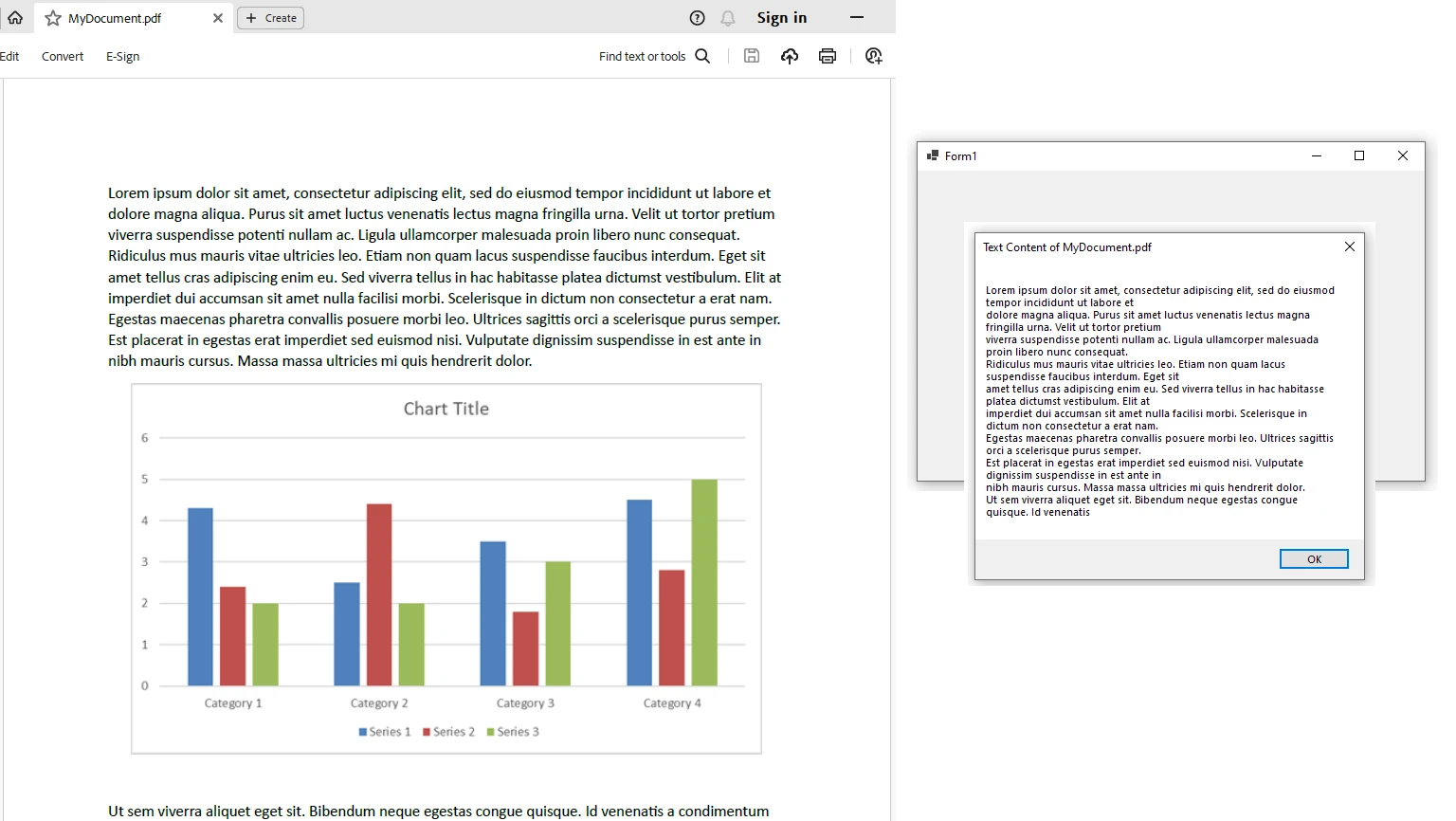
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}Imports IronPdf
Namespace ParsePdf
Partial Public Class Form1
Inherits Form
Public Sub New()
InitializeComponent()
' Select the Desired PDF File
Using pdf As PdfDocument = PdfDocument.FromFile("MyDocument.pdf")
' Extract text from the PDF
Dim allText As String = pdf.ExtractAllText()
' Display the extracted text in a MessageBox
' Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK)
End Using
End Sub
End Class
End NamespaceIn this example, we create a Windows Forms application that uses IronPDF to extract text from a selected PDF file. The extracted text is then displayed in a message box.
Licensing IronPDF
IronPDF requires a license key from IronPDF which you can obtain as part of a free trial license. Add the license key to your appsettings.json file:
{
"IronPdf.LicenseKey": "your license key here"
}Request a free trial license from IronPDF's product licensing page.
Conclusion
Efficient PDF parsing unlocks the full potential of digital documents, enabling businesses to automate processes, reduce errors, and save time and money. By mastering PDF parsing techniques and tools, organizations can enhance productivity and achieve more with their digital assets. IronPDF offers an ideal solution for developers looking to work with PDF documents programmatically.
Frequently Asked Questions
How can I extract text from PDF documents using C#?
You can use IronPDF's PdfDocument class to load a PDF file and the ExtractAllText() method to extract text. This allows for easy retrieval of text data from PDFs.
What methods are available in IronPDF for extracting images from a PDF?
IronPDF provides methods such as ExtractImages() which can be used to extract embedded images from PDF files, converting them into formats like JPEG or PNG.
How can I convert PDF data into a CSV format using a .NET library?
IronPDF allows you to parse and extract data from PDFs, which can then be programmatically converted into CSV format using standard .NET data manipulation techniques.
What are the common challenges of parsing PDF documents?
Parsing PDFs can be challenging due to their complex structure, which includes diverse elements like text, images, and metadata. Tools like IronPDF help overcome these challenges by providing straightforward methods to extract and manipulate PDF content.
Can IronPDF be used to analyze PDF structure before extraction?
Yes, IronPDF provides tools to analyze PDF structure, allowing developers to identify patterns and determine the most efficient ways to extract needed data.
What are the licensing requirements for using IronPDF?
IronPDF requires a valid license for deployment in production environments. However, a free trial is available for evaluation purposes, allowing users to test the features before committing to a purchase.
How does automating PDF data extraction benefit businesses?
Automating PDF data extraction with tools like IronPDF can significantly reduce manual data entry, minimize errors, save time, and lower operational costs, thus improving overall business efficiency.
What programming languages are supported by IronPDF for PDF data extraction?
IronPDF is designed for use with .NET languages, primarily C#, enabling seamless integration with other .NET applications and services for efficient PDF data extraction.
Is IronPDF fully compatible with .NET 10 when parsing PDF data?
Yes — IronPDF has full support for .NET 10, meaning you can use its parsing features like text and image extraction, metadata reading, table parsing, and HTML-to-PDF conversion in .NET 10 projects without workarounds or compatibility issues.











