
如何在 Java 中创建一个 PDF 阅读器
本文将探讨如何使用 IronPDF for Java读取PDF文件。
如何在Java中创建一个PDF阅读器
- 安装用于在Java中创建PDF阅读器的Java库。
- 利用
Scanner(System.in)方法从用户获取输入路径。 - 使用
PdfDocument.fromFile方法从路径打开 PDF 文件。 - 使用[
extractAllText](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText()从 PDF 文件中读取文本)。 - 在控制台中打印文本以进行阅读。
IronPDF for Java
为了让开发人员能够无缝生成、操作和交互PDF文件,IronPDF是一个强大且多功能的库,旨在简化Java应用程序中的PDF相关任务。 从自动报告生成到交互表单创建,IronPDF提供了PDF文档处理的全面功能。 IronPDF允许开发人员写入PDF文件,创建新的PDF文件,编辑现有文件,等等。
它与流行的Java框架和库的易于集成,加上丰富的API,使其成为寻求有效解决PDF相关挑战的开发人员的强大资产。 这篇介绍性文章将探讨IronPDF解锁的基本概念、架构和众多可能性,为Java开发人员提供利用其全部潜力的知识,并简化其项目中的PDF文档管理。
IronPDF 功能
IronPDF for Java是一个功能强大的PDF库,提供了广泛的功能,以帮助Java开发人员处理PDF文档。 这里列出了一些关键功能:
- PDF生成: 从头开始创建新的PDF文件,包含文本、图像、页面字典、页面数量和图形。
- HTML到PDF转换: 将HTML内容转换为PDF格式,保留样式和布局。
- PDF编辑: 通过添加或删除内容、注释、旋转页面和表单字段来修改现有PDF。
- PDF合并和拆分: 将多个PDF文档合并为一个文件,或根据文件中的页码和页数拆分PDF文件。
- 文本提取: 从PDF中提取文本内容以进行搜索、分析或数据处理。
- 页面操作: 重新排列、旋转或删除PDF文档中的页面。
- 图像处理: 向PDF中添加图像,提取图像,或将PDF页面转换为图像(例如PNG、JPEG)。
- 条形码生成: 在PDF文档中创建条形码以用于各种应用。
- 水印: 添加文本或图像水印以保护和标记您的PDF文件。
- 数字签名: 应用数字签名以进行文档认证和完整性。
安装 IronPDF for Java
要安装IronPDF,首先需要一个良好的Java编译器。 在今天的文章中,推荐使用IntelliJ IDEA 。
打开IntelliJ IDEA并创建一个新的Maven项目。 项目创建完成后,打开 pom.xml 文件,并在其中写入以下Maven依赖项以使用IronPDF。
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>your_version_here</version>
</dependency>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>your_version_here</version>
</dependency>添加这些后,点击屏幕右侧出现的小按钮以安装这些依赖项。
 pom.xml文件
pom.xml文件
创建PDFReader以读取PDF文件
本节将介绍源代码,该代码将创建一个PDF阅读器,可通过获取用户的PDF文件路径,将文本作为字符串值提取并打印在控制台,供用户阅读并从中获取有用信息。
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
// Create Scanner for user input
Scanner scanner = new Scanner(System.in);
System.out.print("Enter the PDF file path: ");
String filePath = scanner.nextLine();
scanner.close();
try {
// Load PDF from file
PdfDocument pdf = PdfDocument.fromFile(Paths.get(filePath));
// Extract all text from the PDF
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println(text);
} catch (IOException e) {
System.err.println("An IOException occurred: " + e.getMessage());
} catch (PdfException e) {
System.err.println("A PdfException occurred: " + e.getMessage());
} catch (Exception e) {
System.err.println("An unexpected exception occurred: " + e.getMessage());
}
}
}import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
// Create Scanner for user input
Scanner scanner = new Scanner(System.in);
System.out.print("Enter the PDF file path: ");
String filePath = scanner.nextLine();
scanner.close();
try {
// Load PDF from file
PdfDocument pdf = PdfDocument.fromFile(Paths.get(filePath));
// Extract all text from the PDF
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println(text);
} catch (IOException e) {
System.err.println("An IOException occurred: " + e.getMessage());
} catch (PdfException e) {
System.err.println("A PdfException occurred: " + e.getMessage());
} catch (Exception e) {
System.err.println("An unexpected exception occurred: " + e.getMessage());
}
}
}此Java代码旨在从用户指定的PDF文件中提取文本内容。 它首先导入必要的库,包括用于 PDF 处理的 com.ironsoftware.ironpdf.* 和用于用户输入的 java.util.Scanner。 在 main 函数内部,它初始化一个 Scanner 来捕获来自控制台的用户输入。 提示用户输入他们想处理的PDF文件的文件路径。
用户提供文件路径后,代码会读取该文件,使用IronPDF库创建一个PdfDocument对象,然后从指定的 PDF 文件中提取所有文本内容。
PDFReader读取PDF文件示例1
运行Java程序,它将询问PDF文件路径。 输入PDF文件路径并按下回车。
 主文件
主文件
它将打开位于路径的PDF文件,提取其文本,并在控制台打印。 下面是输出图像。
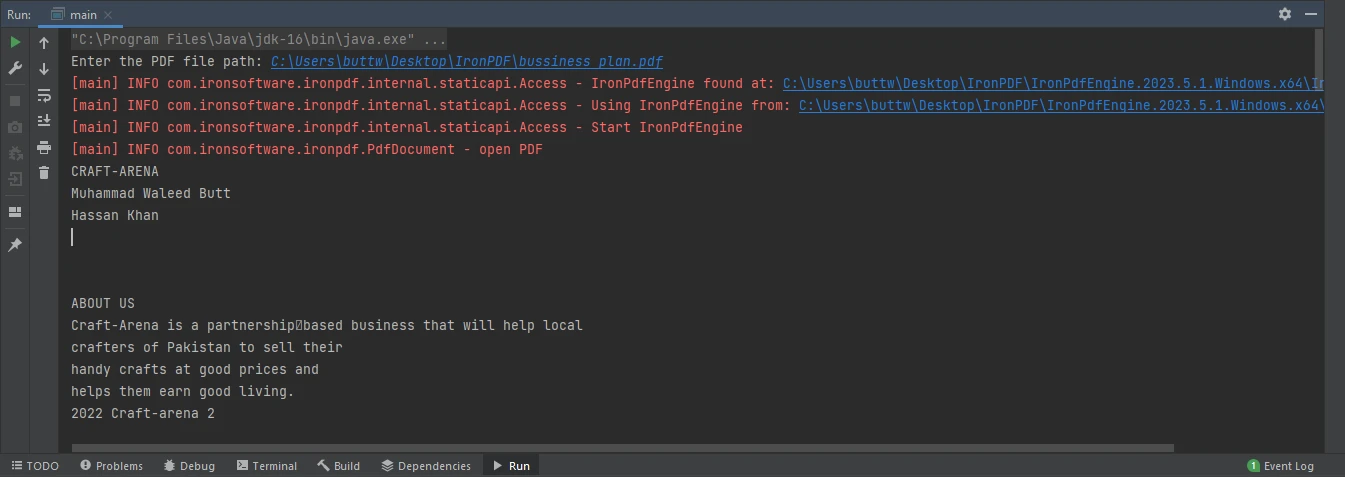 控制台内容
控制台内容
PDFReader读取PDF文档示例2
重新运行Java程序并输入另一个PDF文件的新路径。
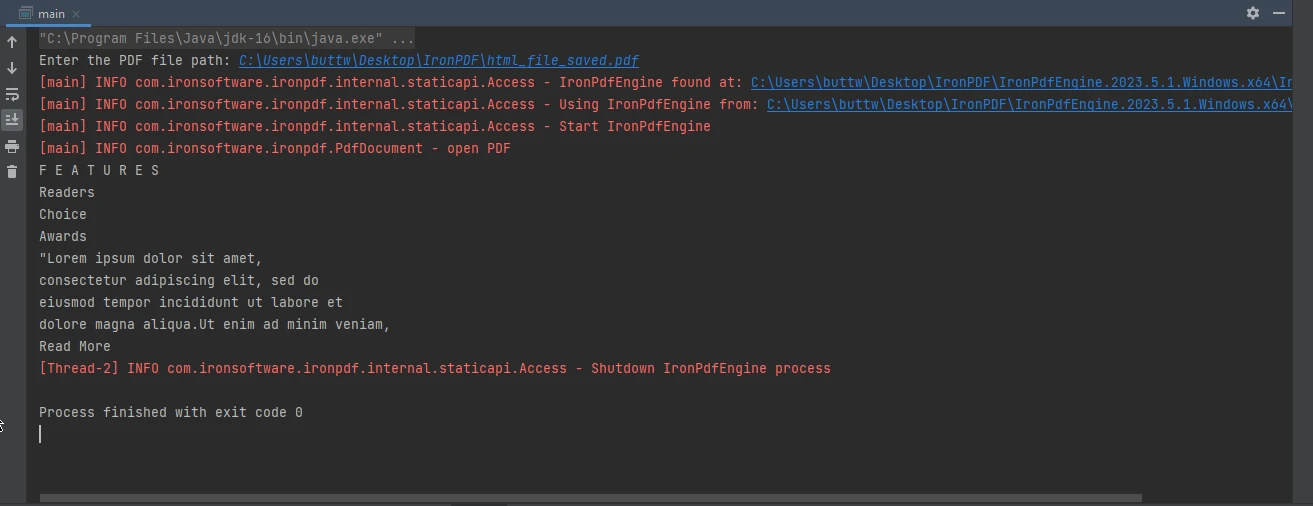 示例2中的控制台
示例2中的控制台
结论
本文介绍了IronPDF 适用于 Java,包括安装说明以及如何创建交互式PDF阅读器以从PDF文件中提取文本的实际示例。 通过本指南提供的知识和工具,Java开发人员可以充分利用IronPDF,简化他们项目中的PDF相关任务,无论是用于生成报告、处理数据还是创建交互式表单。
关于如何读取PDF文件的完整文章可以在这篇详细博客中找到。 有关如何在Java中读取PDF文件的代码示例可在此示例页面上找到。
今天就参与IronPDF的试用,开始探索它的所有功能,看看IronPDF如何帮助改善您的PDF相关任务。 如果您发现IronPDF对您的工作环境有益,请务必购买许可证。
常见问题解答
如何在我的Java项目中安装PDF库?
要在Java项目中安装类似IronPDF的PDF库,请在IntelliJ IDEA中创建一个新的Maven项目,并将IronPDF Maven依赖项添加到pom.xml文件中,然后安装依赖项。
如何在Java中读取PDF文件?
您可以通过使用IronPDF的PdfDocument.fromFile方法打开PDF文件,并使用extractAllText检索文本内容来读取PDF文件。
Java PDF库的主要功能是什么?
一个全面的Java PDF库,如IronPDF,提供的功能包括PDF生成、HTML到PDF转换、PDF编辑、合并和拆分、文本提取、页面操作、图像处理、条码生成、水印和数字签名。
如何在Java中将HTML转换为PDF?
IronPDF允许您使用保留原始样式和布局的方法将HTML内容转换为PDF格式,确保准确的渲染。
我可以使用Java库编辑现有的PDF文件吗?
是的,使用类似IronPDF的库,您可以通过添加或删除内容、注释、旋转页面和表单字段来编辑现有的PDF。
如何使用Java从PDF中提取文本?
IronPDF提供extractAllText方法,允许您从PDF中提取文本内容,以便于搜索、分析或数据处理。
使用Java创建PDF阅读器涉及哪些步骤?
要在Java中创建PDF阅读器,安装IronPDF库,使用方法获取PDF路径,然后应用PdfDocument.fromFile和extractAllText来读取和打印文本。
Java PDF库是否支持数字签名?
是的,IronPDF支持向PDF文档应用数字签名,以确保文档的认证和完整性。
为什么Java开发人员应该使用PDF库?
使用类似IronPDF的PDF库可以简化PDF文档管理,轻松集成到Java框架中,并提供丰富的API以有效解决PDF相关的挑战。
使用Java中的PDF库时有哪些常见的故障排除场景?
常见问题包括Maven中的依赖冲突、错误的文件路径和PDF权限处理。确保正确设置并查阅库的文档可以帮助解决这些问题。

















