
Comment lire un fichier PDF en Java
Cet article démontre comment les fichiers PDF sont lus en Java en utilisant la bibliothèque PDF pour le projet démo Java, nommé Vue d'ensemble de la bibliothèque Java IronPDF, pour lire le texte et les objets de type métadonnées dans les fichiers PDF ainsi que pour créer des documents chiffrés.
Étapes pour lire un fichier PDF en Java
- Installez la bibliothèque PDF pour lire les fichiers PDF en utilisant Java.
- Importer les dépendances pour utiliser le document PDF dans le projet.
- Charger un fichier PDF existant en utilisant la documentation de la méthode
PdfDocument.fromFile. - Extraire le texte du fichier PDF en utilisant la méthode d'extraction de texte PDF.
- Créez l'objet Metadata en utilisant la méthode de récupération de métadonnées PDF.
- Lire l'auteur à partir des métadonnées en utilisant la méthode guide de récupération de l'auteur dans les métadonnées [.](/java/object-reference/api/com/ironsoftware/ironpdf/metadata/MetadataManager.html#getAuthor()
Présentation de IronPDF for Java comme une bibliothèque de lecture de PDF
Pour rationaliser le processus de lecture des fichiers PDF en Java, les développeurs se tournent souvent vers des bibliothèques tierces qui offrent des solutions complètes et efficaces. Une telle bibliothèque remarquable est IronPDF for Java.
IronPDF est conçu pour être convivial pour les développeurs, offrant une API simple qui abstrait les complexités de la manipulation des pages PDF. Avec IronPDF, les développeurs Java peuvent intégrer facilement des capacités de lecture de PDF dans leurs projets, réduisant le temps et l'effort de développement. Cette bibliothèque prend en charge un large éventail de fonctionnalités PDF, en faisant un choix polyvalent pour diverses utilisations.
Les principales caractéristiques incluent la possibilité de créer un fichier PDF à partir de différents formats incluant HTML, JavaScript, CSS, documents XML, et divers formats d'image. En outre, IronPDF offre la possibilité d'ajouter des en-têtes et pieds de page aux PDF, créer des tableaux dans les documents PDF, et bien plus encore.
Installation d'IronPDF for Java
Pour installer IronPDF, assurez-vous d'avoir un compilateur Java fiable. Cet article recommande d'utiliser IntelliJ IDEA.
- Lancez IntelliJ IDEA et initiez un nouveau projet Maven.
-
Une fois le projet établi, accédez au fichier
pom.xml. Insérez les dépendances Maven suivantes pour intégrer IronPDF:<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>YOUR_VERSION_HERE</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>YOUR_VERSION_HERE</version> </dependency>XML - Après avoir ajouté ces dépendances, cliquez sur le petit bouton qui apparaît sur le côté droit de l'écran pour les installer.
Lire des fichiers PDF dans un exemple de code Java
Explorons un exemple de code Java simple qui montre comment utiliser IronPDF pour lire le contenu d'un fichier PDF. Dans cet exemple, concentrons-nous sur la méthode d'extraction de texte d'un document PDF.
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument pdf = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Extracting all text content from the PDF document
String text = pdf.extractAllText();
// Printing the extracted text to the console
System.out.println(text);
}
}// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument pdf = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Extracting all text content from the PDF document
String text = pdf.extractAllText();
// Printing the extracted text to the console
System.out.println(text);
}
}Ce code Java utilise la bibliothèque IronPDF pour extraire du texte d'un fichier PDF spécifié. Il importera la bibliothèque Java ainsi que définira la clé de licence, une condition préalable pour utiliser la bibliothèque. Le code charge ensuite un document PDF à partir du fichier "html_file_saved.pdf" et extrait tout son contenu textuel du fichier en tant que tampon de chaîne interne. Le texte extrait est stocké dans une variable et imprimé par la suite sur la console.
Image de sortie de la console
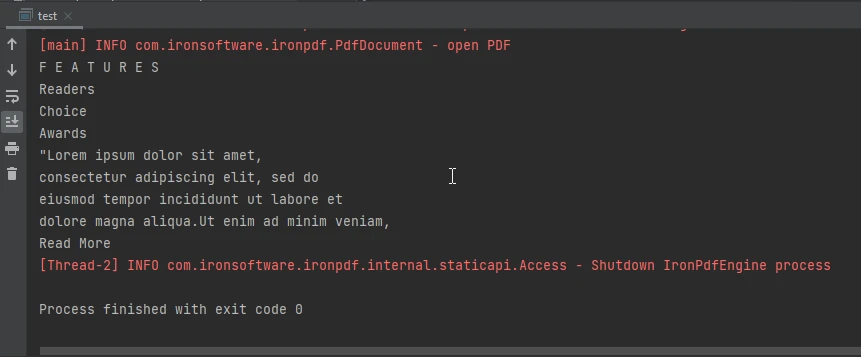 La sortie de la console
La sortie de la console
Lire les métadonnées d'un fichier PDF dans un exemple de code Java
En étendant ses capacités au-delà de l'extraction de texte, IronPDF offre également le support pour l'extraction de métadonnées à partir des fichiers PDF. Pour illustrer cette fonctionnalité, explorons un exemple de code Java qui montre le processus de récupération des métadonnées d'un document PDF.
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import com.ironsoftware.ironpdf.metadata.MetadataManager;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument document = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Creating a MetadataManager object to access document metadata
MetadataManager metadata = document.getMetadata();
// Extracting the author information from the document metadata
String author = metadata.getAuthor();
// Printing the extracted author information to the console
System.out.println(author);
}
}// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import com.ironsoftware.ironpdf.metadata.MetadataManager;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument document = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Creating a MetadataManager object to access document metadata
MetadataManager metadata = document.getMetadata();
// Extracting the author information from the document metadata
String author = metadata.getAuthor();
// Printing the extracted author information to the console
System.out.println(author);
}
}Ce code Java utilise la bibliothèque IronPDF pour extraire des métadonnées, en particulier les informations de l'auteur, d'un document PDF. Il commence par charger un document PDF à partir du fichier "html_file_saved.pdf". Le code récupère les métadonnées du document en utilisant la documentation de la classe MetadataManager, en récupérant spécifiquement les informations de l'auteur. Les détails de l'auteur extraits sont stockés dans une variable et imprimés sur la console.
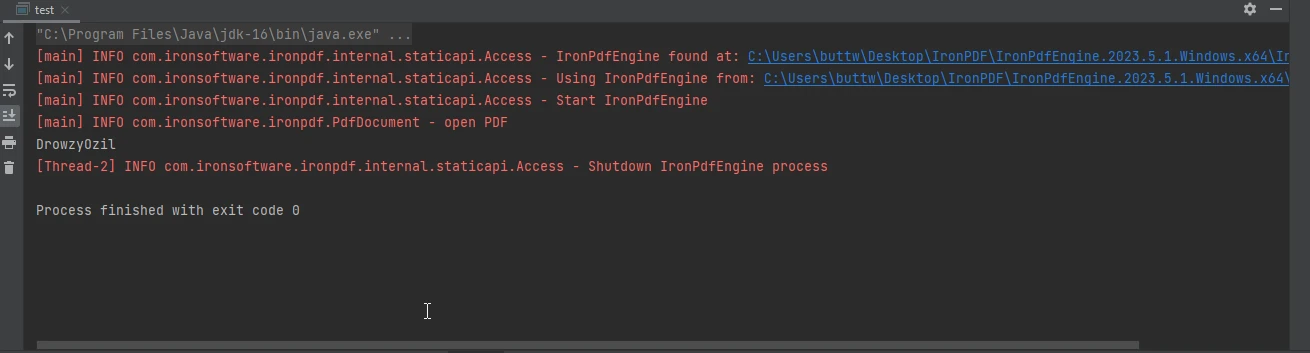 La sortie de la console
La sortie de la console
Conclusion
En conclusion, lire un document PDF existant dans un programme Java est une compétence précieuse qui ouvre un monde de possibilités aux développeurs. Que ce soit pour extraire du texte, des images ou d'autres données, la capacité à manipuler des PDF par programmation est un aspect crucial de nombreuses applications. IronPDF for Java sert de solution robuste et efficace pour les développeurs cherchant à intégrer des capacités de lecture de PDF dans leurs projets Java.
En suivant les étapes d'installation et en explorant les exemples de code fournis, les développeurs peuvent rapidement tirer parti de la puissance d'IronPDF pour créer de nouveaux fichiers et gérer les tâches liées aux PDF avec facilité. En plus de cela, on peut également explorer davantage ses capacités pour créer des documents chiffrés.
Le portail produit IronPDF offre un support étendu pour ses développeurs. Pour en savoir plus sur le fonctionnement d'IronPDF for Java, visitez ces pages de documentation complètes. De plus, IronPDF propose une page d'offre de licence d'essai gratuite qui est une excellente opportunité pour explorer IronPDF et ses fonctionnalités.
Questions Fréquemment Posées
Comment puis-je lire du texte à partir d'un fichier PDF en Java ?
Vous pouvez lire du texte à partir d'un fichier PDF en Java en using IronPDF en chargeant le PDF avec la méthode PdfDocument.fromFile puis en extrayant le texte avec la méthode extractAllText.
Comment puis-je extraire des métadonnées d'un PDF en Java ?
Pour extraire des métadonnées d'un PDF en Java en using IronPDF, chargez le document PDF et utilisez la méthode getMetadata. Cela vous permet de récupérer des informations telles que le nom de l'auteur et d'autres propriétés de métadonnées.
Quelles sont les étapes pour installer une bibliothèque PDF dans un projet Java ?
Pour installer IronPDF dans un projet Java, créez un projet Maven dans IntelliJ IDEA et ajoutez IronPDF comme dépendance dans le fichier pom.xml. Ensuite, installez les dépendances en utilisant les options fournies dans IntelliJ.
Puis-je créer des documents PDF chiffrés en Java ?
Bien que cet article se concentre sur la lecture de PDFs, IronPDF prend également en charge la création de documents PDF chiffrés. Pour des instructions détaillées, référez-vous à la documentation d'IronPDF.
Quelle est la raison d'implémenter une clé de licence pour une bibliothèque PDF Java ?
Définir une clé de licence dans IronPDF est nécessaire pour accéder aux fonctionnalités complètes de la bibliothèque. Vous la définissez dans votre code Java en utilisant License.setLicenseKey pour supprimer les limitations d'essai.
Quelles fonctionnalités une bibliothèque PDF Java offre-t-elle ?
IronPDF offre des fonctionnalités telles que la création de PDFs à partir de HTML, d'images, l'ajout d'en-têtes et pieds de page, la création de tableaux, et l'extraction de texte et métadonnées à partir de fichiers PDF.
Comment puis-je résoudre les problèmes courants lors de la lecture de PDFs en Java ?
Assurez-vous que vos dépendances Maven soient correctement configurées dans le fichier pom.xml et que la bibliothèque IronPDF soit correctement installée. Référez-vous à la documentation d'IronPDF pour des étapes détaillées de dépannage.
Où puis-je en apprendre davantage sur l'utilisation d'une bibliothèque PDF en Java ?
Pour plus d'information sur IronPDF for Java, visitez le portail produit IronPDF et explorez leur documentation. Ils fournissent également une licence d'essai gratuite pour tester ses capacités.
















