
Cómo Leer Archivos PDF en Python
Los archivos PDF, o Archivos de Formato de Documento Portátil, se han convertido en un estándar universal para compartir documentos. Son ampliamente utilizados por su capacidad de preservar el diseño y formato de un documento. Sin embargo, trabajar con archivos PDF usando lenguajes de programación como Python puede ser un poco desafiante. Este artículo presenta IronPDF, una biblioteca PDF de Python que nos permite realizar varias operaciones con documentos PDF.
Librería PDF IronPDF for Python
IronPDF es una biblioteca PDF de Python avanzada que facilita el trabajo con archivos en formato PDF. Proporciona una API fácil de usar para varias operaciones PDF. Puedes leer y escribir archivos PDF, convertir archivos PDF a diferentes formatos, combinar múltiples archivos PDF, y mucho más. También puede manejar objetos de página, extraer texto de todas las páginas del archivo PDF y rotar páginas PDF, entre otras funcionalidades.
Cómo leer archivos PDF en Python
- Instala la Biblioteca PDF de Python usando Pip.
- Importa la Biblioteca PDF de Python en el Script de Python.
- Aplica la Clave de Licencia de la Biblioteca PDFReader de Python.
- Carga cualquier Documento PDF proporcionando la ruta del documento.
- Lee Contenido PDF en la Consola de Python.
Leer un archivo PDF con IronPDF
Leer un archivo PDF usando IronPDF implica varios pasos. Aquí tienes una guía simple para empezar:
Paso 1 Crear un entorno virtual en Visual Studio
Cuando trabajas con Python, es crucial crear un entorno aislado conocido como entorno virtual. Este entorno te permite gestionar dependencias específicas del proyecto en el que estás trabajando sin interferir con otros proyectos. Crear un entorno virtual se vuelve aún más sencillo en un Entorno de Desarrollo Integrado (IDE) como Visual Studio Code. Para hacer esto, sigue los pasos a continuación:
Abre la carpeta en Visual Studio Code. Presiona Ctrl+Shift+P para abrir la Paleta de Comandos. En la Paleta de Comandos, busca "Python: Crear Entorno".

Selecciona la primera opción, y luego elige "Venv" como el tipo de entorno.

Después, selecciona el intérprete de Python, y comenzará a crear el entorno virtual.

Ahora tienes tu espacio de trabajo aislado listo para tus scripts de Python, asegurando que las dependencias del proyecto estén confinadas dentro de este entorno.
![]()
Paso 2 Instalar la librería IronPDF for Python
Con el entorno virtual configurado, estás listo para instalar la biblioteca IronPDF for Python. Puedes instalarlo usando el instalador de paquetes de Python 'pip':
pip install ironpdfpip install ironpdfPaso 3 Instalar .NET 6.0
IronPDF for Python requiere que el SDK de .NET 6.0 esté instalado.
Por favor descarga e instala el SDK de .NET 6.0 desde el Sitio Web de Microsoft .NET.
Paso 4 Importar IronPDF
Después de instalar IronPDF correctamente, el siguiente paso es importarlo en tu script de Python. Importar la biblioteca hace que todas sus funciones y métodos estén disponibles para su uso en tu script. Puedes importar IronPDF usando la siguiente línea de código:
from ironpdf import *from ironpdf import *Esta línea de código importa todos los módulos, funciones y clases disponibles en la biblioteca IronPDF en tu script.
Paso 5 Aplicar clave de licencia
Para desbloquear completamente las capacidades de la biblioteca IronPDF, necesitas aplicar una clave de licencia. Aplicar una clave de licencia es tan simple como asignar la clave a la propiedad LicenseKey de la clase License. Aquí te indicamos cómo hacerlo:
License.LicenseKey = "License-Key-Here"License.LicenseKey = "License-Key-Here"Reemplace "License-Key-Here" con su clave de licencia actual de IronPDF . Con la clave de licencia en su lugar, ahora estás listo para aprovechar todo el potencial de la biblioteca IronPDF en tus scripts de Python.
Paso 6 Establecer ruta de registro
A continuación, configura el registro para operaciones de IronPDF. Estableciendo una ruta de registro personalizada, puedes almacenar los registros de ejecución que genera la biblioteca, ayudándote a depurar y diagnosticar problemas que puedan ocurrir durante la ejecución. Aquí tienes cómo configurarlo:
# Enable debugging mode for detailed logs
Logger.EnableDebugging = True
# Set the path for the log file
Logger.LogFilePath = "Custom.log"
# Set logging mode to capture all log types
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging mode for detailed logs
Logger.EnableDebugging = True
# Set the path for the log file
Logger.LogFilePath = "Custom.log"
# Set logging mode to capture all log types
Logger.LoggingMode = Logger.LoggingModes.AllEn este fragmento, Logger.EnableDebugging = True activa la depuración, Logger.LogFilePath = "Custom.log" establece el archivo de registro de salida en "Custom.log" y Logger.LoggingMode = Logger.LoggingModes.All garantiza que se registren todos los tipos de información de registro.
Paso 7 Cargar documento PDF
Cargar un documento PDF con IronPDF es tan fácil como llamar a un método. El método PdfDocument.FromFile carga el documento PDF desde la ruta indicada en un objeto de archivo PDF. Solo necesitas proporcionar la ruta del archivo PDF como una cadena:
pdf = PdfDocument.FromFile("PDF B.pdf")pdf = PdfDocument.FromFile("PDF B.pdf")En este código, pdf se convierte en un objeto PdfDocument que representa el archivo PDF especificado.
Paso 8 Leer el contenido del archivo PDF
IronPDF proporciona un método llamado ExtractAllText() que ayuda a extraer contenido de texto del documento PDF . Esto es especialmente útil cuando necesitas leer y analizar el contenido de un archivo PDF:
all_text = pdf.ExtractAllText() # Extracts all text from the PDF document
print(all_text) # Prints the extracted text to the consoleall_text = pdf.ExtractAllText() # Extracts all text from the PDF document
print(all_text) # Prints the extracted text to the consoleEn este ejemplo, all_text contendrá todo el texto del archivo PDF del objeto pdf. Podrás leer contenido PDF en la consola.
Paso 9 Cargar segundo archivo PDF
Al igual que cargaste el primer documento PDF, también puedes cargar un segundo documento PDF. Esta función es útil cuando deseas manipular múltiples archivos PDF:
pdf_2 = PdfDocument.FromFile("PDF A.pdf")pdf_2 = PdfDocument.FromFile("PDF A.pdf")En este código, pdf_2 es otro objeto PdfDocument que representa el segundo archivo PDF.
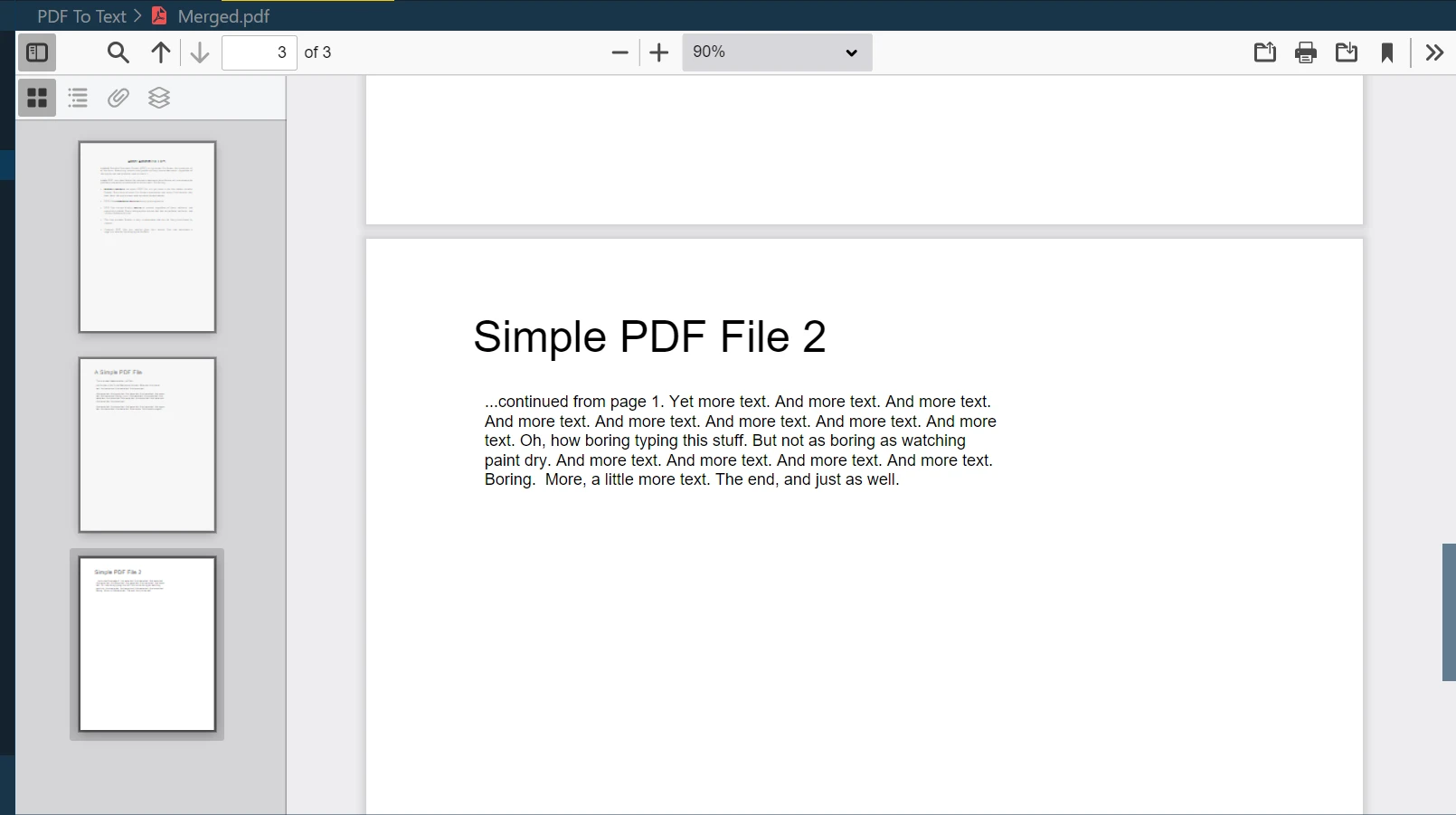
Paso 10 Fusionar ambos archivos
Una de las potentes funciones de IronPDF es la fusión de varios archivos PDF en uno solo. Puede combinar fácilmente dos o más documentos PDF con el método PdfDocument.Merge:
merged = PdfDocument.Merge(pdf, pdf_2) # Merges pdf and pdf_2 documents
merged.SaveAs("Merged.pdf") # Saves the merged document as 'Merged.pdf'merged = PdfDocument.Merge(pdf, pdf_2) # Merges pdf and pdf_2 documents
merged.SaveAs("Merged.pdf") # Saves the merged document as 'Merged.pdf'En este ejemplo, merged es un nuevo objeto PdfDocument que es el resultado de fusionar pdf y pdf_2. Luego, el método SaveAs guarda este documento fusionado con el nombre "Merged.pdf".
Paso 11 Dividir el primer PDF
IronPDF también te permite dividir un documento PDF y extraer páginas específicas en nuevos archivos PDF. Esto se hace utilizando el método CopyPage:
page1doc = pdf.CopyPage(0) # Copies the first page of the pdf document
page1doc.SaveAs("Split1.pdf") # Saves the copied page as a new document 'Split1.pdf'page1doc = pdf.CopyPage(0) # Copies the first page of the pdf document
page1doc.SaveAs("Split1.pdf") # Saves the copied page as a new document 'Split1.pdf'Aquí, page1doc es un nuevo objeto PdfDocument que contiene la primera página del documento pdf. Esta página luego se guarda como un archivo PDF de salida llamado "Split1.pdf".

Paso 12 Aplicar marca de agua
La marca de agua es otra característica impresionante ofrecida por IronPDF. Puedes marcar con agua tu documento PDF con el texto o imagen que desees. El método ApplyWatermark se utiliza para agregar una marca de agua al PDF representado por el objeto pdf.
pdf.ApplyWatermark("<h2 style='color:red'>SAMPLE</h2>", 30, VerticalAlignment.Middle, HorizontalAlignment.Center)
pdf.SaveAs("Watermarked.pdf")pdf.ApplyWatermark("<h2 style='color:red'>SAMPLE</h2>", 30, VerticalAlignment.Middle, HorizontalAlignment.Center)
pdf.SaveAs("Watermarked.pdf")En este fragmento, ApplyWatermark aplica una marca de agua roja con el texto "SAMPLE" en el centro del PDF. Luego, SaveAs guarda el documento con marca de agua como "Watermarked.pdf".
Compatibilidad con IronPDF
IronPDF es una biblioteca de Python versátil compatible con una amplia gama de versiones de Python. Soporta todas las versiones modernas de Python desde Python 3.6 en adelante. IronPDF no está restringido a un solo sistema operativo. Es independiente de la plataforma, y por lo tanto se puede usar en una variedad de sistemas operativos. Ya sea Windows, Mac o Linux, IronPDF funciona sin problemas en estas plataformas. Esta compatibilidad multiplataforma es una gran ventaja, haciendo de IronPDF una elección preferida para los desarrolladores independientemente de sus preferencias de sistema operativo.
Conclusión
En conclusión, IronPDF es una excelente biblioteca de Python que simplifica el tratamiento de documentos PDF. Ya sea que necesites fusionar múltiples PDFs, extraer texto, dividir archivos PDF o aplicar marcas de agua, IronPDF te cubre. Su compatibilidad con múltiples plataformas y su facilidad de uso lo convierten en una herramienta valiosa para cualquier desarrollador que trabaje con documentos PDF.
IronPDF ofrece una prueba gratuita. Este período de prueba te da amplia oportunidad para experimentar con sus funcionalidades y evaluar su adecuación para tus necesidades específicas. Una vez que lo hayas probado, puedes comprar una licencia a partir de $799.
















