
如何在 Java 中读取 PDF 文件
本文将演示如何在 Java 中使用 PDF 库读取 PDF 文件,用于演示名为IronPDF 适用于 Java 库概述的 Java 项目,以读取 PDF 文件中的文本和元数据类型对象以及创建加密文档。
在 Java 中读取 PDF 文件的步骤
- 安装 PDF 库以使用 Java 读取 PDF 文件。
- 导入依赖项以便在项目中使用 PDF 文档。
- 使用[
PdfDocument.fromFile方法文档](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#fromFile(java.nio.file.Path)加载现有 PDF 文件)。 - 使用[PDF 文本提取方法说明](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText())方法提取 PDF 文件中的文本。
- 使用[PDF 元数据检索教程](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#getMetadata())方法创建元数据对象。
- 使用[从元数据获取作者指南](/java/object-reference/api/com/ironsoftware/ironpdf/metadata/MetadataManager.html#getAuthor())方法从元数据读取作者信息。
介绍 IronPDF for Java 作为读取 PDF 库
为了简化 Java 中读取 PDF 文件的过程,开发人员通常会转向提供全面和高效解决方案的第三方库。 其中一个突出的库是 IronPDF for Java。
IronPDF 设计为开发者友好,提供了一个简单明了的 API,简化了 PDF 页面操作的复杂性。 利用 IronPDF,Java 开发人员可以将 PDF 阅读功能无缝集成到他们的项目中,减少开发时间和精力。 该库支持广泛的 PDF 功能,使其成为各种应用场景中的多功能选择。
主要功能包括能够从不同格式创建PDF文件,包括HTML、JavaScript、CSS、XML文档和各种图像格式。 此外,IronPDF 还提供了向 PDF 添加页眉和页脚、在 PDF 文档中创建表格等功能,远不止于此。
安装 IronPDF for Java
为了设置 IronPDF,请确保您有一个可靠的 Java 编译器。 本文推荐使用 IntelliJ IDEA。
- 启动IntelliJ IDEA并启动一个新的Maven项目。
-
项目创建完成后,访问
pom.xml文件。插入以下Maven依赖项以集成IronPDF:<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>YOUR_VERSION_HERE</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>YOUR_VERSION_HERE</version> </dependency>XML - 添加完这些依赖项后,单击屏幕右侧出现的小按钮安装它们。
在 Java 代码示例中读取 PDF 文件
我们来看一个简单的 Java 代码示例,演示如何使用 IronPDF 读取 PDF 文件的内容。在此示例中,我们将专注于从 PDF 文档中提取文本的方法。
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument pdf = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Extracting all text content from the PDF document
String text = pdf.extractAllText();
// Printing the extracted text to the console
System.out.println(text);
}
}// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument pdf = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Extracting all text content from the PDF document
String text = pdf.extractAllText();
// Printing the extracted text to the console
System.out.println(text);
}
}此 Java 代码利用 IronPDF 库从特定的 PDF 文件中提取文本。它将导入 Java 库并设置许可证密钥,这是使用该库的先决条件。 然后代码从文件"html_file_saved.pdf"加载 PDF 文档,并将其所有文本内容从文件中提取为内部字符串缓冲区。 提取的文本存储在一个变量中,并随后打印到控制台。
控制台输出图像
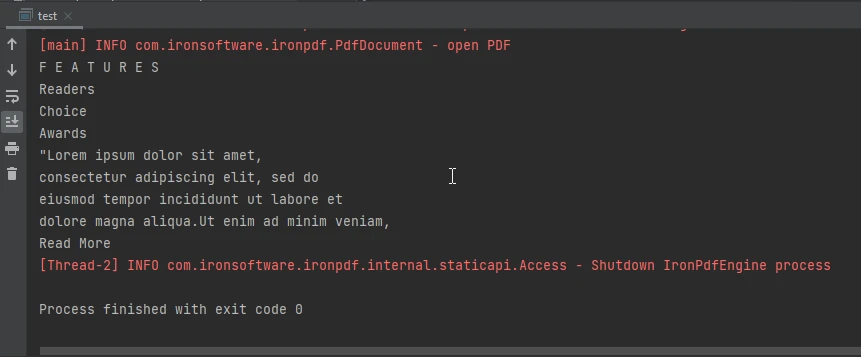 控制台输出
控制台输出
在 Java 代码示例中读取 PDF 文件的元数据
除了文本提取功能外,IronPDF 还支持从 PDF 文件中提取元数据。 为了说明这种功能,让我们深入研究一个 Java 代码示例,展示从 PDF 文档中检索元数据的过程。
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import com.ironsoftware.ironpdf.metadata.MetadataManager;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument document = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Creating a MetadataManager object to access document metadata
MetadataManager metadata = document.getMetadata();
// Extracting the author information from the document metadata
String author = metadata.getAuthor();
// Printing the extracted author information to the console
System.out.println(author);
}
}// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import com.ironsoftware.ironpdf.metadata.MetadataManager;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument document = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Creating a MetadataManager object to access document metadata
MetadataManager metadata = document.getMetadata();
// Extracting the author information from the document metadata
String author = metadata.getAuthor();
// Printing the extracted author information to the console
System.out.println(author);
}
}此 Java 代码利用 IronPDF 库从 PDF 文档中提取元数据,特别是作者信息。 它首先从文件"html_file_saved.pdf"加载一个 PDF 文档。代码使用MetadataManager 类文档检索文档的元数据,具体来说是获取作者信息。 提取的作者详细信息存储在一个变量中,并打印到控制台。
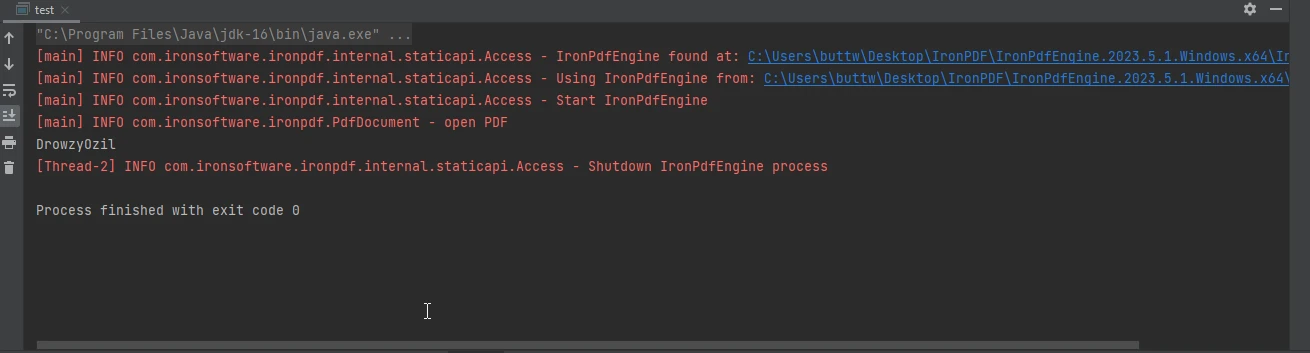 控制台输出
控制台输出
结论
总之,在 Java 程序中读取现有的 PDF 文档是一项宝贵的技能,为开发人员开启了无限可能。 无论是提取文本、图像还是其他数据,能够以编程方式操作 PDF 都是许多应用程序的一项重要功能。 IronPDF for Java 是开发人员寻求在其 Java 项目中集成 PDF 阅读功能的强大且高效的解决方案。
通过遵循安装步骤并探索提供的代码示例,开发人员可以快速利用 IronPDF 的强大功能来创建新文件并轻松处理与 PDF 相关的任务。 除此之外,还可以进一步探索其创建加密文档的功能。
IronPDF 产品门户为其开发人员提供广泛的支持。 要了解更多关于 IronPDF for Java 如何工作的信息,请访问这些全面的文档页面。 此外,IronPDF 提供了免费试用许可证优惠页面,这是探索 IronPDF 及其功能的绝佳机会。
常见问题解答
我如何在Java中读取PDF文件的文本?
您可以使用IronPDF在Java中读取PDF文件的文本,通过使用PdfDocument.fromFile方法加载PDF,然后使用extractAllText方法提取文本。
我如何在Java中提取PDF的元数据?
要在Java中使用IronPDF提取PDF的元数据,加载PDF文档并使用getMetadata方法。这使您可以获取作者名称和其他元数据属性。
在Java项目中安装PDF库的步骤是什么?
要在Java项目中安装IronPDF,请在IntelliJ IDEA中创建Maven项目,并在pom.xml文件中添加IronPDF作为依赖项。然后,使用IntelliJ中提供的选项安装依赖项。
我可以在Java中创建加密的PDF文档吗?
虽然这篇文章专注于读取PDF,但IronPDF确实支持创建加密的PDF文档。有关详细说明,请参阅IronPDF的文档。
为Java PDF库设置许可证密钥的目的是什么?
在IronPDF中设置许可证密钥是访问库全部功能的必要操作。您可以在Java代码中使用License.setLicenseKey在去除试用限制。
Java PDF库提供哪些功能?
IronPDF提供的功能包括从HTML创建PDF、图像、添加页眉和页脚、创建表格以及从PDF文件中提取文本和元数据。
如何解决在Java中读取PDF的常见问题?
确保您的Maven依赖项在pom.xml文件中正确设置,并且IronPDF库已正确安装。有关详细的故障排除步骤,请参阅IronPDF的文档。
我可以在哪里了解更多关于在Java中使用PDF库的信息?
有关IronPDF for Java的更多信息,请访问IronPDF产品门户并浏览他们的文档。他们还提供免费的试用许可证以测试其功能。

















