
Cómo Extraer Datos de Facturas De Un PDF en Python
Este artículo discutirá cómo puedes extraer datos de texto de archivos PDF de facturas utilizando la biblioteca IronPDF for Python.
Cómo extraer datos de facturas de un PDF en Python
- Instala la biblioteca de Python para extraer datos de facturas PDF.
- Utilice el método
PdfDocument.FromFilepara abrir un archivo PDF. - Extraiga todos los datos de la factura utilizando el método
ExtractAllText. - Utilice el método
printpara imprimir todos los datos extraídos de la factura. - Extrae datos específicos de los datos de la factura.
1. IronPDF
IronPDF for Python es una robusta biblioteca que usa Python y sirve como un puente entre aplicaciones Python y documentos PDF. Esta herramienta versátil proporciona a los desarrolladores los medios para crear, manipular e interactuar fácilmente con archivos PDF dentro de sus proyectos en Python. Aquí hay algunas de las características destacadas que hacen de IronPDF un activo valioso:
- Generación de PDF: IronPDF permite la generación dinámica de archivos PDF desde cero, permitiendo a los desarrolladores crear programáticamente PDFs con contenido, estilo y diseño personalizados.
- Conversión de HTML a PDF: Puede convertir contenido HTML, incluidas páginas web, a PDFs de alta calidad, preservando el diseño y estilo del HTML original, lo cual es especialmente útil para generar informes y documentación.
- Edición de PDF: Los desarrolladores pueden editar fácilmente PDFs existentes agregando, modificando o eliminando texto, imágenes y elementos interactivos, convirtiéndolo en una poderosa herramienta para la manipulación de documentos.
- Fusión y División de PDF: IronPDF te permite fusionar múltiples documentos PDF en un solo archivo o dividir un PDF en múltiples archivos, proporcionando flexibilidad en la gestión de grandes conjuntos de PDFs.
- Formularios PDF: Soporta la creación y llenado de formularios PDF interactivos, lo que lo hace ideal para aplicaciones que requieren la entrada del usuario y la recopilación de datos.
- Firmas Digitales: Puedes añadir firmas digitales a documentos PDF, asegurando la integridad y autenticidad de tus archivos, lo cual es vital para propósitos legales y de seguridad.
- Extracción de Datos de PDF: IronPDF ofrece capacidades de extracción para proteger la información dentro de los PDFs.
2. Configuración del entorno
Configurar el entorno para IronPDF en Python implica algunos pasos para asegurar que puedas comenzar a usar la biblioteca de manera efectiva. Aquí hay una guía paso a paso:
- Crea un nuevo proyecto Python en PyCharm y crea un entorno virtual o utiliza un Intérprete existente.
- Instala IronPDF utilizando la terminal de línea de comandos ejecutando el siguiente comando en la terminal:
pip install ironpdf
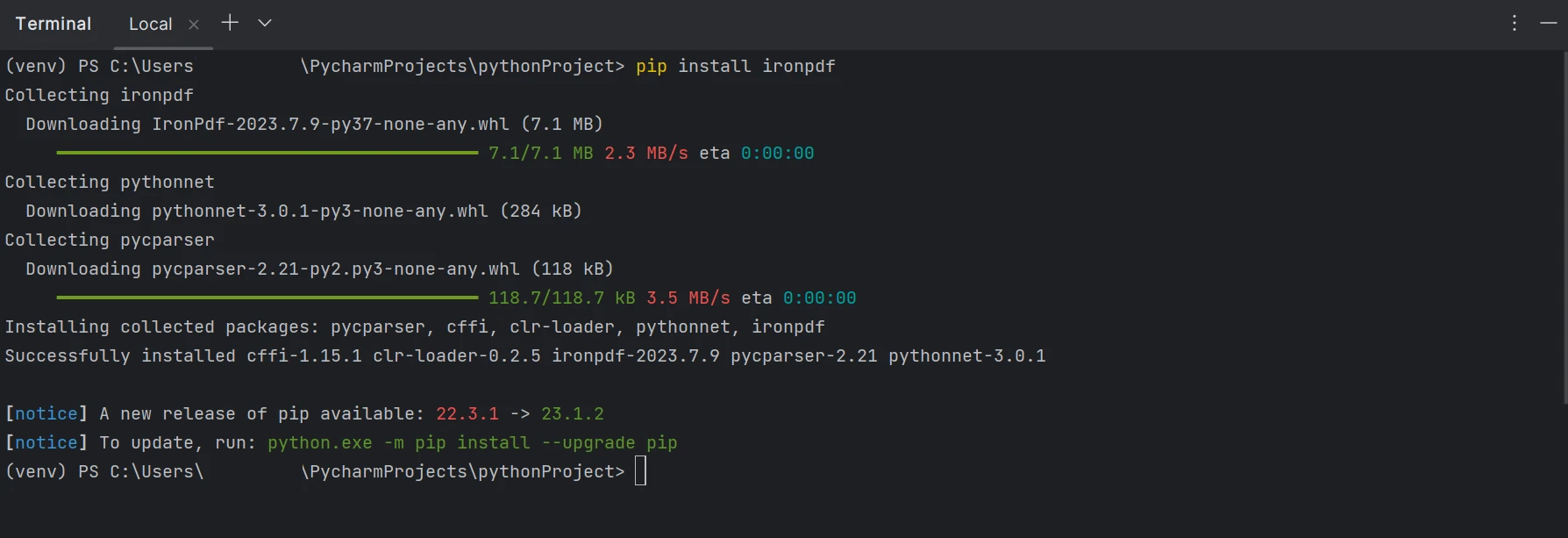 IronPDF siendo instalado desde la línea de comandos
IronPDF siendo instalado desde la línea de comandos
3. Extraer datos de una factura con IronPDF
Esta sección verá cómo extraer datos del formato de factura y formato de salida utilizando la biblioteca de Python IronPDF. El código a continuación extraerá todos los datos de la factura y los imprimirá en la consola.
Factura de ejemplo
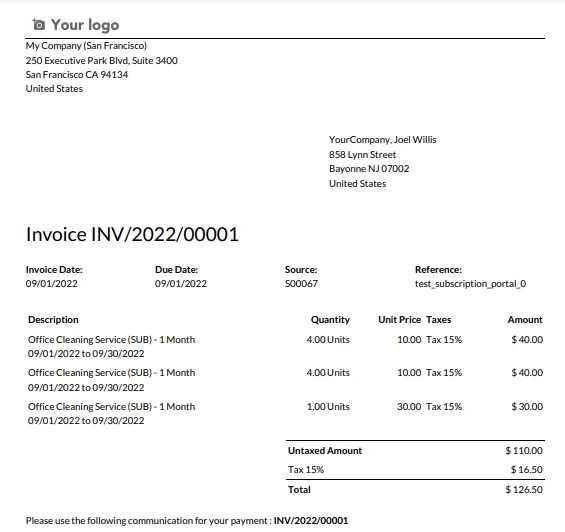 La factura de muestra
La factura de muestra
from ironpdf import PdfDocument
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import PdfDocument
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)El código anterior carga un archivo PDF específico llamado "INV_2022_00001.pdf" utilizando el método PdfDocument.FromFile. Posteriormente, extrae todo el contenido de texto del documento PDF cargado y lo almacena en la variable all_text. Finalmente, el texto extraído se imprime en la consola mediante la función print. Esencialmente, este código automatiza el proceso de extraer datos de texto estructurado y no estructurado de un archivo PDF, haciéndolos accesibles para un procesamiento o análisis adicional en un entorno de Python.
3.1. Salida
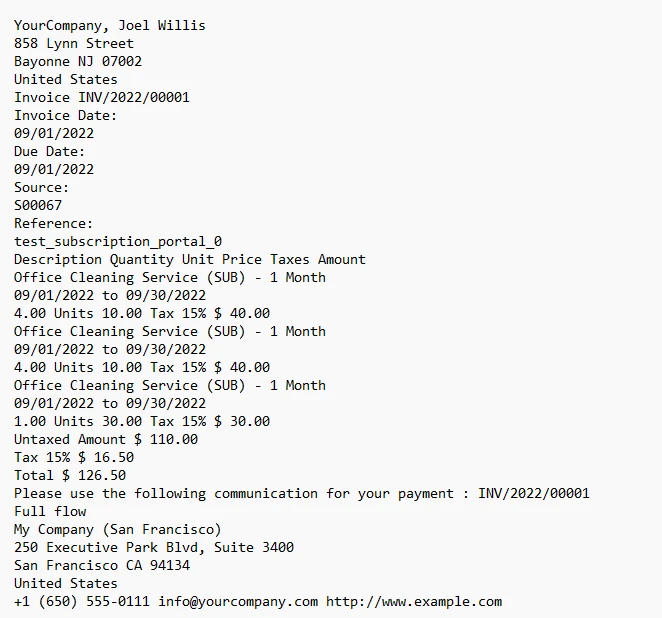 El texto de la factura en la salida de la consola
El texto de la factura en la salida de la consola
4. Extraer datos específicos de una factura
Usar IronPDF para extraer datos de facturas es un proceso bastante sencillo. Extraer datos como el número de factura y el monto de los datos de la factura en PDF puede ser un proceso complicado, pero utilizando IronPDF junto con la biblioteca de código abierto Python re, se puede lograr. El código a continuación extraerá datos específicos de facturas PDF y los imprimirá en la consola.
from ironpdf import PdfDocument
import re
# Define regex patterns to find invoice number and amount
invoice_number_pattern = r"Invoice\s+(INV/\d{4}/\d{5})"
amount_pattern = r"Total\s+\$\s*([\d,.]+(?:\.\d{2})?)"
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Search for the invoice number and amount in text
invoice_number_match = re.search(invoice_number_pattern, all_text)
amount_match = re.search(amount_pattern, all_text)
# Extract the matching groups if matches are found
invoice_number = invoice_number_match.group(1) if invoice_number_match else "Not found"
amount = amount_match.group(1) if amount_match else "Not found"
# Print the extracted data
print('Invoice Number: ' + invoice_number + '\nAmount: $' + amount)from ironpdf import PdfDocument
import re
# Define regex patterns to find invoice number and amount
invoice_number_pattern = r"Invoice\s+(INV/\d{4}/\d{5})"
amount_pattern = r"Total\s+\$\s*([\d,.]+(?:\.\d{2})?)"
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Search for the invoice number and amount in text
invoice_number_match = re.search(invoice_number_pattern, all_text)
amount_match = re.search(amount_pattern, all_text)
# Extract the matching groups if matches are found
invoice_number = invoice_number_match.group(1) if invoice_number_match else "Not found"
amount = amount_match.group(1) if amount_match else "Not found"
# Print the extracted data
print('Invoice Number: ' + invoice_number + '\nAmount: $' + amount)Este fragmento de código utiliza Python y la biblioteca IronPDF para realizar la extracción de datos de un documento PDF. Comienza importando las bibliotecas necesarias y definiendo patrones de expresiones regulares para identificar un número de factura y un monto total dentro del contenido de texto del PDF. Luego, el código carga el PDF objetivo, extrae todo su texto y procede a buscar coincidencias de los patrones definidos.
Si se encuentran coincidencias exitosas, almacena los valores correspondientes para el número de factura y el monto; de lo contrario, asigna "No encontrado". Finalmente, el script imprime el número de factura y el monto extraídos en la consola, proporcionando una manera optimizada de automatizar la extracción de datos específicos de documentos PDF, tarea comúnmente encontrada en diversas aplicaciones de procesamiento de datos y contabilidad.
4.1. Salida
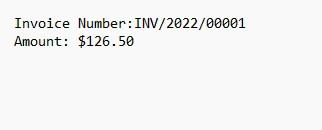 El texto de salida
El texto de salida
5. Conclusión
En el acelerado panorama empresarial actual, Python se erige como un aliado formidable para las organizaciones que buscan optimizar sus operaciones financieras automatizando la extracción de datos cruciales de las facturas PDF. Aprovechando las capacidades de Python y la biblioteca IronPDF, las empresas pueden reducir significativamente la entrada manual de datos, mitigar errores, ahorrar tiempo y mejorar la productividad general en el proceso contable de gestión de facturas. IronPDF, con sus versátiles características, como generación de PDF, conversión de HTML a PDF, edición de PDF, fusión, división, manejo de formularios, firmas digitales y extracción precisa de datos, se presenta como una poderosa herramienta para estas tareas.
Siguiendo procedimientos simples de configuración, los desarrolladores de Python pueden integrar rápidamente IronPDF en sus proyectos, revolucionando sus flujos de trabajo de procesamiento de facturas y convirtiendo la extracción de datos de facturas en un proceso fluido y eficiente. El ejemplo de código de extracción de datos usando IronPDF se puede encontrar en el ejemplo de código detallado. El tutorial completo sobre extracción de datos utilizando IronPDF for Python está disponible en el siguiente tutorial de Python, y para la Extracción de Facturas usando C#, visita el tutorial de IronOCR.
Preguntas Frecuentes
¿Cómo puedo extraer texto de una factura PDF usando Python?
Puede usar el método PdfDocument.FromFile de IronPDF para cargar el PDF y el método ExtractAllText para recuperar todo el contenido de texto del documento.
¿Cómo instalo IronPDF for Python?
Instale IronPDF usando el administrador de paquetes de Python pip con el comando pip install ironpdf.
¿Puedo extraer datos específicos, como números de factura, de PDFs con Python?
Sí, usando IronPDF en combinación con la biblioteca re de Python, puede definir patrones regex para extraer datos específicos como números de factura y cantidades de facturas en PDF.
¿Cuáles son las características de IronPDF for Python?
IronPDF ofrece características como generación de PDF, conversión de HTML a PDF, edición de PDF, fusión, división, manejo de formularios, firmas digitales y extracción de datos.
¿Puede IronPDF convertir HTML a PDF en Python?
Sí, IronPDF puede convertir contenido HTML, incluidas páginas web, en PDFs de alta calidad, preservando el diseño y estilo del HTML original.
¿Cómo mejora IronPDF la productividad en la extracción de datos de facturas?
IronPDF automatiza la extracción de datos de facturas en PDF, reduciendo la entrada manual y los errores, ahorrando tiempo y mejorando la productividad en operaciones financieras.
¿Es posible editar documentos PDF usando IronPDF en Python?
Sí, IronPDF permite a los desarrolladores editar PDFs existentes añadiendo, modificando o eliminando texto, imágenes y elementos interactivos.
¿Puede IronPDF combinar o dividir documentos PDF en Python?
Sí, IronPDF proporciona funciones para combinar múltiples documentos PDF en un solo archivo o dividir un PDF en múltiples archivos.
¿IronPDF admite la adición de firmas digitales a PDFs en Python?
Sí, IronPDF permite añadir firmas digitales a documentos PDF, asegurando la integridad y autenticidad de sus archivos.
¿Por qué se considera IronPDF una herramienta robusta para los desarrolladores de Python?
IronPDF se considera robusta debido a sus amplias capacidades para manejar diversas operaciones en PDF, incluidas la generación, conversión, edición y extracción de datos, que son esenciales para los desarrolladores.
















