
Cómo Analizar un Archivo PDF en VB.NET
Este tutorial introduce cómo extraer programáticamente textos e imágenes de archivos PDF con el soporte de primera clase de IronPDF.
Cómo Analizar un Archivo PDF en VB.NET
- Descargar la biblioteca IronPDF C# para analizar archivos PDF
- Utilizar el método `FromFile` para analizar archivos PDF en VB.NET
- Extraer texto de un PDF abierto con el método `ExtractAllText`
- Utilizar el método `ExtractTextFromPages` para extraer texto de determinadas páginas
- Extraer imágenes de un PDF abierto con el método `ExtractRawImagesFromPage`
IronPDF
Características
Conversión PDF eficiente. Casi todo lo que una máquina puede hacer, IronPDF también puede hacerlo. Gracias a esta librería PDF, los desarrolladores pueden rápidamente crear, leer contenido textual, escribir, cargar y manipular PDF.
IronPDF convierte HTML en un registro PDF con la ayuda del motor Chrome. Junto con Windows Forms, HTML, ASPX, Razor HTML, .NET Core, ASP.NET, Windows Forms y WPF. IronPDF también admite aplicaciones de Xamarin, Blazor, Unity, y HoloLens. IronPDF soporta tanto aplicaciones Microsoft .NET como .NET Core (tanto paquetes Web ASP.NET como paquetes convencionales de Windows). IronPDF se puede usar para hacer PDFs estéticamente atractivos.
IronPDF puede crear un PDF utilizando HTML5, JavaScript, CSS e imágenes. IronPDF también tiene un potente convertidor de HTML a PDF que se integra con PDF. Un fuerte mecanismo de conversión PDF está presente en IronPDF al usar el motor de renderizado Chromium. También es independiente de cualquier fuente externa.
- Una imagen PDF se puede crear desde una variedad de fuentes, incluyendo HTML, HTML5, ASPX y Vista Razor/MVC. Tanto los activos HTML como los de imagen se pueden convertir a PDF.
- Las herramientas que se pueden usar para trabajar con PDFs interactivos incluyen completar y enviar formularios interactivos.
- Combinar y dividir PDFs, extraer texto e imágenes de archivos PDF, buscar texto en archivos PDF, rasterizar PDFs a imágenes, cambiar el tamaño de la fuente y convertir archivos PDF.
- Permite la verificación de formularios HTML de inicio de sesión usando agentes de usuario, proxies, cookies, encabezados HTTP y variables de formulario.
- Acceder a documentos protegidos es posible con IronPDF proporcionando nombres de usuario y contraseñas.
- IronPDF es un programa que lee texto en PDF y completa los vacíos.
- Permite agregar texto, imágenes, marcadores, marcas de agua y más.
- Puedes crear un archivo PDF desde un archivo CSS.
Para más detalles, visita esta página de información sobre licencias de IronPDF para obtener una clave limitada gratuita y la versión profesional.
 Formateo de fuente de IronPDF
Formateo de fuente de IronPDF
Extraer texto de un archivo PDF
IronPDF también puede leer y extraer texto de archivos PDF con la ayuda de las bibliotecas de IronPDF. A continuación se muestra un patrón de código de IronPDF que se puede utilizar para examinar archivos PDF presentes.
Extraer texto de todas las páginas
El ejemplo de código a continuación demuestra el primer método para adquirir todo el contenido del PDF como una cadena con solo unas pocas líneas.
Imports IronPdf
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract all the text from the PDF
Dim AllText As String = pdfdoc.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleEl código de muestra anterior demuestra cómo utilizar el método FromFile para leer un PDF de un archivo existente y convertirlo en un objeto de documento PDF. El objeto proporciona un método llamado ExtractAllText que extraerá texto sin formato del PDF y lo convertirá en una cadena.
Extraer texto por número de página
El ejemplo de código a continuación muestra cómo extraer datos de un archivo PDF usando el número de página.
Imports IronPdf
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract text from the first page (page numbers are zero-based)
Dim AllText As String = pdfdoc.ExtractTextFromPage(0)
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleEl código anterior muestra cómo leer un PDF de un archivo existente y convertirlo en un objeto de documento PDF utilizando la función FromFile . Se puede acceder a los textos e imágenes en el PDF usando este objeto. El objeto ofrece un método llamado ExtractTextFromPage que le permite enviar un número de página como parámetro para obtener una cadena que contiene cada palabra que estaba en esa página del PDF.
Extraer texto entre páginas
El siguiente código muestra cómo extraer los datos entre múltiples páginas.
Imports IronPdf
Module Program
Sub Main(args As String())
' Define a list of page numbers from which to extract text
Dim Pages As List(Of Integer) = New List(Of Integer) From {3, 5, 7}
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract text from the specified pages
Dim AllText As String = pdfdoc.ExtractTextFromPages(Pages)
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleEl código anterior demuestra cómo utilizar el método FromFile para leer un PDF de un archivo existente y convertirlo en un objeto de documento PDF. Este objeto permite examinar el texto y las imágenes en el PDF. El objeto tiene un método llamado ExtractTextFromPages que se puede utilizar para obtener una cadena que incluye todo el contenido de texto en páginas determinadas del documento pasando una lista de números de página como parámetro. Acontinuación el lado izquierdo es el PDF de origen y el lado derecho son los datos extraídos.
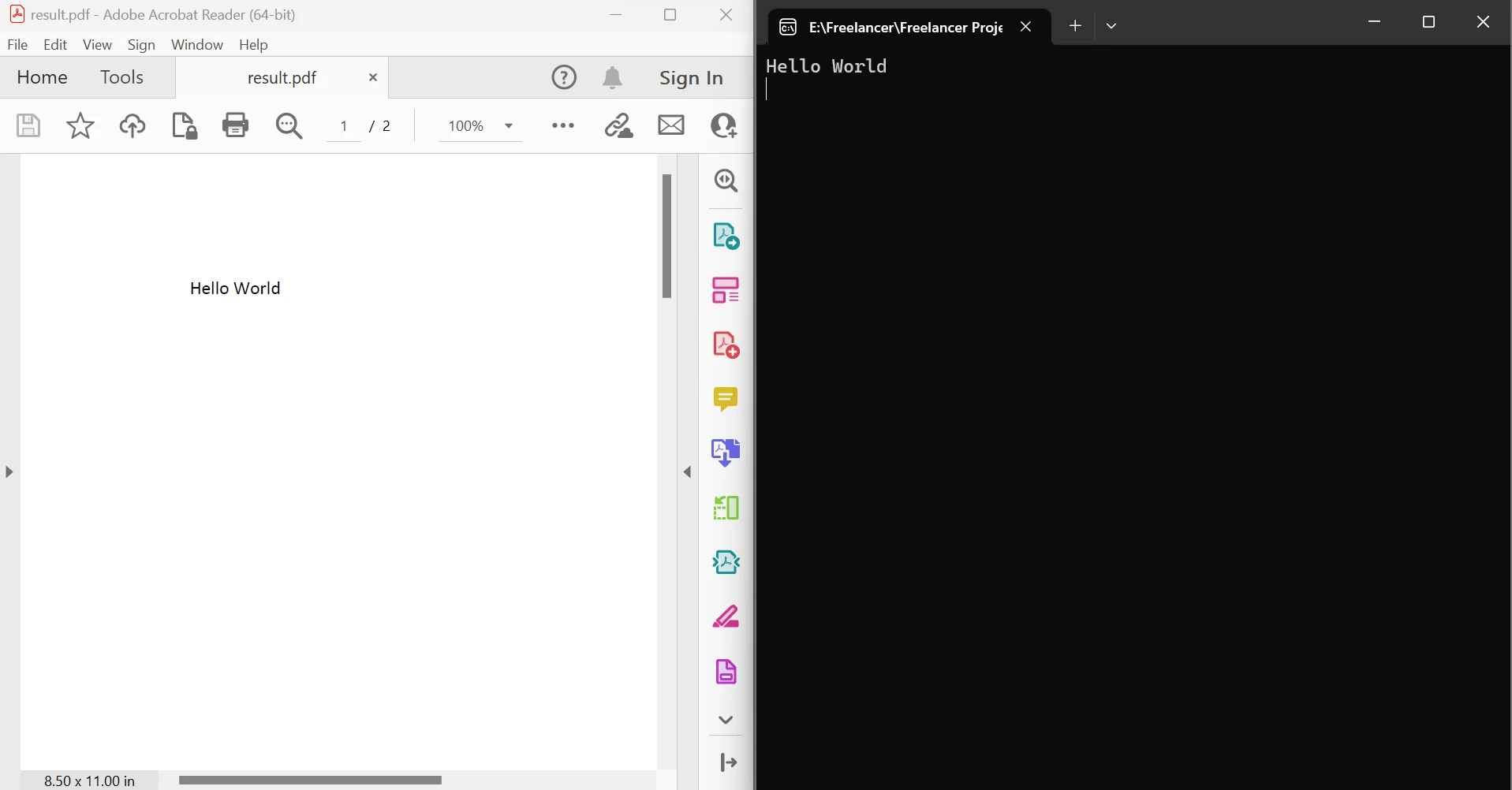 Salida de extracción de texto entre páginas
Salida de extracción de texto entre páginas
Extraer imagen de un archivo PDF
IronPDF proporciona una lista de métodos para extraer imágenes tales como:
ExtractBitmapsFromPageExtractBitmapsFromPagesExtractImagesFromPageExtractImagesFromPagesExtractRawImagesFromPageExtractRawImagesFromPages
Cada método permite extraer imágenes de una página o múltiples páginas del documento.
Imports IronPdf
Imports System.Drawing
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract raw images from the first page
Dim images = pdfdoc.ExtractRawImagesFromPage(1)
' Iterate over extracted images
For Each imgData As Byte() In images
' Create a memory stream from byte data
Using ms As New IO.MemoryStream(imgData)
' Create a Bitmap object from the memory stream
Dim image = New Bitmap(ms)
' Save the image to the specified output directory
image.Save("output/test.jpg")
End Using
Next
End Sub
End ModuleEl código anterior muestra cómo leer un documento de un archivo existente y convertirlo en un objeto de documento PDF utilizando la función FromFile. Al pasar un número de página al método ExtractRawImagesFromPage del objeto, se puede obtener una lista de bytes que contiene todas las imágenes que estaban presentes en esa página del documento. Usando un bucle For Each, cada flujo de bytes se maneja y se convierte en un flujo de memoria, luego en un Bitmap, que ayuda a guardar la imagen. La imagen a continuación muestra la salida del código anterior.
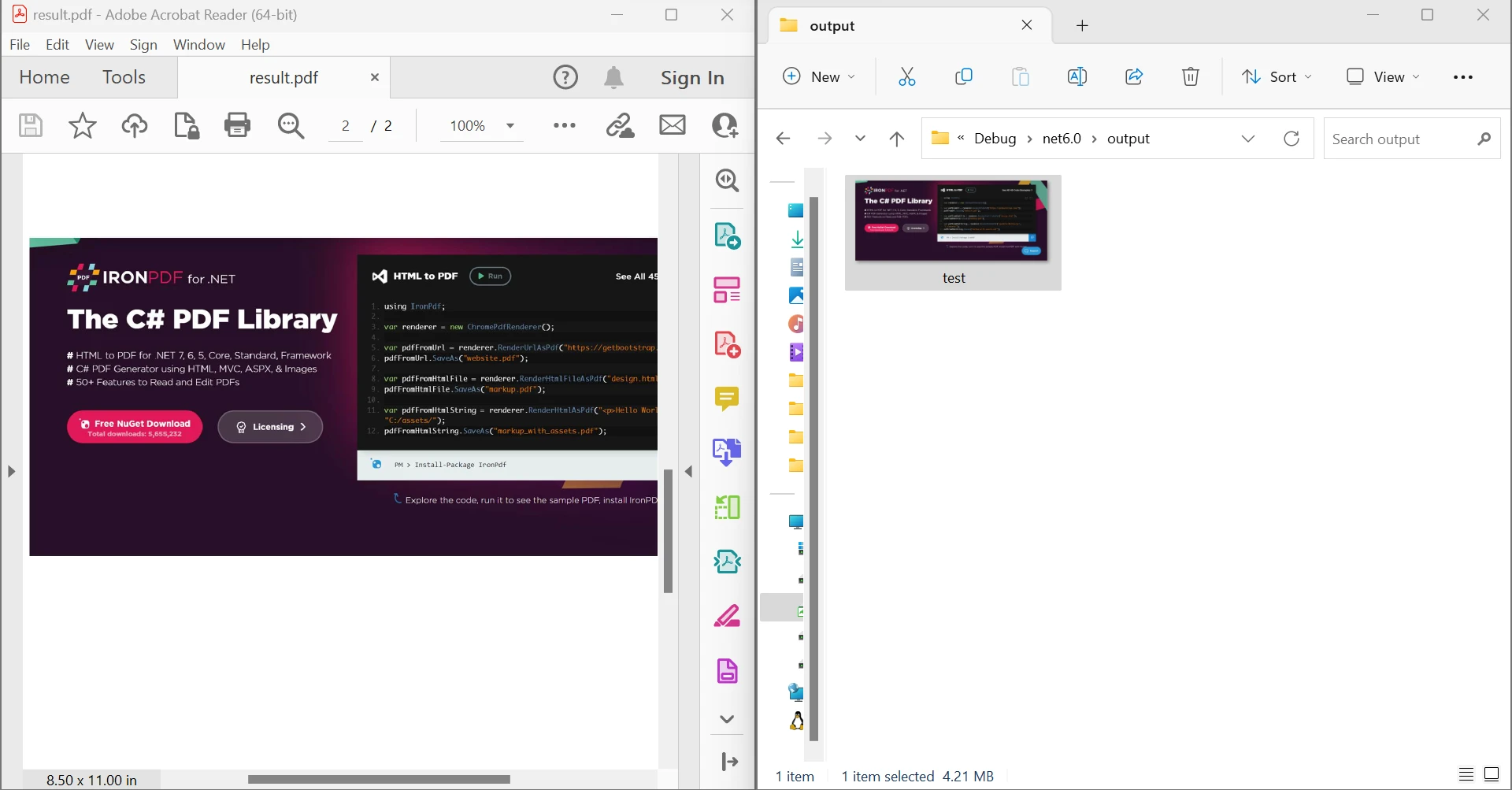 Salida de extracción de imágenes del PDF
Salida de extracción de imágenes del PDF
Para saber más sobre el tutorial de código API de IronPDF, consulta la documentación de IronPDF. También puedes visitar otros tutoriales para aprender cómo analizar texto PDF usando C#.
Conclusión
La licencia de desarrollo para la librería IronPDF es gratuita. Si se usa IronPDF en un ambiente de producción, se pueden comprar diferentes licencias según las necesidades del desarrollador. El plan Lite comienza en $999 y no tiene costos continuos. También se proporcionan alternativas de redistribución SaaS y OEM. Todas las licencias incluyen actualizaciones, un año de soporte del producto y una licencia permanente. También son útiles para fabricación, puesta en escena y desarrollo. Es una compra única. Hay licencias adicionales gratuitas, limitadas por tiempo, disponibles. Visita la información completa sobre licencias de IronPDF para leer los detalles completos de precios y licencias de IronPDF. IronPDF también proporciona licencias gratuitas para la protección contra copia.
Preguntas Frecuentes
¿Cómo puedo extraer texto de un PDF en VB.NET?
Usando la biblioteca IronPDF, puedes extraer texto de un PDF utilizando el método ExtractAllText. Esto te permite recuperar texto de todas las páginas de un documento PDF en tu proyecto VB.NET.
¿Es posible extraer imágenes de páginas específicas de un PDF usando VB.NET?
Sí, IronPDF te permite extraer imágenes de páginas específicas usando su método ExtractRawImagesFromPage. Este método devuelve los datos de imagen como matrices de bytes, que se pueden convertir en archivos de imagen.
¿Cómo puedo convertir contenido HTML en un documento PDF en VB.NET?
IronPDF ofrece una potente conversión de HTML a PDF utilizando el motor de renderizado Chromium. Puedes usar métodos como RenderHtmlAsPdf para convertir cadenas o archivos HTML en documentos PDF de manera eficiente.
¿Cuáles son los beneficios de usar IronPDF para parsear PDFs en aplicaciones VB.NET?
IronPDF proporciona APIs versátiles para extraer texto e imágenes, soporta la conversión de HTML a PDF, y es compatible con varias plataformas .NET, incluyendo ASP.NET, Windows Forms y Blazor. También ofrece diferentes opciones de licencia para satisfacer las necesidades de desarrollo y producción.
¿Cómo integro IronPDF en mi proyecto VB.NET?
Para integrar IronPDF, descarga la biblioteca desde NuGet y añádela a tu proyecto VB.NET. Esto te permitirá acceder a sus métodos para parsear y manipular archivos PDF programáticamente.
¿Puede IronPDF manejar tanto tareas de parseo como de conversión?
Sí, IronPDF está diseñado para manejar tanto tareas de parseo (extracción de texto e imágenes) como de conversión (como HTML a PDF) de manera eficiente, convirtiéndolo en una solución integral para la manipulación de PDF en VB.NET.
¿Qué opciones de licencia están disponibles para IronPDF?
IronPDF ofrece una licencia de desarrollo gratuita y varias licencias de producción, incluyendo Lite, SaaS y redistribución OEM. Estas licencias incluyen actualizaciones y soporte por un año, adaptándose a diferentes necesidades de proyecto.
¿Depende IronPDF de recursos externos para su funcionalidad?
No, IronPDF es autónomo y utiliza internamente el motor de renderizado Chromium, asegurando una funcionalidad robusta sin dependencia de recursos externos para la conversión y parseo de PDF.
¿IronPDF es compatible con .NET 10 y cómo beneficia a los desarrolladores de VB.NET?
Sí, IronPDF es totalmente compatible con .NET 10, así como con versiones anteriores como .NET 9, 8, 7, 6, Core, Standard y Framework. Esto significa que los proyectos VB.NET que utilizan .NET 10 pueden usar IronPDF sin necesidad de configuración adicional. Los desarrolladores se benefician de las nuevas mejoras de rendimiento en tiempo de ejecución de .NET 10, como la reducción de las asignaciones de montón, un mejor tiempo de ejecución y optimizaciones JIT, que optimizan la generación de PDF, la extracción de texto/imagen y la representación de HTML a PDF.












