
Comment créer un lecteur PDF en Java
Cet article explorera comment vous pouvez lire des fichiers PDF en utilisant IronPDF pour Java.
Comment créer un lecteur PDF en Java
- Installez la bibliothèque Java pour créer un lecteur PDF en Java.
- Utilisez la méthode
Scanner(System.in)pour obtenir le chemin d'entrée de l'utilisateur. - Utilisez la méthode
PdfDocument.fromFilepour ouvrir les fichiers PDF à partir du chemin. - Lire le texte d'un fichier PDF en utilisant [
extractAllText](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText() ). - Imprimez le texte dans la console pour le lire.
IronPDF for Java
IronPDF, une bibliothèque robuste et polyvalente conçue pour simplifier les tâches liées aux PDF dans les applications Java, permet aux développeurs de générer, manipuler et interagir avec les fichiers PDF sans effort. De la génération de rapports automatisée à la création de formulaires interactifs, IronPDF offre un ensemble complet de fonctionnalités pour la gestion des documents PDF. IronPDF permet aux développeurs d'écrire dans des fichiers PDF, de créer un nouveau fichier PDF, d'éditer des fichiers existants, et bien plus encore.
Sa facilité d'intégration avec les frameworks et bibliothèques Java populaires, couplée à une API riche, en fait un atout puissant pour les développeurs souhaitant relever efficacement les défis liés aux PDF. Cet article introductif explorera les concepts fondamentaux, l'architecture, et les nombreuses possibilités qu'IronPDF débloque, fournissant aux développeurs Java les connaissances pour exploiter tout son potentiel et simplifier la gestion de documents PDF dans leurs projets.
Fonctionnalités d'IronPDF
IronPDF for Java est une bibliothèque PDF puissante qui offre une large gamme de fonctionnalités pour aider les développeurs Java à travailler avec des documents PDF. Voici une liste de quelques fonctionnalités clés:
- Génération de PDF : Créez de nouveaux fichiers PDF à partir de zéro avec du texte, des images, un dictionnaire de pages, un nombre de pages et des graphiques.
- Conversion HTML en PDF : Convertissez du contenu HTML en format PDF, en préservant les styles et la mise en page.
- Édition de PDF : Modifiez des PDF existants en ajoutant ou supprimant du contenu, des annotations, des pages tournées et des champs de formulaire.
- Fusion et fractionnement de PDF : Combinez plusieurs documents PDF en un seul fichier ou divisez un fichier PDF en pages ou documents séparés en fonction du numéro de page et du nombre de pages dans le fichier.
- Extraction de texte : Extrayez le contenu textuel des PDF pour la recherche, l'analyse ou le traitement des données.
- Manipulation de pages : Réorganisez, tournez ou supprimez des pages dans un document PDF.
- Gestion des images : Ajoutez des images dans les PDF, extrayez des images ou convertissez des pages PDF en images (par exemple, PNG, JPEG).
- Génération de codes-barres : Créez des codes-barres dans des documents PDF pour diverses applications.
- Filigrane : Ajoutez des filigranes de texte ou d'image pour protéger et marquer votre fichier PDF.
- Signatures numériques : Appliquez des signatures numériques pour l'authentification et l'intégrité du document.
Installation d'IronPDF for Java
Pour installer IronPDF, vous avez d'abord besoin d'un bon compilateur Java. Dans l'article d'aujourd'hui, IntelliJ IDEA est recommandé.
Ouvrez IntelliJ IDEA et créez un nouveau projet Maven. Une fois le projet créé, ouvrez le fichier pom.xml et écrivez-y les dépendances Maven suivantes pour utiliser IronPDF.
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>your_version_here</version>
</dependency>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>your_version_here</version>
</dependency>Une fois ceux-ci ajoutés, cliquez sur le petit bouton qui apparaît sur le côté droit de l'écran pour installer ces dépendances.
 Le fichier pom.xml
Le fichier pom.xml
Créer un PDFReader pour lire des fichiers PDF
Cette section introduira un code source qui créera un lecteur PDF capable de lire des fichiers PDF en obtenant le chemin du fichier PDF de l'utilisateur, en extrayant le texte sous forme de chaîne de caractères et en l'imprimant dans la console pour que l'utilisateur puisse le lire et obtenir des informations utiles.
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
// Create Scanner for user input
Scanner scanner = new Scanner(System.in);
System.out.print("Enter the PDF file path: ");
String filePath = scanner.nextLine();
scanner.close();
try {
// Load PDF from file
PdfDocument pdf = PdfDocument.fromFile(Paths.get(filePath));
// Extract all text from the PDF
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println(text);
} catch (IOException e) {
System.err.println("An IOException occurred: " + e.getMessage());
} catch (PdfException e) {
System.err.println("A PdfException occurred: " + e.getMessage());
} catch (Exception e) {
System.err.println("An unexpected exception occurred: " + e.getMessage());
}
}
}import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
// Create Scanner for user input
Scanner scanner = new Scanner(System.in);
System.out.print("Enter the PDF file path: ");
String filePath = scanner.nextLine();
scanner.close();
try {
// Load PDF from file
PdfDocument pdf = PdfDocument.fromFile(Paths.get(filePath));
// Extract all text from the PDF
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println(text);
} catch (IOException e) {
System.err.println("An IOException occurred: " + e.getMessage());
} catch (PdfException e) {
System.err.println("A PdfException occurred: " + e.getMessage());
} catch (Exception e) {
System.err.println("An unexpected exception occurred: " + e.getMessage());
}
}
}Ce code Java est conçu pour extraire le contenu textuel d'un fichier PDF spécifié par l'utilisateur. Il commence par importer les bibliothèques nécessaires, notamment com.ironsoftware.ironpdf.* pour le traitement PDF et java.util.Scanner pour la saisie utilisateur. À l'intérieur de la fonction main, elle initialise un Scanner pour capturer l'entrée utilisateur de la console. L'utilisateur est invité à entrer le chemin du fichier PDF qu'il souhaite traiter.
Une fois que l'utilisateur a fourni le chemin du fichier, le code le lit, crée un objet PdfDocument en utilisant la bibliothèque IronPDF , puis extrait tout le contenu textuel du fichier PDF spécifié.
PDFReader Lire un fichier PDF Exemple 1
Exécutez le programme Java, et il demandera le chemin du fichier PDF. Entrez le chemin du fichier PDF et appuyez sur Entrée.
 Le fichier principal
Le fichier principal
Il ouvrira le fichier PDF situé au chemin indiqué, en extraira le texte et l'imprimera dans la console. Ci-dessous l'image de sortie.
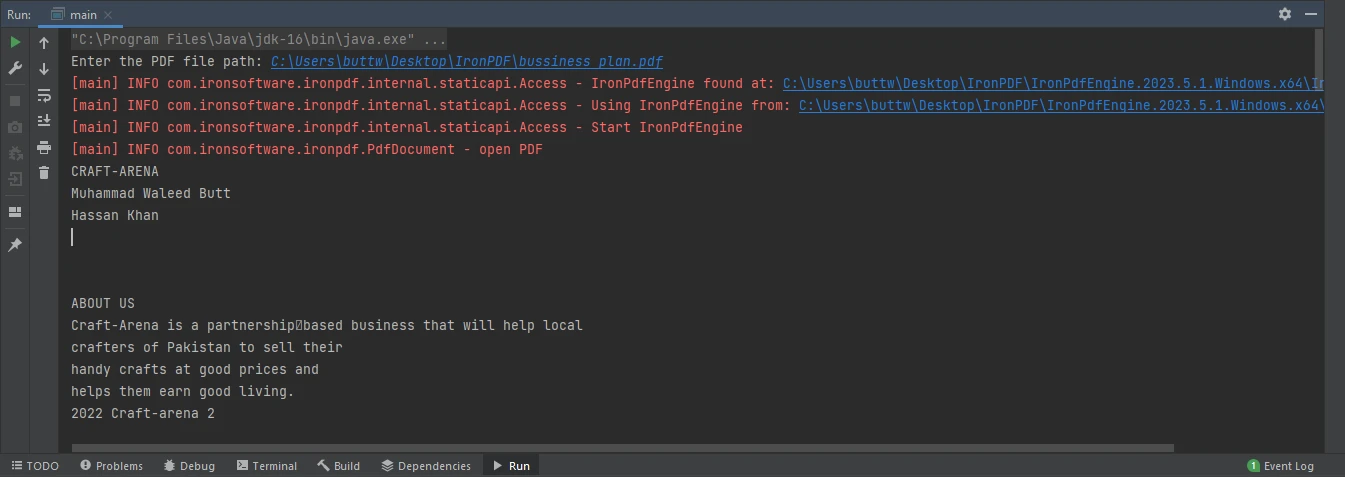 Contenu de la console
Contenu de la console
PDFReader Lire un document PDF Exemple 2
Relancez le programme Java et entrez un nouveau fichier avec un autre chemin de fichier PDF.
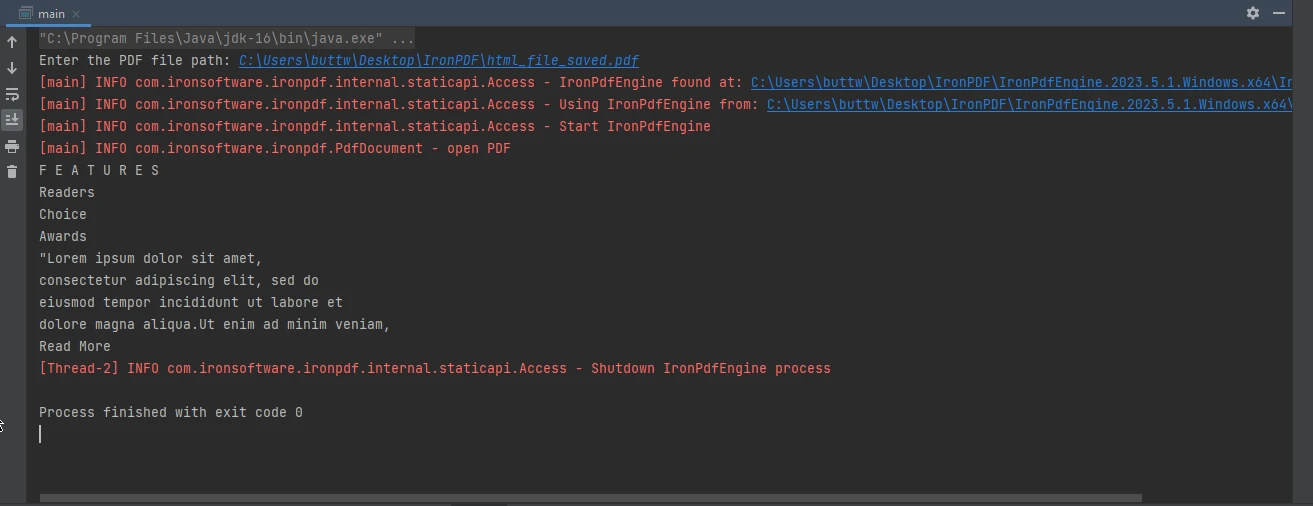 La console de l'exemple 2
La console de l'exemple 2
Conclusion
Cet article a fourni une introduction à IronPDF for Java, y compris des instructions pour l'installation et un exemple pratique de création d'un lecteur PDF pour extraire du texte des fichiers PDF de manière interactive. Avec les connaissances et outils fournis dans ce guide, les développeurs Java peuvent tirer pleinement parti de IronPDF et simplifier leurs tâches liées aux PDF dans leurs projets, que ce soit pour générer des rapports, traiter des données ou créer des formulaires interactifs.
L'article complet sur comment lire un fichier PDF peut être trouvé dans ce blog détaillé. L'exemple de code sur comment lire un fichier PDF en Java est disponible sur cette page d'exemple.
Inscrivez-vous dès aujourd'hui à la version d'essai d'IronPDF pour commencer à explorer toutes ses fonctionnalités, et voyez comment IronPDF peut aider à améliorer vos tâches liées aux PDF. Si vous trouvez qu'IronPDF est bénéfique à votre environnement de travail, assurez-vous d'acheter une licence.
Questions Fréquemment Posées
Comment puis-je installer une bibliothèque PDF dans mon projet Java ?
Pour installer une bibliothèque PDF comme IronPDF dans votre projet Java, créez un nouveau projet Maven dans IntelliJ IDEA et ajoutez la dépendance Maven IronPDF à votre fichier pom.xml, puis installez les dépendances.
Comment lire un fichier PDF en Java ?
Vous pouvez lire un fichier PDF en Java en utilisant la méthode PdfDocument.fromFile d'IronPDF pour ouvrir le fichier PDF et extractAllText pour récupérer le contenu textuel.
Quelles sont les principales fonctionnalités d'une bibliothèque PDF Java ?
Une bibliothèque PDF Java complète comme IronPDF offre des fonctionnalités telles que la génération de PDF, la conversion de HTML en PDF, l'édition de PDF, la fusion et la division, l'extraction de texte, la manipulation de pages, la gestion d'images, la génération de codes-barres, l'ajout de filigranes et les signatures numériques.
Comment puis-je convertir du HTML en PDF en Java ?
IronPDF vous permet de convertir du contenu HTML au format PDF en utilisant des méthodes qui préservent les styles et la mise en page originaux, garantissant un rendu précis.
Puis-je éditer des fichiers PDF existants en utilisant une bibliothèque Java ?
Oui, en utilisant une bibliothèque comme IronPDF, vous pouvez éditer des PDFs existants en ajoutant ou supprimant du contenu, des annotations, des pages tournées et des champs de formulaire.
Comment puis-je extraire du texte d'un PDF en utilisant Java ?
IronPDF fournit la méthode extractAllText, qui vous permet d'extraire le contenu textuel des PDFs à des fins de recherche, d'analyse ou de traitement de données.
Quelles étapes sont impliquées dans la création d'un lecteur PDF en utilisant Java ?
Pour créer un lecteur PDF en Java, installez la bibliothèque IronPDF, utilisez une méthode pour obtenir le chemin du PDF, puis appliquez PdfDocument.fromFile et extractAllText pour lire et imprimer le texte.
Une bibliothèque PDF Java prend-elle en charge les signatures numériques ?
Oui, IronPDF prend en charge l'application de signatures numériques aux documents PDF, garantissant l'authentification et l'intégrité des documents.
Pourquoi les développeurs Java devraient-ils utiliser une bibliothèque PDF ?
Utiliser une bibliothèque PDF comme IronPDF simplifie la gestion des documents PDF, s'intègre facilement aux frameworks Java et fournit une API riche pour résoudre efficacement les défis liés aux PDF.
Quels sont les scénarios courants de dépannage lors de l'utilisation d'une bibliothèque PDF en Java ?
Les problèmes courants incluent les conflits de dépendances dans Maven, les chemins de fichiers incorrects et la gestion des permissions PDF. Assurer une bonne configuration et consulter la documentation de la bibliothèque peuvent aider à résoudre ces problèmes.
















