Una Comparación Entre IronPDF Para Python & PyPDF
PDFs (Portable Document Format) son un formato de archivo ampliamente utilizado para preservar el diseño y formato de la información de documentos en diferentes plataformas. Son altamente populares en diversas industrias debido a su capacidad para mantener una apariencia consistente independientemente del dispositivo o sistema operativo utilizado para abrirlos. Los PDFs se emplean comúnmente para compartir informes, facturas, formularios, libros electrónicos, datos personalizados y otros documentos importantes.
Trabajar con archivos PDF en Python se ha convertido en un aspecto crucial de muchos proyectos. Python ofrece varias bibliotecas que simplifican la manipulación de archivos PDF, facilitando la extracción de información, creación de nuevos documentos, combinación o división de los existentes, y realizar otras tareas relacionadas con PDFs.
En este artículo, realizaremos una comparación exhaustiva de dos renombradas bibliotecas Python diseñadas para manipular archivos PDF: PyPDF e IronPDF. Al evaluar las características y capacidades de ambas bibliotecas, buscamos proporcionar a los desarrolladores valiosos insights que les ayuden a tomar una decisión consciente sobre cuál se adapta mejor a las necesidades específicas de su aplicación de software.
Estas bibliotecas ofrecen herramientas robustas para optimizar el trabajo con PDFs, empoderando a los desarrolladores para manejar documentos PDF eficientemente dentro de sus aplicaciones Python. Así que, profundicemos en la comparación y exploremos las fortalezas de cada biblioteca para facilitar tus tareas relacionadas con PDF.
PyPDF - Biblioteca PDF Pure Python
PyPDF es una biblioteca de PDF pura en Python que proporciona funcionalidades básicas para leer, escribir, descifrar archivos PDF y manipular documentos PDF. Permite a los desarrolladores extraer texto e imágenes de los PDFs, combinar múltiples archivos PDF, dividir PDFs grandes en más pequeños, y más. PyPDF es conocida por su simplicidad y facilidad de uso, haciéndola una elección adecuada para tareas PDF directas.
Proporciona un conjunto completo de características para trabajar con documentos PDF, haciéndola una elección excelente para un amplio rango de tareas relacionadas con PDF.
Características
PyPDF es una biblioteca de PDF en Python capaz de las siguientes características:
- Leer archivos PDF: Extraer texto, imágenes y metadatos de archivos PDF existentes.
- Escribir archivos PDF: Crear nuevos PDFs desde cero o modificar los existentes con texto e imágenes.
- Combinar archivos PDF: Unir múltiples archivos PDF en un único documento.
- Dividir archivos PDF: Dividir un PDF en archivos separados, cada uno conteniendo una o más páginas.
- Rotar y superponer páginas: Rotar páginas y añadir marcas de agua o superposiciones a PDFs.
- Encriptar y desencriptar archivos PDF: Añadir seguridad a los PDFs encriptándolos y desencriptándolos.
- Extraer texto: Obtener texto plano de PDFs o regiones específicas dentro de una página.
- Extraer imágenes: Recuperar imágenes incrustadas dentro de PDFs.
- Manipular archivos PDF: Copiar, eliminar o reorganizar páginas dentro de un archivo PDF.
- Relleno de campos de formulario: Completar campos de formulario en PDFs programáticamente.
IronPDF - Biblioteca PDF de Python
IronPDF es una biblioteca integral de manipulación de PDFs for Python, construida sobre la biblioteca .NET de IronPDF. Ofrece una potente API con capacidades avanzadas, como convertir HTML a PDF, manejar anotaciones y campos de formulario de PDF, y realizar operaciones complejas con PDFs eficientemente. IronPDF es preferida para proyectos que requieren un procesamiento robusto de PDFs, rendimiento y amplio soporte de características.
IronPDF es una biblioteca de PDF en Python capaz de manejar tareas de procesamiento de PDFs sin problemas. Proporciona una solución fiable y rica en funciones para la manipulación de PDFs para desarrolladores en Python. Con IronPDF, puedes generar, modificar y extraer contenido de múltiples páginas dentro de un PDF sin esfuerzo, convirtiéndola en una excelente opción para diversas aplicaciones relacionadas con PDFs.
Características
Aquí tienes algunas de las características prominentes de IronPDF:
- Generación de PDF: IronPDF permite a los desarrolladores crear documentos PDF desde cero o convertir contenido HTML en formato PDF, facilitando la generación de informes dinámicos y visualmente atractivos.
- Manipulación avanzada de texto e imágenes: Los desarrolladores pueden manipular fácilmente texto e imágenes dentro de archivos PDF. IronPDF ofrece funcionalidades para añadir, editar y formatear texto, así como insertar, redimensionar y posicionar imágenes con precisión.
- Combinación y división de PDF: IronPDF permite combinar múltiples archivos PDF en un solo documento y dividir un PDF en múltiples archivos separados, proporcionando flexibilidad en el manejo de contenido PDF.
- Soporte de formularios PDF: Con IronPDF, los desarrolladores pueden trabajar con formularios PDF, permitiéndoles completar campos de formulario, extraer datos de formulario y crear PDFs interactivos.
- Seguridad y encriptación de PDF: IronPDF ofrece características para añadir protección con contraseña y cifrado a documentos PDF, asegurando la seguridad y confidencialidad de los datos.
- Anotaciones en PDF: Los desarrolladores pueden añadir anotaciones como comentarios, resaltados y marcadores para mejorar la colaboración y legibilidad dentro de PDFs.
- Encabezado y pie de página: IronPDF permite añadir encabezados y pies de página a las páginas PDF, proporcionando marca y contexto al documento.
- Generación de códigos de barras: IronPDF facilita la generación de varios tipos de códigos de barras y códigos QR directamente en documentos PDF usando HTML.
- Alto rendimiento: Construido sobre la biblioteca .NET de IronPDF, IronPDF ofrece alto rendimiento y eficiencia en el manejo de archivos PDF grandes y operaciones complejas.
El artículo continúa de la siguiente manera:
- Crear un Proyecto en Python
- Instalación de PyPDF
- Instalación de IronPDF
- Crear Documentos PDF
- Combinar Archivos PDF
- Dividir Archivos PDF
- Extraer Texto de Archivos PDF
- Licencias
- Conclusión
1. Crear un proyecto Python
Usar un Entorno de Desarrollo Integrado (IDE) para proyectos en Python puede aumentar significativamente la productividad. Entre las opciones populares, voy a usar PyCharm, ya que destaca por su autocompletado inteligente de código, poderosa depuración e integración perfecta con sistemas de control de versiones. Si no lo tienes instalado, puedes descargarlo desde el sitio web de JetBrains PyCharm, o puedes usar cualquier IDE/editor de texto para programación en Python, como VS Code.
Para crear un proyecto en Python en PyCharm:
Inicia PyCharm y haz clic en "Create New Project" en la pantalla de bienvenida de PyCharm, o ve a File > New Project en el menú.
- Elige el intérprete de Python. Si no has configurado un intérprete, haz clic en el icono del engranaje y configúralo.
- Selecciona la ubicación y plantilla del proyecto.
Proporciona el nombre y configuraciones del proyecto, luego haz clic en Create.
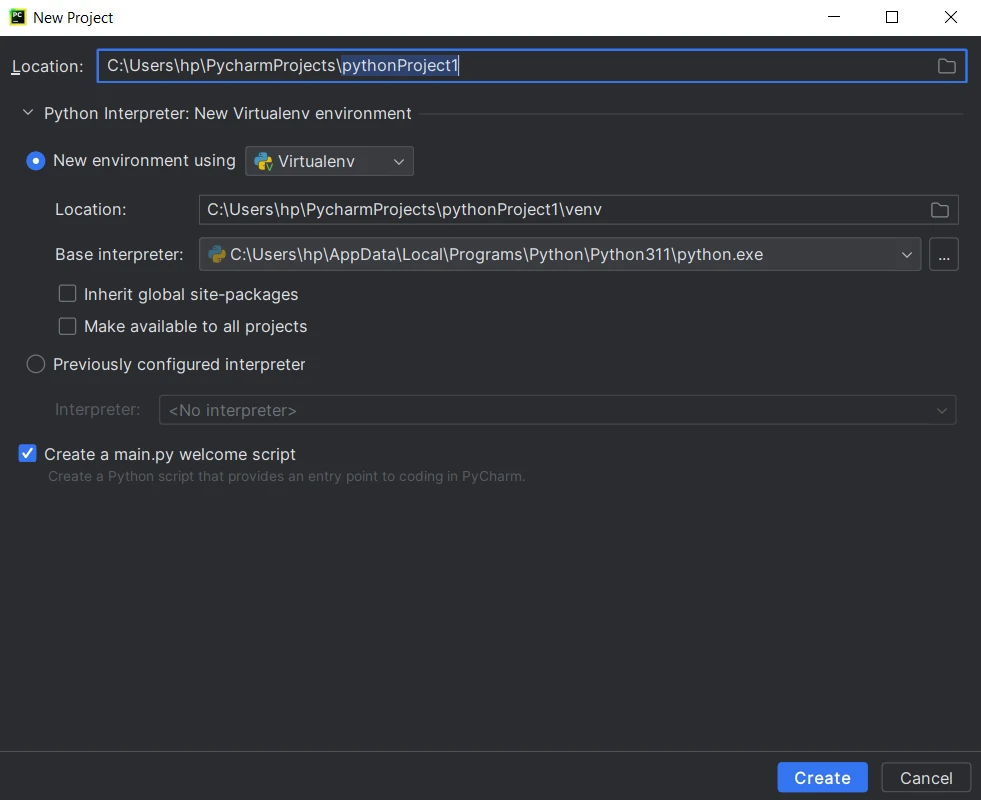
- Comienza a codificar, ejecutar y depurar tu proyecto en Python.
2. Instalación de PyPDF
PyPDF, una biblioteca pura en Python, puede ser instalada de diversas maneras. Podemos instalarla usando tanto el Símbolo del Sistema como PyCharm.
2.1. Uso del símbolo del sistema
- Abre el Símbolo del Sistema o terminal en tu computadora.
Para instalar PyPDF, usa el siguiente comando pip:
pip install pypdfpip install pypdfSHELL- Espera a que la instalación de PyPDF se complete. Deberías ver un mensaje de éxito indicando que PyPDF ha sido instalado.
Puedes usar el mismo proceso para instalar PyPDF en la Terminal de PyCharm.
Nota: Python debe ser añadido a la variable de entorno PATH del sistema.
2.2. Uso de PyCharm
- Abre PyCharm IDE.
- Crea un nuevo proyecto en Python o abre uno existente.
- Una vez dentro del proyecto, haz clic en File en el menú superior y selecciona Settings.
- En la ventana de configuraciones, navega a "Project:
" y haz clic en "Python Interpreter". En la ventana de Python Interpreter, haz clic en el icono "+" para añadir un nuevo paquete.
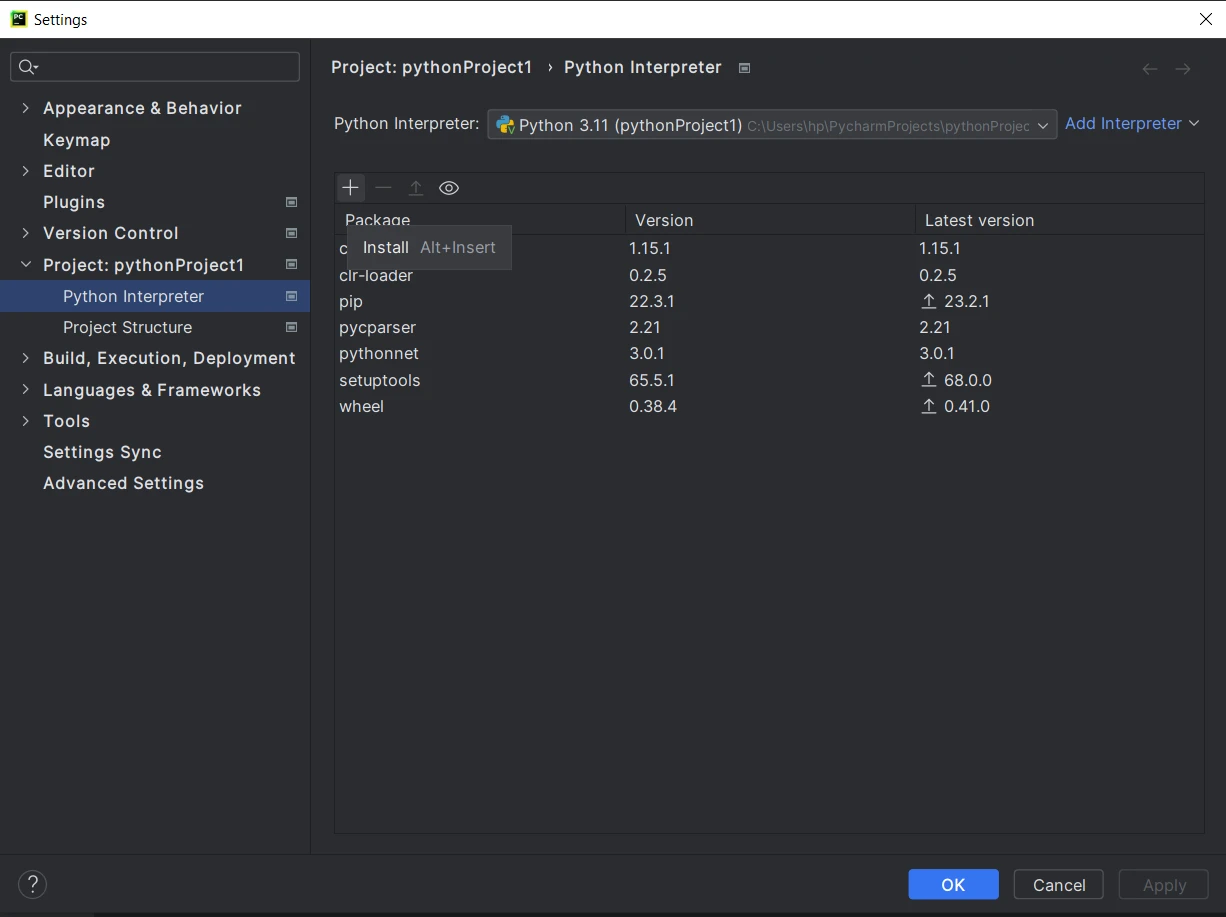
En la ventana "Available Packages", busca "PyPDF".
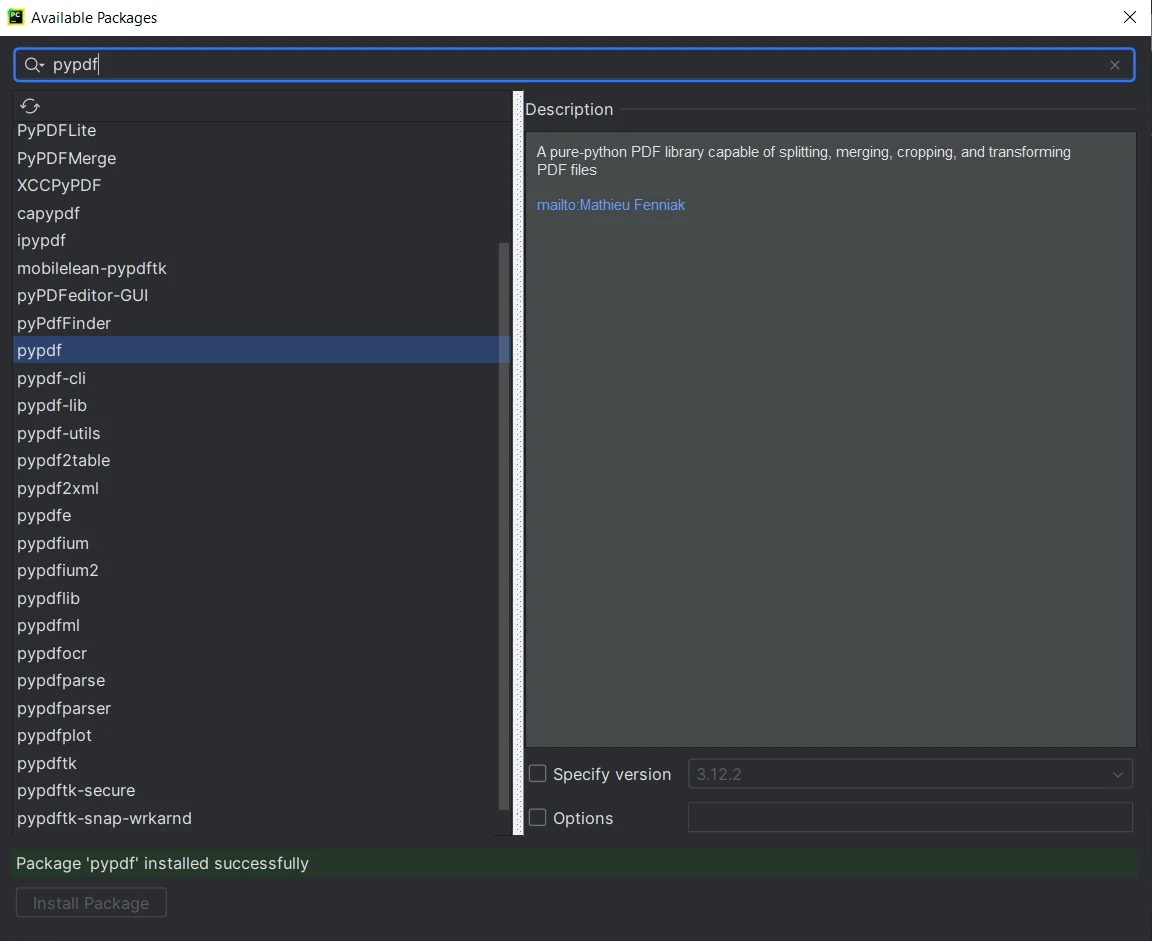
- Selecciona "PyPDF" de la lista y haz clic en el botón "Install Package".
- Espera a que PyCharm descargue e instale PyPDF.
3. Instalación de IronPDF
Requisitos previos
IronPDF for Python utiliza la potente tecnología .NET 6.0 como su base. Por lo tanto, para utilizar IronPDF for Python de manera efectiva, es esencial tener el runtime de .NET 6.0 instalado en tu sistema. Los usuarios de Linux y Mac pueden necesitar descargar e instalar .NET desde el sitio web oficial de Microsoft (https://dotnet.microsoft.com/en-us/download/dotnet/6.0) antes de proceder a trabajar con este paquete de Python. Asegurar la presencia del runtime de .NET 6.0 permitirá una integración sin problemas y un rendimiento óptimo al usar IronPDF for Python en tareas de procesamiento de PDFs.
3.1. Uso del símbolo del sistema
- Abre el Símbolo del Sistema o terminal en tu computadora.
Para instalar IronPDF, usa el siguiente comando pip:
pip install ironpdfpip install ironpdfSHELL- Espera a que la instalación se complete. Deberías ver un mensaje de éxito indicando que IronPDF ha sido instalado.
3.2. Uso de PyCharm
- Abre PyCharm IDE en tu computadora.
- Crea un nuevo proyecto en Python o abre uno existente.
- Una vez dentro del proyecto, haz clic en "File" en el menú superior y selecciona "Settings".
- En la ventana de configuraciones, navega a "Project:
" y haz clic en "Python Interpreter". - En la ventana de Python Interpreter, haz clic en el icono "+" para añadir un nuevo paquete.
Desde la ventana "Available Packages", busca "IronPDF".
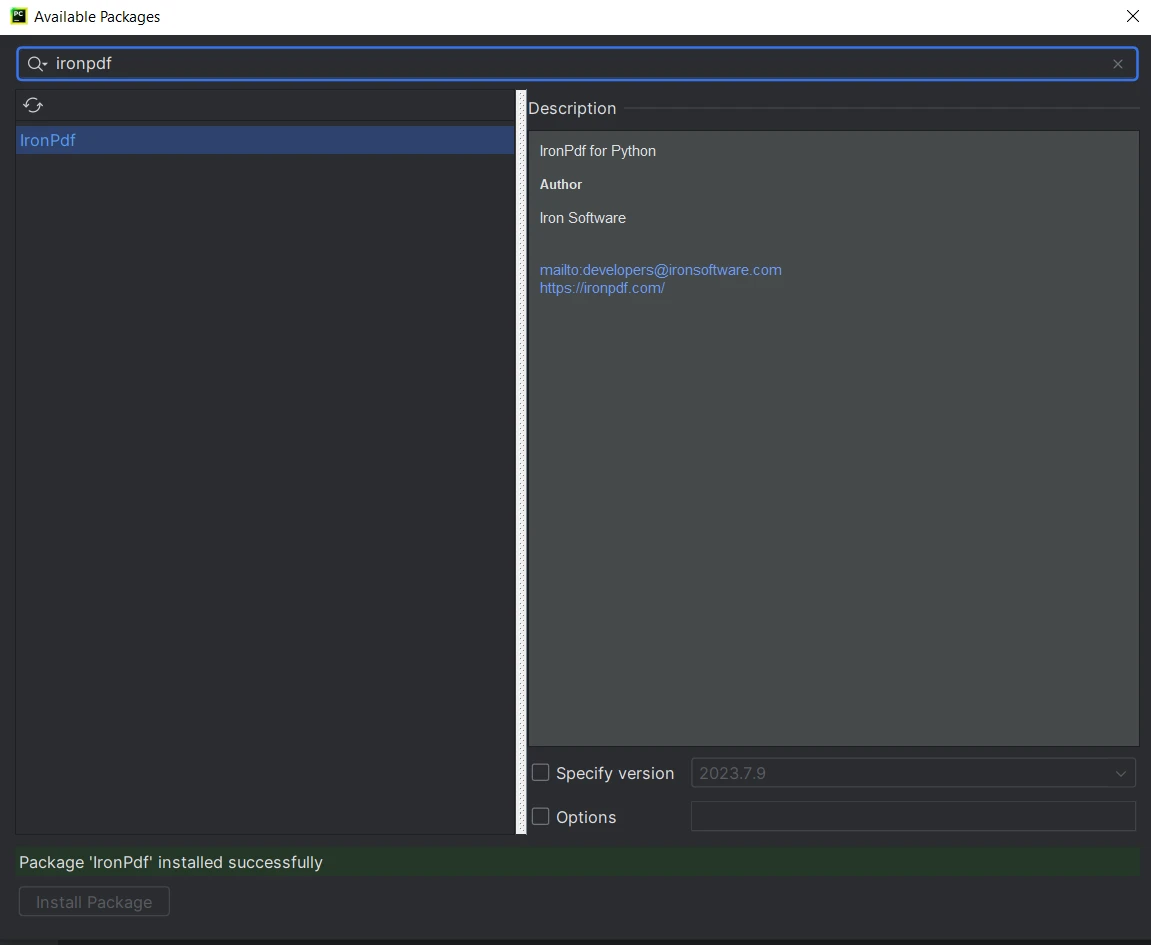
- Selecciona "IronPDF" de la lista y haz clic en el botón "Install Package".
- Espera a que IronPDF se descargue e instale. Aparecerá un mensaje de éxito indicando que IronPDF está instalado.
Ahora, ambas bibliotecas están instaladas y listas para usar. Pasemos a la comparación propiamente dicha.
4. Creación de documentos PDF
4.1. Uso de PyPDF
PyPDF proporciona capacidades básicas para crear nuevos archivos PDF. Sin embargo, no tiene un método integrado para convertir directamente contenido HTML a PDF. Para crear un nuevo PDF usando PyPDF, necesitamos añadir contenido a un PDF existente o crear un nuevo PDF en blanco y luego añadir texto o imágenes a él. El siguiente código ayuda a lograr esta tarea de creación de archivos PDF:
from pypdf import PdfWriter, PdfReader
# Create a new PDF file
pdf_output = PdfWriter()
# Add a new blank page
page = pdf_output.add_blank_page(width=610, height=842) # Width and height are in points (1 inch = 72 points)
# Read content from an existing PDF
with open('input.pdf', 'rb') as existing_pdf:
existing_pdf_reader = PdfReader(existing_pdf)
# Merge content from the first page of the existing PDF
page.merge_page(existing_pdf_reader.pages[0])
# Save the new PDF to a file
with open('output.pdf', 'wb') as output_file:
pdf_output.write(output_file)from pypdf import PdfWriter, PdfReader
# Create a new PDF file
pdf_output = PdfWriter()
# Add a new blank page
page = pdf_output.add_blank_page(width=610, height=842) # Width and height are in points (1 inch = 72 points)
# Read content from an existing PDF
with open('input.pdf', 'rb') as existing_pdf:
existing_pdf_reader = PdfReader(existing_pdf)
# Merge content from the first page of the existing PDF
page.merge_page(existing_pdf_reader.pages[0])
# Save the new PDF to a file
with open('output.pdf', 'wb') as output_file:
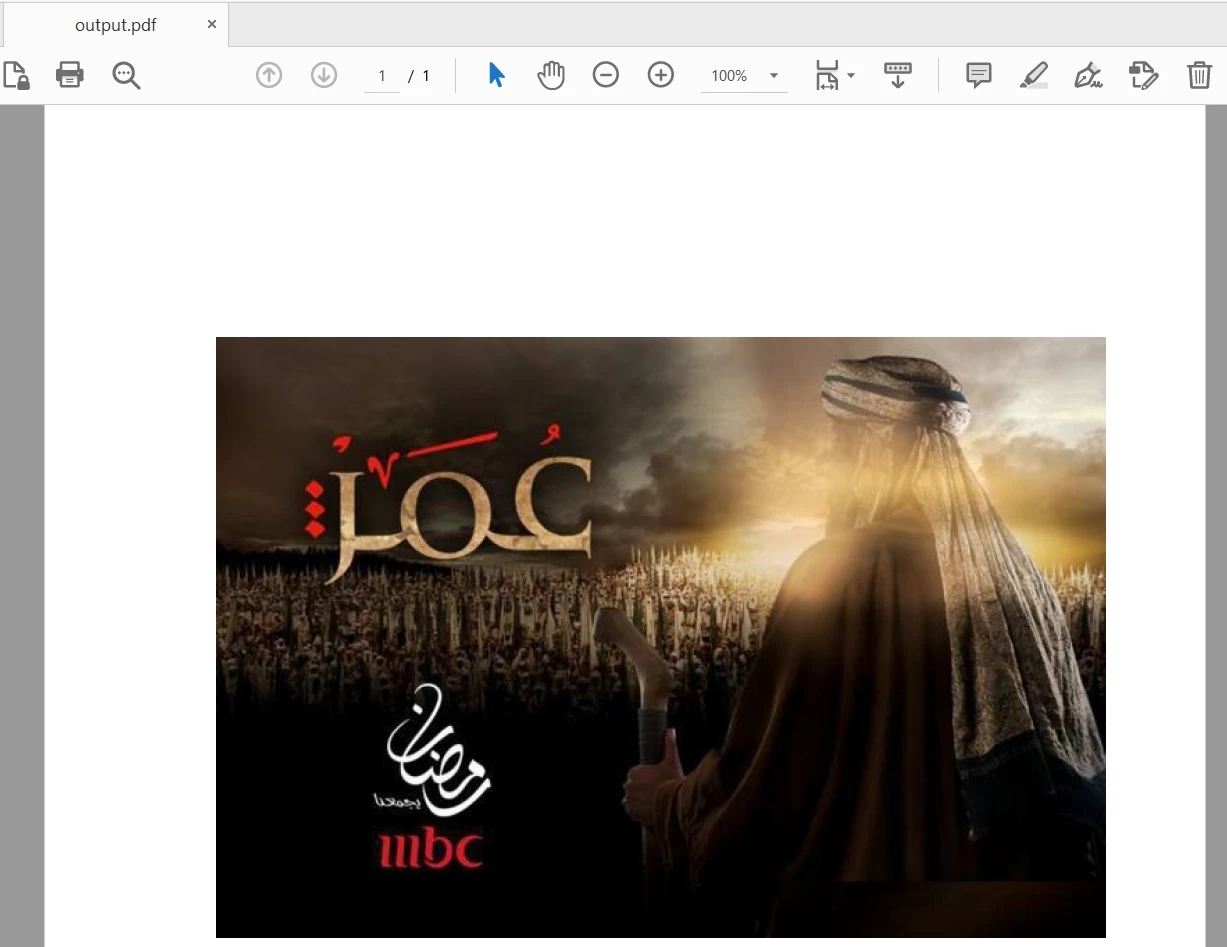
pdf_output.write(output_file)El archivo de entrada contiene 28 páginas y solo se añade la primera página al nuevo archivo PDF. La salida es la siguiente:
4.2. Uso de IronPDF
IronPDF ofrece capacidades avanzadas para crear nuevos archivos PDF directamente desde contenido HTML. Esto lo hace conveniente para generar informes y documentos dinámicos sin necesidad de pasos adicionales. Aquí está el código de ejemplo:
import ironpdf
# Set IronPDF license key to unlock full features
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Create a PDF from an HTML string using Python
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This PDF is created using IronPDF for Python</p>")
# Export to a file or stream
pdf.SaveAs("output.pdf")
# Advanced Example with HTML Assets
# Load external html assets Images, CSS, and JavaScript.
# An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
myAdvancedPdf.SaveAs("html-with-assets.pdf")import ironpdf
# Set IronPDF license key to unlock full features
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Create a PDF from an HTML string using Python
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This PDF is created using IronPDF for Python</p>")
# Export to a file or stream
pdf.SaveAs("output.pdf")
# Advanced Example with HTML Assets
# Load external html assets Images, CSS, and JavaScript.
# An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
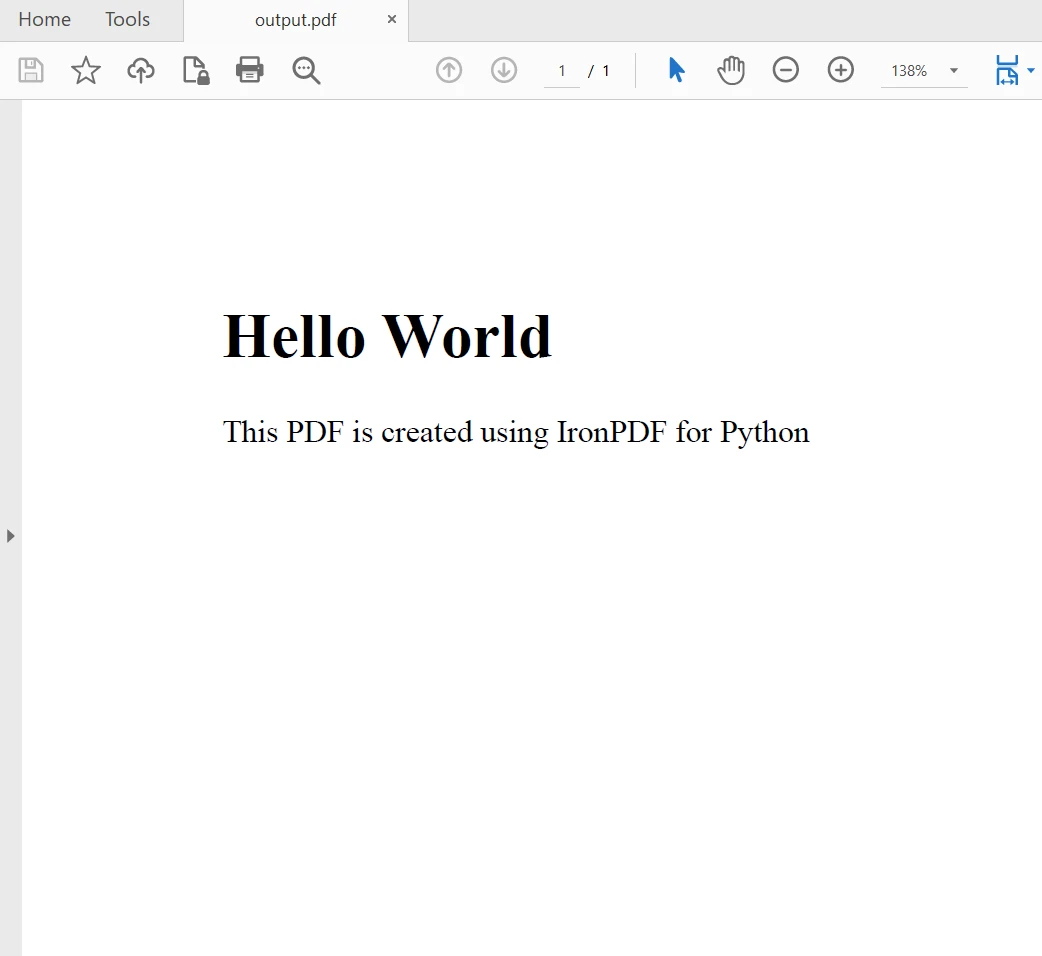
myAdvancedPdf.SaveAs("html-with-assets.pdf")En el código anterior, primero aplicamos la clave de licencia para utilizar todo el potencial de IronPDF. También puedes usarlo sin una clave de licencia, pero aparecerán marcas de agua en los archivos PDF creados. Luego, creamos dos documentos PDF, primero usando una cadena HTML como contenido y segundo usando activos. El resultado es el siguiente:
5. Fusión de archivos PDF
5.1. Uso de PyPDF
PyPDF permite combinar múltiples páginas/documentos en un solo PDF añadiendo páginas de un PDF a otro. Añade las rutas de entrada de todos los archivos PDF en la lista y usa el método append para combinar y generar un archivo único.
from pypdf import PdfWriter
merger = PdfWriter()
for pdf in ["file1.pdf", "file2.pdf", "file3.pdf"]:
merger.append(pdf)
merger.write("merged-pdf.pdf")
merger.close()from pypdf import PdfWriter
merger = PdfWriter()
for pdf in ["file1.pdf", "file2.pdf", "file3.pdf"]:
merger.append(pdf)
merger.write("merged-pdf.pdf")
merger.close()5.2. Uso de IronPDF
IronPDF también proporciona capacidades similares para combinar documentos en uno, facilitando la consolidación de contenido de diferentes fuentes PDF.
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
merged = ironpdf.PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
merged.SaveAs("Merged.pdf")import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
merged = ironpdf.PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
merged.SaveAs("Merged.pdf")6. Cómo dividir archivos PDF
6.1. Uso de PyPDF
PyPDF es una biblioteca en Python capaz de dividir un único PDF en múltiples PDFs separados, cada uno conteniendo una o más páginas.
from pypdf import PdfReader, PdfWriter
# Open the PDF file
pdf_file = open('input.pdf', 'rb')
# Create a PdfFileReader object
pdf_reader = PdfReader(pdf_file)
# Split each page into separate PDFs
for page_num in range(len(pdf_reader.pages)):
pdf_writer = PdfWriter()
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filename = f'page_{page_num + 1}_pypdf.pdf'
with open(output_filename, 'wb') as output_file:
pdf_writer.write(output_file)
# Close the PDF file
pdf_file.close()from pypdf import PdfReader, PdfWriter
# Open the PDF file
pdf_file = open('input.pdf', 'rb')
# Create a PdfFileReader object
pdf_reader = PdfReader(pdf_file)
# Split each page into separate PDFs
for page_num in range(len(pdf_reader.pages)):
pdf_writer = PdfWriter()
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filename = f'page_{page_num + 1}_pypdf.pdf'
with open(output_filename, 'wb') as output_file:
pdf_writer.write(output_file)
# Close the PDF file
pdf_file.close()El código anterior divide el documento PDF de 28 páginas para separarlo en páginas individuales y guardarlas como 28 nuevos archivos PDF.
6.2. Uso de IronPDF
IronPDF también proporciona capacidades similares para dividir PDFs, permitiendo a los usuarios dividir un único PDF en varios archivos PDF, cada uno con una sola página PDF. Nos permite dividir una página específica de un PDF con múltiples páginas. El siguiente código ayuda a dividir documentos en múltiples archivos:
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html = """<p> Hello Iron </p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# take the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# take the pages 2 & 3
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html = """<p> Hello Iron </p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# take the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# take the pages 2 & 3
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")Para obtener información detallada sobre IronPDF acerca de leer archivos PDF, rotar páginas PDF, recortar páginas, establecer contraseñas de propietario/usuario y otras opciones de seguridad, por favor visita esta página de ejemplos de código de IronPDF for Python.
7. Extracción de texto de archivos PDF
7.1. Uso de PyPDF
PyPDF proporciona un método directo para extraer texto de PDFs. Ofrece la clase PdfReader, que permite a los usuarios leer el contenido de texto del PDF.
from pypdf import PdfReader
reader = PdfReader("input.pdf")
page = reader.pages[0]
print(page.extract_text())from pypdf import PdfReader
reader = PdfReader("input.pdf")
page = reader.pages[0]
print(page.extract_text())7.2. Uso de IronPDF
IronPDF también admite la extracción de texto de archivos PDF mediante la clase PdfDocument. Proporciona un método llamado ExtractAllText para obtener el contenido de texto del PDF. Sin embargo, la versión gratuita de IronPDF solo extrae unos pocos caracteres del documento PDF. Para extraer el texto completo de los PDFs, IronPDF necesita estar licenciado. Aquí tienes el ejemplo de código para extraer contenido de archivos PDF:
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Load existing PDF document
pdf = ironpdf.PdfDocument.FromFile("input.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Load existing PDF document
pdf = ironpdf.PdfDocument.FromFile("input.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)Para aprender más sobre la extracción de texto, por favor visita este ejemplo de PDF a Texto en Python.
8. Licencias
PyPDF
PyPDF se distribuye bajo la Licencia MIT, que es una licencia de software de código abierto conocida por sus términos permisivos. La Licencia MIT permite a los usuarios usar, modificar, distribuir y sublicenciar libremente la biblioteca PyPDF sin ninguna restricción. No se requiere que los usuarios divulguen el código fuente de sus aplicaciones que usan PyPDF, haciendo que sea adecuada para proyectos personales y comerciales.
El texto completo de la Licencia MIT generalmente se incluye en el código fuente de PyPDF, y los usuarios pueden encontrarlo en el archivo "LICENSE" dentro de la distribución de la biblioteca. Adicionalmente, el repositorio de PyPDF en GitHub (https://github.com/py-pdf/pypdf) sirve como la fuente principal para acceder a la última versión de la biblioteca y su información de licencia asociada.
IronPDF
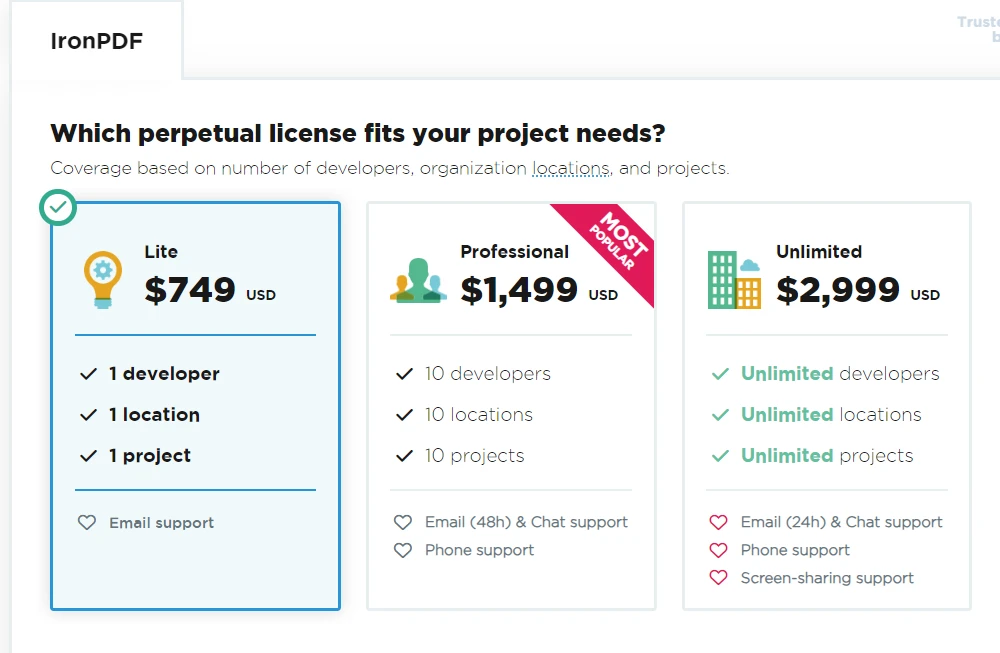
IronPDF es una biblioteca comercial y no es de código abierto. Es desarrollada y distribuida por Iron Software. El uso de IronPDF requiere una licencia válida de Iron Software. Hay diferentes tipos de licencias disponibles, incluyendo versiones de prueba para propósitos de evaluación y licencias pagas para uso comercial.
Como IronPDF es un producto comercial, ofrece características adicionales y soporte técnico en comparación con alternativas de código abierto. Para obtener una licencia para IronPDF, los usuarios pueden visitar el sitio web oficial para explorar las opciones de licenciamiento disponibles, precios y detalles de soporte. Su paquete Lite comienza desde NVIDIA_64_LICENSE y es una licencia perpetua.
9. Conclusión
Resumen
PyPDF es una poderosa y amigable biblioteca Python para trabajar con archivos PDF. Sus características para leer, escribir, combinar y dividir PDFs la convierten en una herramienta esencial para tareas de manipulación de PDFs. Ya sea que necesites extraer texto de un PDF, crear nuevos PDFs desde cero, o combinar y dividir documentos existentes, PyPDF proporciona una solución confiable y eficiente. Al aprovechar las capacidades de PyPDF, los desarrolladores de Python pueden optimizar sus flujos de trabajo relacionados con PDFs y aumentar su productividad.
IronPDF es una biblioteca de manipulación de PDFs integral y eficiente for Python, proporcionando una amplia gama de características para leer, crear, combinar y dividir archivos PDF. Ya sea que necesites generar reportes PDF dinámicos, extraer información de documentos de PDFs existentes, o combinar múltiples documentos, IronPDF ofrece una solución confiable y fácil de usar. Aprovechando las capacidades de IronPDF, los desarrolladores de Python pueden optimizar sus flujos de trabajo relacionados con PDFs y aumentar su productividad.
En comparación general, PyPDF es una biblioteca fácil de usar y ligera adecuada para operaciones básicas con PDFs. Es una buena elección para proyectos con requerimientos simples de PDFs. Por otro lado, IronPDF proporciona una API más extensa y robusto rendimiento, haciéndola ideal para proyectos que demandan capacidades avanzadas de procesamiento de PDFs, manejo de archivos PDF grandes y realización de tareas complejas.
Conclusión
Ambas bibliotecas ofrecen buenas facilidades de codificación para tareas comunes con PDFs. PyPDF es adecuada para operaciones simples e implementaciones rápidas, mientras que IronPDF proporciona una API más extensa y versátil para manejar tareas complejas relacionadas con PDFs.
En términos de rendimiento, es probable que IronPDF supere a PyPDF, especialmente cuando se trata de archivos PDF sustanciales o de tareas que requieren manipulaciones complejas de PDFs.
La elección entre ambas bibliotecas depende de las necesidades específicas del proyecto y la complejidad de las tareas relacionadas con PDFs involucradas.
IronPDF también está disponible para una prueba gratuita para probar su funcionalidad completa en modo comercial. Descarga IronPDF for Python desde aquí.
Preguntas Frecuentes
¿Cuáles son las principales diferencias entre PyPDF e IronPDF para la manipulación de PDF en Python?
PyPDF es una biblioteca de Python puro que ofrece funciones básicas de manipulación de PDF como lectura, escritura y fusión de PDFs. En contraste, IronPDF está construido sobre la biblioteca .NET de IronPDF y proporciona capacidades avanzadas como conversión de HTML a PDF, manejo de formularios y operaciones de alto rendimiento para tareas complejas de PDF.
¿Cómo puedo convertir HTML a PDF en Python?
Puedes convertir HTML a PDF en Python usando IronPDF. Proporciona métodos como RenderHtmlAsPdf para convertir cadenas de HTML y RenderHtmlFileAsPdf para convertir archivos HTML en PDFs.
¿Cuáles son los requisitos de instalación para usar IronPDF en un proyecto de Python?
Para usar IronPDF con Python, necesitas tener el runtime de .NET 6.0 instalado en tu sistema. IronPDF se puede instalar a través de pip usando el comando pip install ironpdf.
¿Es posible extraer texto e imágenes de PDFs usando PyPDF?
Sí, PyPDF permite la extracción de texto e imágenes de PDFs. Está diseñado para tareas básicas de manipulación de PDF como la extracción de texto, fusión y división de PDFs.
¿Cuáles son las ventajas de usar IronPDF para operaciones complejas de PDF?
IronPDF ofrece un rendimiento robusto y características extensivas para operaciones complejas de PDF, incluyendo conversión de HTML a PDF, manejo de formularios, manipulación avanzada de texto e imágenes, y alto rendimiento con archivos grandes.
¿Puedo fusionar y dividir archivos PDF usando IronPDF?
Sí, IronPDF proporciona funcionalidad para fusionar y dividir archivos PDF eficientemente, ofreciendo una solución integral para gestionar operaciones complejas de PDF dentro de aplicaciones de Python.
¿Cuáles son los casos de uso comunes de usar PDFs en diversas industrias?
Los PDFs son comúnmente usados para compartir documentos como informes, facturas, formularios y libros electrónicos a través de diversas industrias debido a su apariencia consistente en diferentes plataformas y dispositivos.
¿Cuáles son las opciones de licencia para IronPDF?
IronPDF es un producto comercial que requiere una licencia válida de Iron Software. Hay varias opciones de licencia disponibles, incluyendo versiones de prueba, para adecuarse a las diferentes necesidades de los proyectos.