
PyWriter de PDF en Python (Tutorial de Ejemplo de Código)
IronPDF es una biblioteca de objetos de archivos PDF pura de Python para desarrolladores de Python que buscan escribir archivos PDF o manipular archivos PDF dentro de sus aplicaciones. IronPDF se destaca por su simplicidad y versatilidad, lo que lo convierte en una elección ideal para tareas que requieren creación automática de PDF o integración de generación de PDF en sistemas de software.
Esta guía explorará cómo IronPDF, una biblioteca de PDF pura de Python, puede ser usada para crear archivos PDF o atributos de página PDF y leer archivos PDF. Incluirá ejemplos y fragmentos de código práctico, proporcionándole una comprensión práctica de cómo usar IronPDF for Python's PdfWriter en sus proyectos de Python para escribir archivos PDF y crear una nueva página PDF.
Configuración de IronPDF
Instalación
Para comenzar a usar IronPDF, necesitarás instalarlo a través del Índice de Paquetes de Python. Ejecute el siguiente comando en la terminal:
pip install ironpdf
Escribir archivos PDF y manipular archivos PDF
Crear un nuevo PDF
IronPDF simplifica el proceso de crear nuevos archivos PDF y trabajar en PDFs existentes. Proporciona una interfaz directa para generar documentos, ya sea un PDF simple de una página o un documento más complejo con varios elementos como contraseñas de usuario. Esta funcionalidad es vital para tareas como la generación de informes, la creación de facturas, y mucho más.
from ironpdf import ChromePdfRenderer, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Basic HTML content for the PDF
html = """
<html>
<head>
<title>IronPDF for Python!</title>
<link rel='stylesheet' href='assets/style.css'>
</head>
<body>
<h1>It's IronPDF World!!</h1>
<a href="https://ironpdf.com/python/"><img src='assets/logo.png' /></a>
</body>
</html>
"""
# Create a PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html)
# Save the rendered PDF to a file
pdf.SaveAs("New PDF File.pdf")from ironpdf import ChromePdfRenderer, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Basic HTML content for the PDF
html = """
<html>
<head>
<title>IronPDF for Python!</title>
<link rel='stylesheet' href='assets/style.css'>
</head>
<body>
<h1>It's IronPDF World!!</h1>
<a href="https://ironpdf.com/python/"><img src='assets/logo.png' /></a>
</body>
</html>
"""
# Create a PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html)
# Save the rendered PDF to a file
pdf.SaveAs("New PDF File.pdf") Archivo de Salida
Archivo de Salida
Fusión de archivos PDF
IronPDF simplifica la tarea de combinar varios archivos PDF en uno solo. Esta característica es beneficiosa para agregar varios informes, ensamblar documentos escaneados u organizar información que pertenece junta. Por ejemplo, puede necesitar fusionar archivos PDF al crear un informe integral de múltiples fuentes o cuando tiene una serie de documentos que deben presentarse como un solo archivo.
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load existing PDF documents
pdfOne = PdfDocument("Report First.pdf")
pdfTwo = PdfDocument("Report Second.pdf")
# Merge the PDFs into a single document
merged = PdfDocument.Merge(pdfOne, pdfTwo)
# Save the merged PDF
merged.SaveAs("Merged.pdf")from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load existing PDF documents
pdfOne = PdfDocument("Report First.pdf")
pdfTwo = PdfDocument("Report Second.pdf")
# Merge the PDFs into a single document
merged = PdfDocument.Merge(pdfOne, pdfTwo)
# Save the merged PDF
merged.SaveAs("Merged.pdf")La capacidad de fusionar archivos PDF existentes en un nuevo archivo PDF también puede ser útil en campos como la ciencia de datos, donde un documento PDF consolidado podría servir como un conjunto de datos para entrenar un módulo de IA. IronPDF maneja esta tarea sin esfuerzo, manteniendo la integridad y el formato de cada página de los documentos originales, resultando en un archivo de salida PDF fluido y coherente.
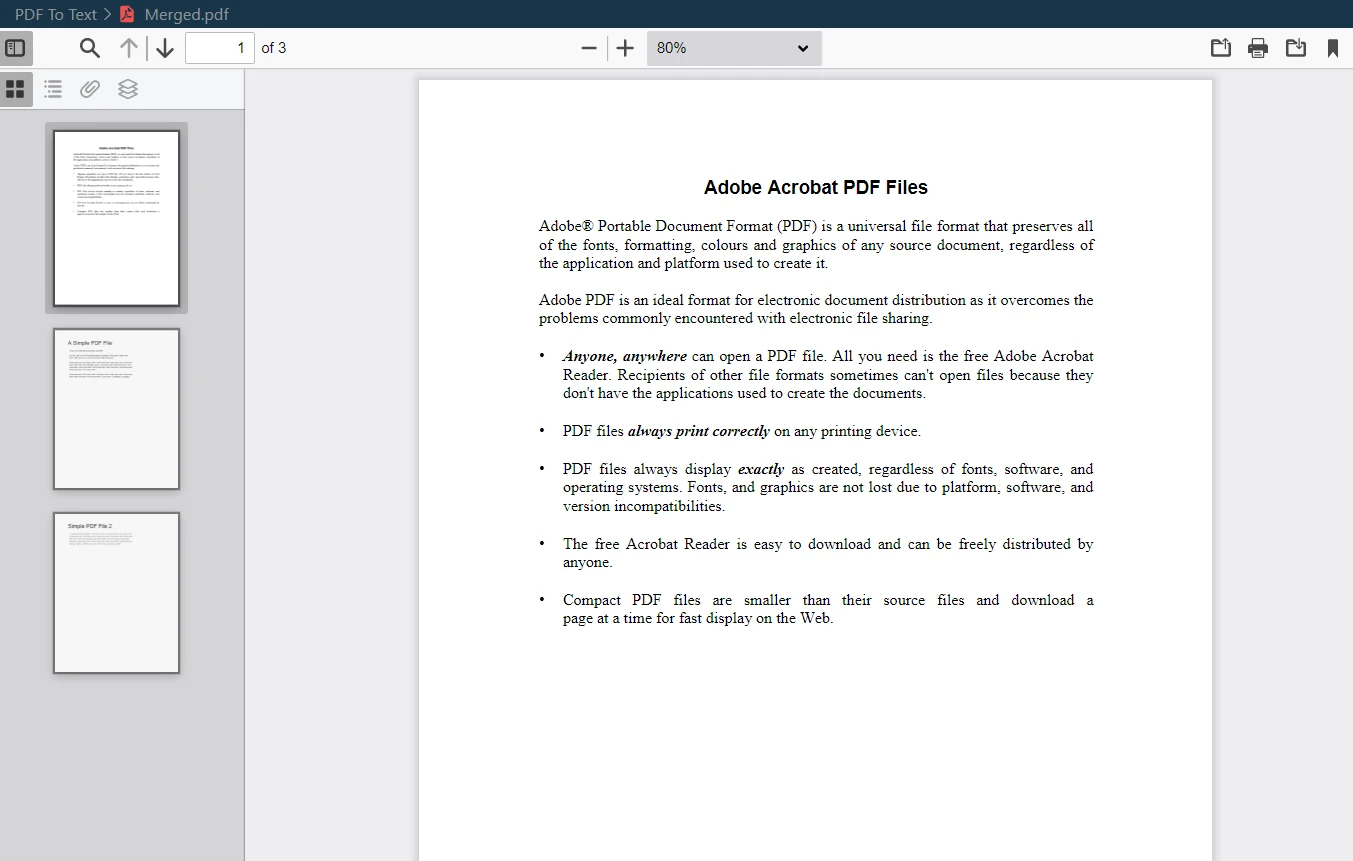 Salida de PDF Combinado
Salida de PDF Combinado
Dividir un solo PDF
Por otro lado, IronPDF también sobresale al dividir un archivo PDF existente en múltiples archivos nuevos. Esta función es útil cuando necesita extraer secciones específicas de un documento PDF sustancial o cuando divide un documento en partes más pequeñas y manejables.
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract the first page
page1doc = pdf.CopyPage(0)
# Save the extracted page as a new PDF
page1doc.SaveAs("Split1.pdf")from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract the first page
page1doc = pdf.CopyPage(0)
# Save the extracted page as a new PDF
page1doc.SaveAs("Split1.pdf")Por ejemplo, puede querer aislar ciertas páginas PDF de un informe grande o crear documentos individuales de diferentes capítulos de un libro. IronPDF le permite seleccionar las múltiples páginas deseadas para convertirlas en un nuevo archivo PDF, asegurando que pueda manipular y gestionar su contenido PDF según sea necesario.
 Salida de PDF Dividido
Salida de PDF Dividido
Implementación de funciones de seguridad
Asegurar sus documentos PDF se convierte en una prioridad principal cuando se trata de información sensible o confidencial. IronPDF aborda esta necesidad ofreciendo características de seguridad robustas, incluyendo protección por contraseña de usuario y encriptación. Esto asegura que sus archivos PDF permanezcan seguros y accesibles solo para usuarios autorizados.
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Adjust security settings to make the PDF read-only and set permissions
pdf.SecuritySettings.RemovePasswordsAndEncryption()
pdf.SecuritySettings.MakePdfDocumentReadOnly("secret-key")
pdf.SecuritySettings.AllowUserAnnotations = False
pdf.SecuritySettings.AllowUserCopyPasteContent = False
pdf.SecuritySettings.AllowUserFormData = False
pdf.SecuritySettings.AllowUserPrinting = PdfPrintSecurity.FullPrintRights
# Set the document encryption passwords
pdf.SecuritySettings.OwnerPassword = "top-secret" # password to edit the PDF
pdf.SecuritySettings.UserPassword = "sharable" # password to open the PDF
# Save the secured PDF
pdf.SaveAs("secured.pdf")from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Adjust security settings to make the PDF read-only and set permissions
pdf.SecuritySettings.RemovePasswordsAndEncryption()
pdf.SecuritySettings.MakePdfDocumentReadOnly("secret-key")
pdf.SecuritySettings.AllowUserAnnotations = False
pdf.SecuritySettings.AllowUserCopyPasteContent = False
pdf.SecuritySettings.AllowUserFormData = False
pdf.SecuritySettings.AllowUserPrinting = PdfPrintSecurity.FullPrintRights
# Set the document encryption passwords
pdf.SecuritySettings.OwnerPassword = "top-secret" # password to edit the PDF
pdf.SecuritySettings.UserPassword = "sharable" # password to open the PDF
# Save the secured PDF
pdf.SaveAs("secured.pdf")Al implementar contraseñas de usuario, puede controlar quién puede ver o editar sus documentos PDF. Las opciones de encriptación añaden una capa adicional de seguridad, protegiendo sus datos contra accesos no autorizados y haciendo de IronPDF una opción confiable para gestionar información sensible en formato PDF.
Extracción de texto de PDF
Otra característica crítica de IronPDF es su capacidad para extraer texto de documentos PDF. Esta funcionalidad es particularmente útil para la recuperación de datos, análisis de contenido, o incluso para reutilizar el contenido de texto de PDFs existentes en nuevos documentos.
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract all text from the PDF document
allText = pdf.ExtractAllText()
# Extract text from a specific page in the document
specificPage = pdf.ExtractTextFromPage(3)from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract all text from the PDF document
allText = pdf.ExtractAllText()
# Extract text from a specific page in the document
specificPage = pdf.ExtractTextFromPage(3)Ya sea que esté extrayendo datos para análisis, buscando información específica dentro de un documento grande, o transfiriendo contenido de PDF a archivos de texto para un procesamiento posterior, IronPDF lo hace sencillo y eficiente. La biblioteca asegura que el texto extraído mantenga su formato y estructura original, haciéndolo inmediatamente utilizable para sus necesidades específicas.
Gestión de la información del documento
La gestión eficiente de PDFs se extiende más allá de su contenido. IronPDF permite la gestión efectiva de metadatos y propiedades de documentos como el nombre del autor, el título del documento, la fecha de creación, y más. Esta capacidad es vital para organizar y catalogar sus documentos PDF, particularmente en entornos donde la procedencia del documento y los metadatos son importantes.
from ironpdf import PdfDocument, License, Logger
from datetime import datetime
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF or create a new one
pdf = PdfDocument("Report.pdf")
# Edit file metadata
pdf.MetaData.Author = "Satoshi Nakamoto"
pdf.MetaData.Keywords = "SEO, Friendly"
pdf.MetaData.ModifiedDate = datetime.now()
# Save the PDF with updated metadata
pdf.SaveAs("MetaData Updated.pdf")from ironpdf import PdfDocument, License, Logger
from datetime import datetime
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF or create a new one
pdf = PdfDocument("Report.pdf")
# Edit file metadata
pdf.MetaData.Author = "Satoshi Nakamoto"
pdf.MetaData.Keywords = "SEO, Friendly"
pdf.MetaData.ModifiedDate = datetime.now()
# Save the PDF with updated metadata
pdf.SaveAs("MetaData Updated.pdf")Por ejemplo, en un entorno académico o corporativo, poder rastrear la fecha de creación y la autoría de los documentos puede ser esencial para los propósitos de mantenimiento de registros y recuperación de documentos. IronPDF facilita la gestión de esta información, proporcionando una manera simplificada de manejar y actualizar la información del documento dentro de sus aplicaciones de Python.
Conclusión
 Licencia
Licencia
Este tutorial ha cubierto los conceptos básicos del uso de IronPDF en Python para la manipulación de PDFs. Desde crear nuevos archivos PDF hasta fusionar los existentes y añadir características de seguridad, IronPDF es una herramienta versátil para cualquier desarrollador de Python.
IronPDF for Python también ofrece las siguientes características:
- Crear un nuevo archivo PDF desde cero usando HTML o URL
- Editar archivos PDF existentes
- Rotar páginas PDF
- Extraer texto, metadatos e imágenes de archivos PDF
- Asegurar archivos PDF con contraseñas y restricciones
- Dividir y combinar PDFs
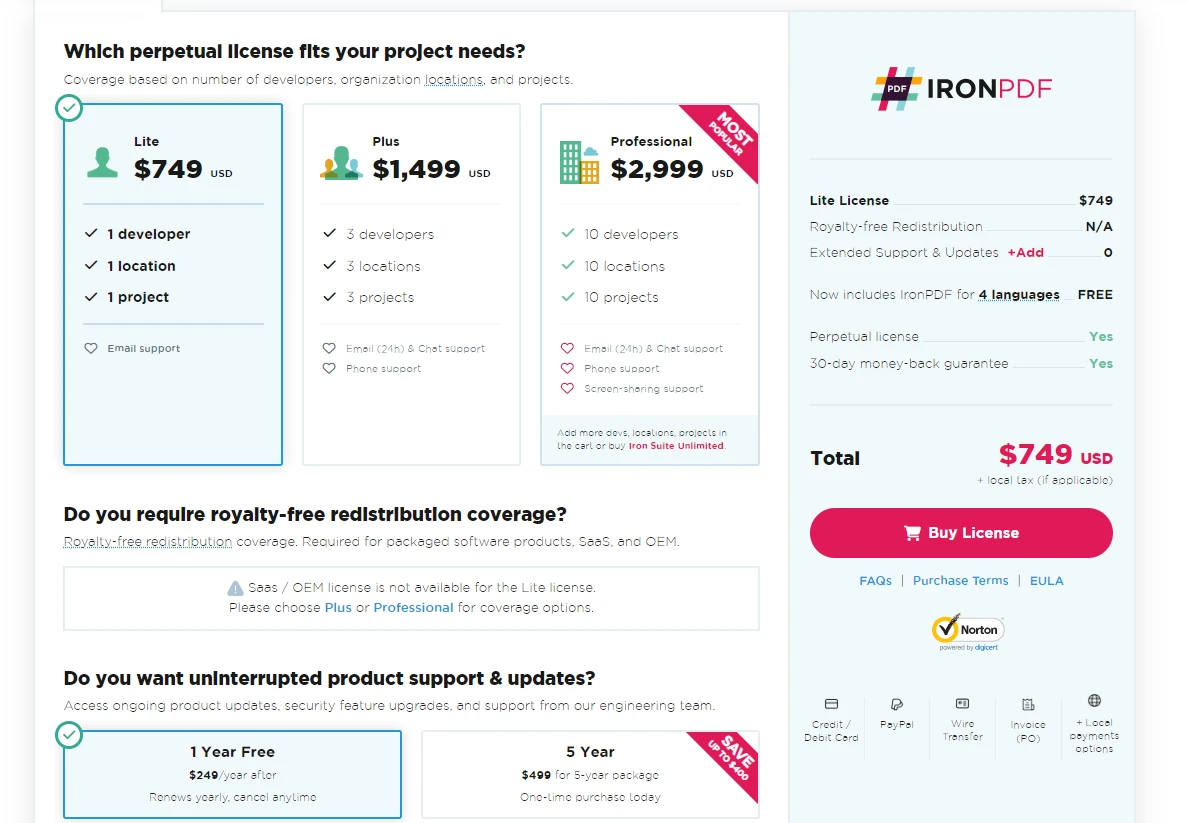
IronPDF for Python ofrece una prueba gratuita para que los usuarios exploren sus características. Para uso continuo más allá del período de prueba, las licencias comienzan en $799. Este precio permite a los desarrolladores utilizar todo el rango de capacidades de IronPDF en sus proyectos.
Preguntas Frecuentes
¿Cómo puedo crear un archivo PDF en Python?
Puedes usar el método CreatePdf de IronPDF para generar nuevos archivos PDF. Este método te permite crear documentos PDF personalizados desde cero usando Python.
¿Cuáles son los pasos para instalar IronPDF for Python?
Para instalar IronPDF for Python, puedes usar el Índice de Paquetes de Python ejecutando el comando: pip install ironpdf.
¿Cómo fusiono varios PDFs en uno usando Python?
IronPDF ofrece funcionalidades para fusionar varios archivos PDF. Puedes usar el método MergePdfFiles para combinar varios PDFs en un solo documento.
¿Puedo dividir un PDF en páginas separadas con IronPDF?
Sí, IronPDF proporciona la función SplitPdf, que te permite dividir un PDF en páginas individuales o secciones, creando archivos separados para cada parte.
¿Qué características de seguridad soporta IronPDF para PDFs?
IronPDF soporta varias características de seguridad, incluyendo protección con contraseña y encriptación, para asegurar que tus archivos PDF sean seguros y accesibles solo para usuarios autorizados.
¿Cómo puedo extraer texto de un documento PDF en Python?
Con IronPDF, puedes extraer fácilmente texto de documentos PDF usando el método ExtractText, lo cual es útil para la recuperación y análisis de datos.
¿Cuáles son las características clave de manipulación de PDF proporcionadas por IronPDF?
IronPDF te permite crear, fusionar y dividir PDFs, aplicar medidas de seguridad, extraer texto, y gestionar metadatos del documento como el nombre del autor y la fecha de creación.
¿Hay una prueba gratuita para IronPDF, y cómo puedo acceder a ella?
Sí, IronPDF ofrece una prueba gratuita. Puedes explorar sus características durante el periodo de prueba, y las licencias están disponibles para compra para continuar su uso después de que termine la prueba.
¿Cuáles son algunos casos de uso prácticos para IronPDF en proyectos de Python?
IronPDF es ideal para generar reportes, crear facturas, asegurar documentos, y gestionar metadatos de PDF en varios proyectos de Python.
¿Cómo puedo gestionar metadatos de PDF usando IronPDF?
IronPDF te permite gestionar metadatos de PDF, incluyendo nombres de autor, títulos de documentos, y fechas de creación, lo cual es crucial para la organización y catalogación de documentos.
















